import numpy as np
import matplotlib.pyplot as plt 참고자료: 2022-04-mid
오픈 북, 2시간, 문제유형만 공개
2022년 파이썬 입문 중간고사 (풀이포함)
youtube: https://youtube.com/playlist?list=PLQqh36zP38-ylgm3-dn93yv2BCM7_8kFy
0. imports
아래코드를 이용하여 numpy 와 matplotlib을 import하라.
1. 코드구현 I (40점)
주의: 문제에 조건이 있는 경우 조건을 준수할 것
(1) a의 type을 bool로 바꾸어라.
a=1.0note: 출제의도: 자료형의 변환
(풀이)
bool(a)True(2)-(6)
아래의 문자열을 고려하자.
test_arr = 'ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAklOUpkDHrfHY17SbrmTIpNLTGK9Tjom/BWDSUGPl+nafzlHDTYW7hdI4yZ5ew18JH4JW9jbhUFrviQzM7xlELEVf4h9lFX5QVkbPppSwg0cda3Pbv7kOdJ/MTyBlWXFCR+HAo3FXRitBqxiX1nKhXpHAZsMciLq8V6RjsNAQwdsdMFvSlVK/7XAt3FaoJoAsncM1Q9x5+3V0Ww68/eIFmb1zuUFljQJKprrX88XypNDvjYNby6vw/Pb0rwert/EnmZ+AW4OZPnTPI89ZPmVMLuayrD2cE86Z/il8b+gw3r3+1nKatmIkjn2so1d01QraTlMqVSsbxNrRFi9wrf+M7Q== schacon@mylaptop.local'(2) 위 문자열에서 짝수번째 원소를 출력하는 코드를 작성하라.
note: 출제의도: 인덱싱, 스트라이딩
(풀이)
test_arr[1::2]'s-s AA3zCy2AABwAQAlUkHfY7bmINTKTo/WSGlnflDY7d4Ze1J4WjhFvQMxEEfhlXQkPpw0d3b7OJMylXC+A3XiBxXnhpAscL86jNQddFSV/XtFoosc19530w8eFbzUlQKrX8yNvYb6wP0wr/nZA4ZnP8ZmMuyDc8Zi8+wr+namkns10QalqSbNRiwfMQ=shcnmlpo.oa'(3) 위 문자열에서 마지막 10개의 원소를 출력하는 코드를 작성하라.
note: 출제의도: -인덱싱
(풀이)
test_arr[-10:]'ptop.local'(4) 위 문자열을 뒤집은 문자열을 구하는 코드를 작성하라. 즉 아래를 출력하는 코드를 작성하라.
'lacol.potpalym@nocahcs ==Q7M+frw9iFRrNxbsSVqMlTarQ10d1os2njkImtaKn1+3r3wg+b8li/Z68Ec2DryauLMVmPZ98IPTnPZO4WA+ZmnE/trewr0bP/wv6ybNYjvDNpyX88XrrpKJQjlFUuz1bmFIe/86wW0V3+5x9Q1McnsAoJoaF3tAX7/KVlSvFMdsdwQANsjR6V8qLicMsZAHpXhKn1XixqBtiRXF3oAH+RCFXWlByTM/JdOk7vbP3adc0gwSppPbkVQ5XFl9h4fVELElx7MzQivrFUhbj9WJ4HJ81we5Zy4Idh7WYTDHlzfan+lPGUSDWB/mojT9KGTLNpITmrbS71YHfrHDkpUOlkAEQAAAwIBAAAAE2cy1CazN3BAAAA asr-hss'note: 출제의도: -1 스트라이딩
(풀이)
test_arr[::-1]'lacol.potpalym@nocahcs ==Q7M+frw9iFRrNxbsSVqMlTarQ10d1os2njkImtaKn1+3r3wg+b8li/Z68Ec2DryauLMVmPZ98IPTnPZO4WA+ZmnE/trewr0bP/wv6ybNYjvDNpyX88XrrpKJQjlFUuz1bmFIe/86wW0V3+5x9Q1McnsAoJoaF3tAX7/KVlSvFMdsdwQANsjR6V8qLicMsZAHpXhKn1XixqBtiRXF3oAH+RCFXWlByTM/JdOk7vbP3adc0gwSppPbkVQ5XFl9h4fVELElx7MzQivrFUhbj9WJ4HJ81we5Zy4Idh7WYTDHlzfan+lPGUSDWB/mojT9KGTLNpITmrbS71YHfrHDkpUOlkAEQAAAwIBAAAAE2cy1CazN3BAAAA asr-hss'(5) 위 문자열에서 대문자의 수를 count하라.
hint .isupper() 메소드를 이용할 것.
'a'.isupper()False'A'.isupper()True'='.isupper()False'@'.isupper()Falsenote: 출제의도: 리스트컴프리헨션, bool자료형의 sum
(풀이)
sum([s.isupper() for s in test_arr])155(6) 위 문자열에서 사용된 문자 및 특수문자의 종류는 모두 몇가지 인가?
note1: 문자열 ‘AAB @ab’ 에서 사용된 문자는 ‘A’, ‘B’, ’ ‘,’@‘, ’a’, ‘b’ 이므로 모두 6종류의 문자 및 특수문자가 사용되었다.
note2: ’ ‘,’+‘,’-‘,’.’, ‘/’, ‘=’, ‘@’, ‘1’, ‘a’, ‘A’ 등을 모두 다른 문자로 취급한다.
note: 출제의도: set 자료형의 이해
(풀이)
len(set(test_arr))69(7) 리스트컴프리헨션을 이용하여 아래와 같은 리스트를 생성하라
['a',
'aa',
'aaa',
'aaaa',
'aaaaa',
'aaaaaa',
'aaaaaaa',
'aaaaaaaa',
'aaaaaaaaa',
'aaaaaaaaaa'] <- a가 10개있음 note: 출제의도: 문자열의
*연산, 리스트컴프리헨션
(풀이)
['a'*i for i in range(1,11)]['a',
'aa',
'aaa',
'aaaa',
'aaaaa',
'aaaaaa',
'aaaaaaa',
'aaaaaaaa',
'aaaaaaaaa',
'aaaaaaaaaa'](8) 길이가 1인 튜플을 만들어 자신의 학번을 저장하라. 길이가 1인 튜플을 만들어 자신의 영문이름을 저장하라. 두 튜플을 + 연산자로 합쳐아래와 같은 출력결과를 얻어라.
(202143052,'guebin')note: 출제의도: 튜플의
+연산, 길이가 1인 튜플
(풀이)
a=(202143052,)
b=('guebin',)
a+b(202143052, 'guebin')(9) 아래와 같은 list가 있다고 하자.
test_lst = [['g',1],['u',5],['e',2],['b',8],['i',2],['n',9]]test_lst와 리스트컴프리헨션을 이용하여 아래를 출력하는 코드를 구현하라.
['g', 'uuuuu', 'ee', 'bbbbbbbb', 'ii', 'nnnnnnnnn']note: 출제의도: 스트링의
+연산, 리스트 컴프리헨션
(풀이)
test_lst = [['g',1],['u',5],['e',2],['b',8],['i',2],['n',9]]
[i*j for i,j in test_lst]['g', 'uuuuu', 'ee', 'bbbbbbbb', 'ii', 'nnnnnnnnn'](10) 다음은 학생들의 출석,레포트,중간고사,기말고사 점수를 입력으로 하여 학점을 계산하는 함수이다.
def grade(attendance, report, mid, final):
if attendance<70:
credit = 'F'
else:
total_score = attendance * 0.1 + report * 0.2 + mid * 0.3 + final * 0.4
if total_score > 80:
credit = 'A+'
else:
credit = 'B0'
return credit 아래는 학생들의 학번, 출석점수, 레포트, 중간고사, 기말고사 점수가 입력된 리스트이다.
data = [['202212345', [100,95,25,90]],
['202212346', [60,90,95,95]],
['202212347', [50,90,45,35]],
['202212348', [90,90,50,75]],
['202212349', [100,95,85,85]],
['202212350', [90,90,100,95]],
['202212351', [100,95,100,95]],
['202212352', [95,85,80,60]],
['202212353', [100,90,60,55]],
['202212354', [100,85,70,95]],
['202212355', [100,95,40,100]]]아래의 ???를 적절하게 완성하여 학생들의 학점을 계산하는 코드를 완성하라.
[grade(???) for _, scores in data] note: 출제의도: dummy variable
_, 언패킹연산자*, for문과 튜플언패킹, 리스트컴프리헨션
(풀이)
[grade(*scores) for _, scores in data] ['B0', 'F', 'F', 'B0', 'A+', 'A+', 'A+', 'B0', 'B0', 'A+', 'A+'](11) 길이가 0인 문자열을 선언하라.
note: 출제의도: 길이가 0인 문자열
(풀이)
len('')0(12)-(15)
(12) dir(plt)와 dir(np)를 각각 실행하라. 실행결과를 각각 a,b로 저장하라. a,b의 type은 무엇인가?
note: 출제의도: type사용법
(풀이)
a=dir(plt)
b=dir(np)
type(a),type(b)(list, list)(13) a의 원소와 b의 원소의 수를 각각 구하라.
note: 출제의도: len의 사용법 및 응용
(풀이)
len(a),len(b)(254, 611)(14) a와 b의 공통원소의 수를 구하라.
note: 출제의도: set에서 & 연산자 이용
(풀이)
len(set(a)&set(b))9(15) a와 b의 원소를 합친 리스트를 만들어라. (공통원소는 중복하여 합치지 않는다)
note: 출제의도: set에서 | 연산자 이용
(풀이)
lst = list(set(a)|set(b))(16)-(18) 아래와 같은 dictionary가 있다.
test_dic = {'202212345': {'att':100,'rep':95,'mid':25,'fin':90},
'202212346': {'att':60,'rep':90,'mid':95,'fin':95},
'202212347': {'att':50,'rep':90,'mid':45,'fin':35},
'202212348': {'att':90,'rep':90,'mid':50,'fin':75},
'202212349': {'att':100,'rep':95,'mid':85,'fin':85},
'202212350': {'att':90,'rep':90,'mid':100,'fin':95},
'202212351': {'att':100,'rep':95,'mid':100,'fin':95},
'202212352': {'att':95,'rep':85,'mid':80,'fin':60},
'202212353': {'att':100,'rep':90,'mid':60,'fin':55},
'202212354': {'att':100,'rep':85,'mid':70,'fin':95},
'202212355': {'att':100,'rep':95,'mid':40,'fin':100}}여기에서 202212345등은 학번을, att는 출석점수, rep는 레포트점수, mid는 중간고사점수, fin은 기말고사 점수를 의미한다.
(16) get 메소드를 이용하여 202212353에 해당하는 학생의 성적을 아래와 같이 리턴하라.
{'att': 100, 'rep': 90, 'mid': 60, 'fin': 55}note: 출제의도: 딕셔너리에서 get 메소드 이용
(풀이)
test_dic.get('202212353'){'att': 100, 'rep': 90, 'mid': 60, 'fin': 55}(17) 202212354의 레포트 점수를 리턴하라.
note: 출제의도: 딕셔너리에서 key를 이용한 원소추출
(풀이)
test_dic['202212354']['rep']85(18) 학생들의 학번을 리턴하는 코드를 작성하라.
note: 출제의도: 딕셔너리와 for문
(풀이)
[k for k in test_dic]['202212345',
'202212346',
'202212347',
'202212348',
'202212349',
'202212350',
'202212351',
'202212352',
'202212353',
'202212354',
'202212355'](19) shape이 ()인 numpy이 array를 만들어라. (즉 차원이 0인 np.array를 만들어라)
note: 출제의도: 0차원인 numpy array
(풀이)
np.array(3).shape()(20) shape이 (2,2)인 단위행렬을 만들어라.
note: 출제의도: 넘파이에서의 배열선언
(풀이)
np.array([[1,0],[0,1]])array([[1, 0],
[0, 1]])(21) a의 모든 원소에 1을 더하는 코드를 작성하라.
a=[1,3,2,5,-3,3,8,2,3,1] note: 출제의도: 브로드캐스팅
(풀이)
np.array([1,3,2,5,-3,3,8,2,3,1])+1array([ 2, 4, 3, 6, -2, 4, 9, 3, 4, 2])(22) 아래와 같은 수열을 생성하라.
1,3,6,10,15,21,28,36,45, ... , 378, 406, 435hint: 이 수열에서 \(a_n-a_{n-1}=n, ~n\geq 2\) 이다. 즉 3-1=2, 6-3=3, 10-6=4, …
note: 출제의도: np.arange, cumsum
(풀이)
435-40629np.arange(1,30).cumsum()array([ 1, 3, 6, 10, 15, 21, 28, 36, 45, 55, 66, 78, 91,
105, 120, 136, 153, 171, 190, 210, 231, 253, 276, 300, 325, 351,
378, 406, 435])(23) 아래와 같은 수열을 생생성하라.
0,1,2,3,4,5,...,99 위의 수열에서 1,4,7,10,13,… 번째의 원소를 뽑아라. (첫번째 원소는 0이다)
note: 출제의도: np.arange, 스트라이딩
(풀이)
np.arange(100)[::3]array([ 0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36, 39, 42, 45, 48,
51, 54, 57, 60, 63, 66, 69, 72, 75, 78, 81, 84, 87, 90, 93, 96, 99])(24) numpy를 이용하여 아래의 역행렬을 구하라. \[\begin{bmatrix}
1& 0 \\
0& 3
\end{bmatrix}\]
note: 출제의도: np.linalg.inv
(풀이)
np.linalg.inv(np.array([[1,0],[0,3]]))array([[1. , 0. ],
[0. , 0.33333333]])(25)-(30)
a,b가 아래와 같이 주어졌다고 하자.
a=[1]*10
b=[2]*10 (25) a,b와 np.concatenate를 이용하여 아래와 같은 배열을 만들어라.
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])note: 출제의도: np.concatenate
(풀이)
np.concatenate([a,b])array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])(26) a,b와 np.concatenate를 이용하여 아래와 같은 배열을 만들어라.
array([[1],
[1],
[1],
[1],
[1],
[1],
[1],
[1],
[1],
[1],
[2],
[2],
[2],
[2],
[2],
[2],
[2],
[2],
[2],
[2]])note: 출제의도: np.concatenate
(풀이)
np.concatenate([np.array(a).reshape(-1,1),np.array(b).reshape(-1,1)])array([[1],
[1],
[1],
[1],
[1],
[1],
[1],
[1],
[1],
[1],
[2],
[2],
[2],
[2],
[2],
[2],
[2],
[2],
[2],
[2]])(27) a,b와 np.concatenate를 이용하여 아래와 같은 배열을 만들어라.
array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2]]note: 출제의도: np.concatenate
(풀이)
np.concatenate([np.array(a).reshape(1,-1),np.array(b).reshape(1,-1)])array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2]])(28) a,b와 np.concatenate를 이용하여 아래와 같은 배열을 만들어라.
array([[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2]])note: 출제의도: np.concatenate
(풀이)
np.concatenate([np.array(a).reshape(-1,1),np.array(b).reshape(-1,1)],axis=1)array([[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2]])(29) a,b와 np.stack을 이용하여 아래와 같은 배열을 만들어라.
array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2]](풀이)
np.stack([a,b])array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2]])note: 출제의도: np.stack
(30) a,b와 np.stack을 이용하여 아래와 같은 배열을 만들어라.
array([[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2]])note: 출제의도: np.stack
(풀이)
np.stack([a,b],axis=1)array([[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2]])(31) 아래와 같은 배열이 있다고 하자.
a=np.array([1,2,3,4,5])
b=np.array([3,2,1,1,2])numpy의 @ 연산자를 이용하여 \(\sum_{i=1}^{5}a_ib_i\)를 계산하라.
note: 출제의도: @연산자의 계산 및 해석
(풀이)
a@b24(32) 아래와 같은 배열을 생성하라.
x=np.random.randn(100)numpy의 @연산자를 이용하여 \(\sum_{i=1}^{100}x_i^2\)을 계산하라.
note: 출제의도: @연산자의 계산 및 해석
(풀이)
x=np.random.randn(100)
x@x69.28009497479688(33) 아래와 같은 배열을 생성하라.
a=np.array([1/100]*100)
x=np.random.randn(100)numpy의 @연산자를 이용하여 \(\frac{1}{n}\sum_{i=1}^{n}x_i\)를 계산하라.
note: 출제의도: @연산자의 계산 및 해석
(풀이)
a=np.array([1/100]*100)
x=np.random.randn(100)
a@x-0.010052841585430794(34) 표준정규분포에서 100개의 난수를 생성하라.
note: 출제의도: 표준정규분포 생성
(풀이)
np.random.randn(100)array([ 1.85418429, 1.74095494, 1.84238756, 0.11833414, 0.50517813,
-0.69557289, -1.72748266, -0.26601374, 0.57719853, 0.18027158,
-0.42542364, 0.85536403, -0.58893928, 0.55397097, -1.5535881 ,
-0.88229423, -0.71875421, -0.43570715, -0.30980515, -0.36179948,
-0.17548155, 1.44052988, -0.59466028, 0.17292887, -0.59491904,
-1.9695988 , 0.11928747, 1.28964429, 0.53823904, -1.18030647,
-0.20558282, -1.08160482, 0.83372329, 0.28800561, 0.15599112,
-1.03586037, -1.06770958, -2.71210449, 0.58241292, 0.69235475,
1.37391505, -0.0326631 , -0.12266586, -0.20292358, -0.27657851,
0.56420234, 0.40045754, -0.63219726, 0.40820948, -0.612829 ,
-1.28695191, 0.46508036, 0.2463253 , -0.27429529, -0.65675501,
-1.01875321, -0.69944952, -0.31570476, 0.3646879 , -1.1631018 ,
-1.20414629, -0.90456531, 0.89434359, -0.29053615, 1.16408738,
0.71108284, -0.52138787, 1.07033411, 1.72342412, 0.90605155,
-0.28896114, -1.89628331, -1.71603025, 1.21529517, 0.23833153,
-0.52176073, -0.49144623, -0.75427022, 0.10468367, 0.36750664,
0.24346823, 0.20762347, 1.08915492, 1.89502878, 1.91479936,
-0.4241885 , -1.05989046, 0.96622936, 0.40962212, -2.16589513,
0.45357349, -1.23802044, 0.39859558, 0.02910548, 1.44679724,
1.16285902, -0.1593022 , -2.14983146, 0.42739322, -0.94301164])(35) 아래와 동일한 코드를 np.random.rand()로 구현하라.
np.random.uniform(low=2,high=4,size=(5,)) note: 출제의도: np.random.rand, np.random.uniform
(풀이)
np.random.rand(5)*2+2array([3.62616239, 2.4038075 , 2.64420359, 2.80481305, 2.2678642 ])(36) 아래와 같은 배열을 선언하라.
a=np.random.randn(100) np.where를 이용하여 a의 모든 음수를 0으로 바꾸는 코드를 작성하라.
note: 출제의도: np.where 을 이용한 마스킹
(풀이)
a=np.random.randn(100)
np.where(a<0,0,a)array([0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 6.23392366e-01,
0.00000000e+00, 1.08600932e+00, 3.67178107e-01, 0.00000000e+00,
2.20251453e-01, 0.00000000e+00, 0.00000000e+00, 3.89764950e-02,
6.86794220e-01, 6.89479404e-01, 1.26211471e+00, 0.00000000e+00,
4.23611162e-01, 8.19460987e-01, 3.14530150e-01, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 1.30354361e+00, 0.00000000e+00,
0.00000000e+00, 4.40581127e-01, 0.00000000e+00, 0.00000000e+00,
7.86386724e-01, 1.92151119e-02, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 3.23260088e-01, 0.00000000e+00, 7.13352290e-01,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 7.01771469e-01,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 1.01926360e+00,
0.00000000e+00, 1.00933996e+00, 0.00000000e+00, 5.55528483e-01,
5.99763436e-01, 0.00000000e+00, 1.35136571e-01, 1.35928670e-02,
9.35722269e-01, 0.00000000e+00, 8.64547752e-01, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 1.68682634e+00, 0.00000000e+00,
1.07091321e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
8.27772542e-01, 0.00000000e+00, 7.65702396e-01, 0.00000000e+00,
0.00000000e+00, 3.29389519e-01, 0.00000000e+00, 2.51416616e-01,
0.00000000e+00, 8.17591580e-01, 0.00000000e+00, 1.09930438e-01,
8.71101099e-04, 2.17063699e-01, 2.06385934e-01, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 3.19516814e-01, 5.92549379e-02,
1.92857588e+00, 1.39519785e+00, 3.77551912e-01, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 5.16744013e-01, 0.00000000e+00,
1.87178822e+00, 1.75448718e+00, 3.40204387e-01, 7.69851631e-01])(37) 아래와 같은 배열을 선언하라.
a=np.random.randn(100) 위 배열의 최소값이 위치한 index를 return하라.
note: 출제의도: np.where
(풀이)
a=np.random.randn(100)
np.where(a==np.min(a))(array([92]),)(38) 아래와 같은 배열을 선언하라.
a=np.arange(12).reshape(3,4)
aarray([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])차원의 수를 유지하면서 1열을 추출하는 코드를 작성하라. 즉 결과가 아래와 같이 나오도록 하라.
array([[0],
[4],
[8]])note: 출제의도: 차원을 유지하는 인덱싱
(풀이)
a[:,[0]]array([[0],
[4],
[8]])(39)-(40)
(39) 자신의 학번으로 random seed 를 설정하라. [20,25)의 범위에서 100개의 정수를 랜덤으로 생성해 (10,10) shape의 배열을 만들어라.
note: 출제의도: np.random.randint
(풀이)
np.random.seed(43052)
a=np.random.randint(low=20,high=25,size=(10,10))(40) 39의 결과에서 20,21,22 는 각각 몇개씩 있는가?
note: 출제의도: bool형의 sum
(풀이)
np.sum(a==20),np.sum(a==21),np.sum(a==22)(17, 20, 19)2. 코드구현 II (50점)
(1)-(6) 아래의 코드를 실해하여 test_dic를 생성하라.
np.random.seed(43052)
att = np.random.choice(np.arange(10,21)*5,200)
rep = np.random.choice(np.arange(5,21)*5,200)
mid = np.random.choice(np.arange(0,21)*5,200)
fin = np.random.choice(np.arange(0,21)*5,200)
key = ['202212'+str(s) for s in np.random.choice(np.arange(300,501),200,replace=False)]
test_dic = {key[i] : {'att':att[i], 'rep':rep[i], 'mid':mid[i], 'fin':fin[i]} for i in range(200)}
del(att);del(rep);del(mid);del(fin);del(key)여기에서 202212345등은 학번을, att는 출석점수, rep는 레포트점수, mid는 중간고사점수, fin은 기말고사 점수를 의미한다.
(1) test_dic에서 출석점수가 70이상(70>=)인 학생들의 학번을 출력하는 코드를 작성하라.
note: 출제의도: if문이 포함된 리스트컴프리헨션, for문과 딕셔너리
(풀이)
ids= [k for k in test_dic if test_dic[k]['att']>=70](2) test_dic에서 출석점수가 70미만(<70)인 학생들의 수를 구하라.
note: 출제의도: if문이 포함된 리스트컴프리헨션, for문과 딕셔너리
(풀이)
len([k for k in test_dic if test_dic[k]['att']<70])70sum([test_dic[k]['att']<70 for k in test_dic])70(3) test_dic에서 출석점수가 70이상(70>=)인 학생들의 중간고사 점수의 평균을 계산하라.
note: 출제의도: if문이 포함된 리스트컴프리헨션, for문과 딕셔너리
(풀이)
np.mean([test_dic[k]['mid'] for k in test_dic if test_dic[k]['att']>=70])57.15384615384615(4) test_dic에서 중간고사 점수를 출력하는 코드를 작성하라.
note: 출제의도: 리스트컴프리헨션, for문과 딕셔너리
(풀이)
mid=[test_dic[k]['mid'] for k in test_dic](5) test_dic에서 중간고사 점수의 표준편차와 레포트점수의 표준편차를 구하여라. 어떤것이 더 큰가?
note: 출제의도: 리스트컴프리헨션, for문과 딕셔너리, np.std
(풀이)
np.std([test_dic[k]['mid'] for k in test_dic]),np.std([test_dic[k]['rep'] for k in test_dic])(29.88243631299162, 22.626533097229014)(6) test_dic에서 중간고사 점수가 가장 높은 사람의 학번을 출력하라.
주의: att,rep,mid,fin,key를 실행하여 소멸시키지 않고 그대로 이용하거나 np.random.choice()를 이용하여 재생성한 뒤 계산할 경우 0점 처리함. - 예를들면 (5)의 경우 np.std(mid), np.std(rep) 와 같은 식으로 구현하면 0점 처리함.
note: 출제의도: 리스트컴프리헨션, for문과 딕셔너리
(풀이)
[k for k in test_dic if test_dic[k]['mid']==max(mid)]['202212326',
'202212463',
'202212383',
'202212341',
'202212417',
'202212401',
'202212405',
'202212369',
'202212403',
'202212407',
'202212315'](7) 성공확률이 0.45인 시행이 있다고 하자. 이 시행을 100번의 시행하였을 경우 73번 이상 성공할 확률은 얼마인가? 시뮬레이션을 이용하여 근사계산하라.
note: 출제의도: np.random.binomial, bool형의 합
(풀이)
sum(np.random.binomial(n=100,p=0.45,size=(1000,)) >= 73)0(8) 성공확률이 0.45인 시행이 있다고 하자. 이 시행을 100번 시행하였을 경우 10번이하로 실패하거나 90번이상 성공할 확률은 얼마인가? 시뮬레이션을 이용하여 근사계산하라.
note: 출제의도: np.random.binomial, bool형의 합
(풀이)
a=np.random.binomial(n=100,p=0.45,size=(1000,))
sum((a>=90) | (a<=10))0sum(a>=90) + sum(a<=10) # 이것도 좋은 풀이0(9) 아래와 같은 행렬을 선언하자.
A=np.arange(2*1).reshape(2,1)
B=np.arange(2*2).reshape(2,2)
C=np.arange(2*3).reshape(2,3)
D=np.arange(3*3).reshape(3,3)
E=np.arange(3*2).reshape(3,2)
F=np.arange(3*1).reshape(3,1)아래의 블락매트릭스를 만들어라.
\(\begin{bmatrix} a_{11} & b_{11} & b_{12} & c_{11} & c_{12} & c_{13} \\ a_{21} & b_{21} & b_{22} & c_{21} & c_{22} & c_{23} \\ d_{11} & d_{12} & d_{13} & e_{11} & e_{12} & f_{11} \\ d_{21} & d_{22} & d_{23} & e_{21} & e_{22} & f_{21} \\ d_{31} & d_{32} & d_{33} & e_{31} & e_{32} & f_{31} \end{bmatrix}\)
여기에서 \(a_{ij}\)는 매트릭스 \({\bf A}\)의 원소이다.
note: 출제의도: np.concatenate
(풀이)
top = np.concatenate([A,B,C],axis=1)
bottom = np.concatenate([D,E,F],axis=1)
np.concatenate([top,bottom],axis=0)array([[0, 0, 1, 0, 1, 2],
[1, 2, 3, 3, 4, 5],
[0, 1, 2, 0, 1, 0],
[3, 4, 5, 2, 3, 1],
[6, 7, 8, 4, 5, 2]])(10) 표준정규분포에 10000개의 난수를 아래와 같이 생성하라.
x=np.random.randn(10000)
y=np.random.randn(10000)\((i,j)\) 번째 원소가 \((x_i-y_j)^2\)인 (10000,10000) 매트릭스를 만들어라.
note: 출제의도: 브로드캐스팅
(풀이)
(x.reshape(10000,1) - y.reshape(1,10000))**2array([[9.94471594e-01, 1.59617444e+00, 4.89939117e-01, ...,
5.85763251e-02, 8.71831383e-01, 4.48231705e-02],
[3.82650425e-01, 7.82788668e-01, 1.16338019e+00, ...,
3.85231232e-01, 1.72229831e+00, 3.48524169e-01],
[2.19381916e-03, 4.81046770e-02, 3.04162913e+00, ...,
1.65404203e+00, 3.91165053e+00, 1.57699602e+00],
...,
[4.06902110e-02, 4.15352671e-03, 3.60584637e+00, ...,
2.07641061e+00, 4.54827803e+00, 1.98997559e+00],
[6.35135252e-01, 1.13022358e+00, 8.10422594e-01, ...,
1.95632560e-01, 1.28594998e+00, 1.69738287e-01],
[3.93009857e+00, 5.05626325e+00, 8.13727798e-02, ...,
5.52331661e-01, 2.65189382e-03, 5.98303522e-01]])(11)-(16)
아래와 같은 매트릭스를 생성하라.
np.random.seed(43052)
a=np.random.randn(10000).reshape(100,100)
aarray([[ 0.38342049, 1.0841745 , 1.14277825, ..., -0.18506968,
1.05538764, 1.18701443],
[-0.25027283, -1.58045215, 0.1124153 , ..., 1.0321894 ,
0.40438012, -0.13491595],
[-0.76763724, -0.64294232, -0.24782396, ..., -0.01530161,
0.89125897, -0.82683395],
...,
[-1.41379028, 0.79611333, -0.71011837, ..., -0.9860352 ,
1.30755244, 2.18677233],
[ 1.33968105, -0.78457449, -0.10405858, ..., -0.71110186,
0.99841286, 2.34371635],
[-0.66422032, -0.07550233, 0.7405869 , ..., 1.03232398,
-0.18988252, -0.03578389]])(11) 각 행의 합을 구하라. 즉 1행의 합, 2행의 합, … 100행의 합을 계산하라. - 1행의합 = 0.38342049 + 1.0841745 + … + 1.18701443
note: 출제의도: np.sum with axis
(풀이)
a.sum(axis=1)array([-8.13607922e+00, 9.87120533e+00, -1.41434956e+01, -2.21705363e+00,
-1.45535236e+01, -9.15821678e+00, -2.59866360e+00, -1.54562385e+01,
-1.42005088e+00, -3.51523111e+00, 9.70487578e+00, -1.26229105e+01,
1.66837113e+00, 2.43015457e+00, 2.72990184e+00, -7.99486429e+00,
-8.38305954e-01, -8.45002020e+00, -1.03610098e+00, 2.07251861e+01,
1.11461478e+01, 7.62144075e+00, -7.93734585e+00, 1.82844319e+01,
-2.63562392e+00, -8.97916930e+00, -1.88986183e+00, -9.32477049e+00,
-6.69074565e+00, -1.42463143e+01, 6.45540510e-01, 1.80911488e+00,
2.40997157e+00, 1.63367254e+01, 7.63990677e+00, 8.13524813e+00,
3.97159000e+00, -1.10542949e+00, 4.37564512e-01, 2.87299971e+00,
-4.01016768e+00, 5.71115215e+00, -4.64132698e+00, -9.13987753e+00,
-6.78326000e+00, 3.36308150e+00, -5.13704342e+00, -5.09782466e+00,
6.54192465e-03, 7.19722660e+00, -4.64674820e+00, -9.24124039e+00,
6.73530841e+00, 1.12168921e+00, 1.61615988e+00, 1.37602200e+01,
6.67289840e-01, -2.09578108e+00, -2.81826564e-01, -8.52416541e+00,
-7.21970047e+00, 2.27146777e+01, -1.40341974e+01, 1.69263136e+01,
-1.80568372e+01, 6.52142336e+00, -1.73092812e+01, -1.34999285e+01,
-7.85539317e+00, -4.74940393e-01, -2.75765037e+01, 8.74991555e+00,
-9.77324158e+00, 1.42854121e+01, -1.10130356e+00, -1.39206483e-01,
-1.54638921e+01, 1.36814794e+00, 8.41394160e+00, -2.42153833e+00,
-2.57155344e+01, -6.72423820e+00, -9.49366257e-01, 3.79493472e+00,
-6.23508582e+00, 7.75657189e+00, 9.69403620e+00, 1.46847519e+01,
7.36500792e+00, -2.54755192e+01, 1.22792449e+01, -1.02497847e+01,
1.30452028e+01, 3.92943038e+00, -3.27227585e+00, -1.06633071e+01,
-1.56942302e+01, 8.01451222e+00, 2.81546938e+00, 5.56774384e+00])(12) (11)의 결과로 나온 배열의 표준편차를 구하라.
note: 출제의도: np.sum with axis, np.std
(풀이)
a.sum(axis=1).std()9.98012658863081(13) 각 열의 평균을 구하라. 즉 1열의 평균, 2열의 평균, … , 100열의 평균을 계산하라.
note: 출제의도: np.sum with axis
(풀이)
a.sum(axis=0)array([ 5.05543481e-01, -8.11250975e-01, -7.27142023e-01, 9.64876493e+00,
5.64186324e+00, -2.22728206e+00, 1.32808256e-02, -9.60905067e+00,
9.42144096e+00, -1.21946518e+01, -2.21878576e+00, -3.77018716e+00,
2.35739166e-01, -1.13202128e+01, -9.00374437e+00, -3.09372275e+00,
-2.18029121e+00, 7.04210003e+00, -4.12563112e+00, 2.58233488e+00,
1.16578817e+01, -1.59430241e+01, -1.53668953e+00, 9.21879710e+00,
-1.11346500e+01, -1.20131585e+01, 5.94139652e+00, -3.27022797e+00,
-1.46466366e+00, -1.78386785e+00, -1.06650333e+01, -9.04542721e+00,
-8.52586244e+00, 5.52166280e+00, 1.94115122e+01, 4.64389603e+00,
5.13636914e+00, 1.11424801e+01, -4.18629084e+00, 9.23822150e+00,
-2.00433998e+00, -5.73784795e+00, -8.79928414e+00, -3.01766235e+00,
6.47256326e+00, 3.14419234e+00, -1.16146865e+01, -1.04800787e+01,
3.17924308e+00, 5.51687322e+00, 1.04913214e+01, -2.79741703e-01,
2.56767141e+01, -1.35620430e+01, -9.59492302e+00, 1.23241275e+01,
-5.26436946e-01, -3.14823093e+00, -4.00286104e+00, -1.48618576e+01,
4.85988487e+00, -1.37972086e+01, -1.04715966e+01, -7.13893940e+00,
4.35483376e+00, -2.10610822e+01, -1.03231108e+01, -1.62132451e+01,
2.85187037e+01, -8.25697744e+00, 4.33723229e+00, 1.32763889e+00,
-1.61919484e+01, -5.07924036e+00, 6.62243327e+00, -9.72863991e+00,
2.71962223e+01, -5.97710822e+00, 1.54580795e+01, -5.46739064e+00,
-1.08611574e+01, -1.56520706e+01, -1.40476317e+01, 1.06067589e+01,
-3.46141736e+00, -6.07673046e+00, 5.33471760e-01, 8.10276105e+00,
-1.31994569e+01, -1.00936968e+00, 6.13944222e+00, -9.72765699e+00,
1.61342793e+01, 1.02634369e+01, -5.03038014e+00, -7.50604837e+00,
2.63992605e+00, 6.98470602e+00, -1.89567885e+01, 7.91910813e+00])(14) (13)의 결과로 나온 배열의 표준편차를 구하라.
note: 출제의도: np.sum with axis, np.std
(풀이)
a.sum(axis=0).std()9.944992000065781(15) a의 원소중 a>0 을 만족하는 원소의 평균을 구하여라.
note: 출제의도: bool을 이용한 인덱싱
(풀이)
a[a>0].mean()0.7879030416692301(16) a의 원소중 a>3을 만족하는 원소의 수를 count하라.
note: 출제의도: bool의 sum
(풀이)
np.sum(a>3)17(17)-(18)
아래와 같은 배열 a를 고려하자.
np.random.seed(43052)
a=np.random.binomial(1,0.2,size=(10000,))
aarray([1, 0, 1, ..., 1, 1, 0])(17) 0에서 1로 바뀌는 부분을 count하라.
note: 출제의도: np.diff 응용
(풀이)
np.sum(np.diff(a)==1)1617(18) 1에서 0으로 바뀌는 부분을 count하라.
[예시] 아래의 배열에서 0에서 1로 부분은 모두 세 군데이고, 1에서 0으로 바뀌는 부분은 모두 두 군데 이다.
0 0 0 1 0 1 0 0 0 1 1 1 note: 출제의도: np.diff 응용
(풀이)
np.sum(np.diff(a)==-1)1618(19)-(25)
(19) \(i=1,2,\dots,1000\)에 대하여 아래를 각각 구하라.
\[x_i= \cos(t_i)+\cos(3t_i)+\cos(5t_i)\]
\[y_i= \sin(t_i)+\sin(4t_i)\]
여기에서 \(t_i=\frac{2\pi i }{1000}\) 이다.
note: 출제의도: numpy를 이용한 수식표현
(풀이)
i=np.arange(1,1001)
t=i*2*np.pi/1000
x=np.cos(t)+np.cos(3*t)+np.cos(5*t)
y=np.sin(t)+np.sin(4*t) (20) \((x_i,y_i)\)를 그려라.
note: 출제의도: plt.plot
(풀이)
plt.plot(x,y)
(21) 아래와 같은 변환을 통하여 \((w_i,z_i)\)를 얻어라.
\[w_i= \frac{1}{\sqrt{2}}x_i - \frac{1}{\sqrt{2}}y_i\]
\[z_i= \frac{1}{\sqrt{2}}x_i + \frac{1}{\sqrt{2}}y_i\]
\((w_i,z_i)\)를 시각화 하라.
note: 출제의도: numpy를 이용한 연산, plt.plot
(풀이)
w = 1/np.sqrt(2)*x - 1/np.sqrt(2)*y
z = 1/np.sqrt(2)*x + 1/np.sqrt(2)*y
plt.plot(w,z)
(22) 아래와 같은 매트릭스를 만들어라.
\[{\bf A}=\begin{bmatrix} x_1 & y_1 \\ x_2 & y_2 \\ \dots & \dots \\ x_n & y_n \end{bmatrix}\]
note: 출제의도: np.stack
(풀이)
A=np.stack([x,y]).T
Aarray([[ 2.99930917e+00, 3.14132394e-02],
[ 2.99723725e+00, 6.28103581e-02],
[ 2.99378587e+00, 9.41752452e-02],
...,
[ 2.99723725e+00, -6.28103581e-02],
[ 2.99930917e+00, -3.14132394e-02],
[ 3.00000000e+00, -1.22464680e-15]])A=np.stack([x,y],axis=1)
Aarray([[ 2.99930917e+00, 3.14132394e-02],
[ 2.99723725e+00, 6.28103581e-02],
[ 2.99378587e+00, 9.41752452e-02],
...,
[ 2.99723725e+00, -6.28103581e-02],
[ 2.99930917e+00, -3.14132394e-02],
[ 3.00000000e+00, -1.22464680e-15]])(23) \({\bf A} {\bf B}\)의 첫번째 열과 두번째 열을 시각화한 결과가 \((w_i,z_i)\)과 동일하도록 적당한 (2,2) 매트릭스 \({\bf B}\)를 만들어라.
note: 출제의도: 행렬의 수식표현, 행렬의 곱
(풀이)
B= np.array([[1/np.sqrt(2), 1/np.sqrt(2)],[-1/np.sqrt(2), 1/np.sqrt(2)]])
#B= np.array([[1, 1],[-1, 1]])/np.sqrt(2)
plt.plot(A@B[:,0],A@B[:,1])
(24) \({\bf A}{\bf B}^2\)의 첫번째 열과 두번째 열을 시각화 하라.
note: 출제의도: 행렬의 곱
(풀이)
plt.plot((A@B@B)[:,0],(A@B@B)[:,1])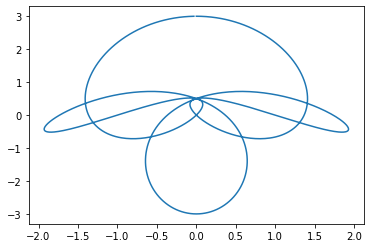
(25) \(n=3,4,5,6,\dots\) 에 대하여 \({\bf A}{\bf B}^n\)을 반복적으로 그려보라. \((x_i,y_i)\)의 시각화 결과와 동일한 가장 작은 \(n\)은 얼마인가? \((w_i,z_i)\)의 시각화 결과와 동일한 가장 작은 \(n\)은 얼마인가?
note: 출제의도: 회전변환의 유추, 역행렬의 개념응용
(풀이)
plt.plot((A@B@B@B)[:,0],(A@B@B@B)[:,1]) ## n=3
plt.plot((A@B@B@B@B)[:,0],(A@B@B@B@B)[:,1]) ## n=4
(B@B)@(B@B)@(B@B)@(B@B)array([[1., 0.],
[0., 1.]])(B@B)@(B@B)@(B@B)@(B@B)@Barray([[ 0.70710678, 0.70710678],
[-0.70710678, 0.70710678]])- 답: \((x_i,y_i)\)의 시각화 결과와 동일한 가장 작은 \(n=8\) 이고 \((w_i,z_i)\)의 시각화 결과와 동일한 가장 작은 \(n=9\) 이다.
3. 다음을 잘 읽고 물음에 답하라. (10점)
(1) 아래는 python을 설치하는 방법을 소개한 url 이다. 직접 url에 들어가서 설치하는 방법을 읽어보고 곤이, 철용, 아귀, 짝귀 중 옳은말을 한 사람을 모두 골라라.
(곤이) 해당 방법은 아나콘다를 이용하여 파이썬을 설치하는 방법이다.
(철용) 그래서 이 방법으로는 가상환경을 만들 수 없겠군.
(아귀) 위 url에 제시된 방법으로 설치하면 주피터가 자동설치 된다.
(짝귀) 따라서 위의 방법으로 설치하면 IDE는 주피터만 사용할 수 있다.
note: 출제의도: 아나콘다를 이용한 설치
(2) 곤이는 1부터 10까지의 합을 구하는 코드를 작성하기 위하여 아래와 같이 mysum.py 파일을 만들었다.
## mysum.py
total = 0
for i in range(1,11):
total = total + i
print(total)곤이의 컴퓨터는 윈도우이며 아니콘다를 이용해 파이썬을 설치하였다고 가정한다. 다음중 옳은 설명을 한 사람을 모두 고르라.
(곤이) mysum.py를 실행하기 위해서는 anaconda prompt 에서 mysum.py가 위치한 폴더로 이동한 뒤 %run mysum.py 를 실행하면 된다.
(철용) anaconda prompt 에서 mysum.py가 위치한 폴더로 이동한 뒤 ipython을 실행하고 %run mysum.py을 실행해도 된다.
(아귀) 철용의 방법에서 %run mysum.py 대신에 !python mysum.py를 쳐도 동작한다.
(짝귀) 하지만 다른 가상환경을 만들 경우 철용과 아귀의 방법으로 실행할 수 없다는 단점이 있다.
note: 출제의도: *.py 의 사용방법