import numpy as np
import pandas as pd08wk-2: Pandas (2)
![]()
강의영상
youtube: https://youtube.com/playlist?list=PLQqh36zP38-zfy1Ym_3c6h8ih5XePRK55
import
pandas 공부 3단계
- df자료형의 메소드를 알아보자.
전치
arr = np.arange(2*3).reshape(2,3)
df = pd.DataFrame(arr)
df| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
df.T| 0 | 1 | |
|---|---|---|
| 0 | 0 | 3 |
| 1 | 1 | 4 |
| 2 | 2 | 5 |
합
df| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
df.sum(axis=0)0 3
1 5
2 7
dtype: int64df.sum(axis=1)0 3
1 12
dtype: int64cumsum
df| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
df.cumsum(axis=1) | 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 0 | 1 | 3 |
| 1 | 3 | 7 | 12 |
형태변환
df| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
df.to_dict(){0: {0: 0, 1: 3}, 1: {0: 1, 1: 4}, 2: {0: 2, 1: 5}}df.to_numpy()array([[0, 1, 2],
[3, 4, 5]])df.to_numpy().tolist()[[0, 1, 2], [3, 4, 5]]기타메소드.. 생략…
pandas 공부 4단계
np.random.seed(43052)
att = np.random.choice(np.arange(10,21)*5,20)
rep = np.random.choice(np.arange(5,21)*5,20)
mid = np.random.choice(np.arange(0,21)*5,20)
fin = np.random.choice(np.arange(0,21)*5,20)
key = ['2022-12'+str(s) for s in np.random.choice(np.arange(300,501),20,replace=False)]
df = pd.DataFrame({'att':att,'rep':rep,'mid':mid,'fin':fin},index=key)
df.head()| att | rep | mid | fin | |
|---|---|---|---|---|
| 2022-12380 | 65 | 55 | 50 | 40 |
| 2022-12370 | 95 | 100 | 50 | 80 |
| 2022-12363 | 65 | 90 | 60 | 30 |
| 2022-12488 | 55 | 80 | 75 | 80 |
| 2022-12312 | 80 | 30 | 30 | 100 |
query (\(\star\))
- 예제1: att==90 and fin>30
df.query('att ==90 and fin >30')| att | rep | mid | fin | |
|---|---|---|---|---|
| 2022-12354 | 90 | 90 | 80 | 90 |
- 예제2: att<rep and mid<fin
df.query('att<rep and mid<fin')| att | rep | mid | fin | |
|---|---|---|---|---|
| 2022-12370 | 95 | 100 | 50 | 80 |
| 2022-12488 | 55 | 80 | 75 | 80 |
| 2022-12458 | 50 | 55 | 15 | 85 |
- 예제3: att < rep < 80
df.query('att<rep<80')| att | rep | mid | fin | |
|---|---|---|---|---|
| 2022-12318 | 55 | 75 | 35 | 25 |
| 2022-12458 | 50 | 55 | 15 | 85 |
- 예제4: 50 < att <= 90 and mid < fin
df.query('50<att<=90 and mid<fin')| att | rep | mid | fin | |
|---|---|---|---|---|
| 2022-12488 | 55 | 80 | 75 | 80 |
| 2022-12312 | 80 | 30 | 30 | 100 |
| 2022-12463 | 65 | 45 | 45 | 90 |
| 2022-12452 | 65 | 55 | 15 | 45 |
| 2022-12354 | 90 | 90 | 80 | 90 |
- 예제5: (mid+fin)/2 >=60
df.query('(mid+fin)/2>=60')| att | rep | mid | fin | |
|---|---|---|---|---|
| 2022-12370 | 95 | 100 | 50 | 80 |
| 2022-12488 | 55 | 80 | 75 | 80 |
| 2022-12312 | 80 | 30 | 30 | 100 |
| 2022-12463 | 65 | 45 | 45 | 90 |
| 2022-12396 | 95 | 30 | 30 | 95 |
| 2022-12354 | 90 | 90 | 80 | 90 |
- 예제6: att > mean(att)
_mean = df['att'].mean()
_mean 73.0df.query('att> @_mean')| att | rep | mid | fin | |
|---|---|---|---|---|
| 2022-12370 | 95 | 100 | 50 | 80 |
| 2022-12312 | 80 | 30 | 30 | 100 |
| 2022-12377 | 75 | 40 | 100 | 15 |
| 2022-12400 | 95 | 65 | 20 | 10 |
| 2022-12469 | 90 | 80 | 80 | 20 |
| 2022-12432 | 95 | 95 | 45 | 0 |
| 2022-12443 | 95 | 55 | 15 | 35 |
| 2022-12396 | 95 | 30 | 30 | 95 |
| 2022-12354 | 90 | 90 | 80 | 90 |
시계열자료
- 시계열자료
pd.date_range('20211226',periods=10)DatetimeIndex(['2021-12-26', '2021-12-27', '2021-12-28', '2021-12-29',
'2021-12-30', '2021-12-31', '2022-01-01', '2022-01-02',
'2022-01-03', '2022-01-04'],
dtype='datetime64[ns]', freq='D')df=pd.DataFrame(np.random.normal(size=(10,4)),columns=list('ABCD'),index=pd.date_range('20211226',periods=10))
df| A | B | C | D | |
|---|---|---|---|---|
| 2021-12-26 | 0.638090 | -0.706648 | 0.214164 | 1.683409 |
| 2021-12-27 | -0.922290 | 0.614785 | 0.405039 | 0.034917 |
| 2021-12-28 | 0.402721 | -0.066538 | 1.015060 | -2.030076 |
| 2021-12-29 | 0.117482 | -0.241408 | -0.178216 | -0.594159 |
| 2021-12-30 | -1.178254 | 0.334073 | 0.108820 | -1.038094 |
| 2021-12-31 | 0.903143 | 0.390493 | 0.793207 | -0.855129 |
| 2022-01-01 | -0.146165 | 0.109616 | -0.811606 | -0.224088 |
| 2022-01-02 | 0.318889 | -0.817596 | 1.300542 | 0.576502 |
| 2022-01-03 | -0.252256 | -1.078405 | -0.569968 | -1.664744 |
| 2022-01-04 | -0.252979 | 0.334156 | -0.756330 | -0.367841 |
- 예제1: 시계열자료에서의 인덱싱
df.loc['2021-12-28':'2022-01-02',:]| A | B | C | D | |
|---|---|---|---|---|
| 2021-12-28 | 0.402721 | -0.066538 | 1.015060 | -2.030076 |
| 2021-12-29 | 0.117482 | -0.241408 | -0.178216 | -0.594159 |
| 2021-12-30 | -1.178254 | 0.334073 | 0.108820 | -1.038094 |
| 2021-12-31 | 0.903143 | 0.390493 | 0.793207 | -0.855129 |
| 2022-01-01 | -0.146165 | 0.109616 | -0.811606 | -0.224088 |
| 2022-01-02 | 0.318889 | -0.817596 | 1.300542 | 0.576502 |
- 예제3: 스트라이딩 (샘플링)
df.loc[::3,:]| A | B | C | D | |
|---|---|---|---|---|
| 2021-12-26 | 0.638090 | -0.706648 | 0.214164 | 1.683409 |
| 2021-12-29 | 0.117482 | -0.241408 | -0.178216 | -0.594159 |
| 2022-01-01 | -0.146165 | 0.109616 | -0.811606 | -0.224088 |
| 2022-01-04 | -0.252979 | 0.334156 | -0.756330 | -0.367841 |
- 예제4: query를 이용한 인덱싱
df.query("index <= '2021-12-30' or index=='2022-01-02'")| A | B | C | D | |
|---|---|---|---|---|
| 2021-12-26 | 0.638090 | -0.706648 | 0.214164 | 1.683409 |
| 2021-12-27 | -0.922290 | 0.614785 | 0.405039 | 0.034917 |
| 2021-12-28 | 0.402721 | -0.066538 | 1.015060 | -2.030076 |
| 2021-12-29 | 0.117482 | -0.241408 | -0.178216 | -0.594159 |
| 2021-12-30 | -1.178254 | 0.334073 | 0.108820 | -1.038094 |
| 2022-01-02 | 0.318889 | -0.817596 | 1.300542 | 0.576502 |
더러운 자료 (1)
예비학습: 하나의 col을 선택하는 가장 좋은 방법
np.random.seed(43052)
att = np.random.choice(np.arange(10,21)*5,20)
rep = np.random.choice(np.arange(5,21)*5,20)
mid = np.random.choice(np.arange(0,21)*5,20)
fin = np.random.choice(np.arange(0,21)*5,20)
key = ['2022-12'+str(s) for s in np.random.choice(np.arange(300,501),20,replace=False)]
df = pd.DataFrame({'att':att,'rep':rep,'mid':mid,'fin':fin},index=key)
df.head()| att | rep | mid | fin | |
|---|---|---|---|---|
| 2022-12380 | 65 | 55 | 50 | 40 |
| 2022-12370 | 95 | 100 | 50 | 80 |
| 2022-12363 | 65 | 90 | 60 | 30 |
| 2022-12488 | 55 | 80 | 75 | 80 |
| 2022-12312 | 80 | 30 | 30 | 100 |
- att 선택
df.att2022-12380 65
2022-12370 95
2022-12363 65
2022-12488 55
2022-12312 80
2022-12377 75
2022-12463 65
2022-12471 60
2022-12400 95
2022-12469 90
2022-12318 55
2022-12432 95
2022-12443 95
2022-12367 50
2022-12458 50
2022-12396 95
2022-12482 50
2022-12452 65
2022-12387 70
2022-12354 90
Name: att, dtype: int64- 단점: 칼럼이름에 스페이스가 있으면 쓸 수 없음.
예비학습끝
- 누가 자료를 아래와 같이 주었다고 하자. (엑셀특)
df.columns = pd.Index(['att score', 'rep score', 'mid score', 'fin score'])
df.head()| att score | rep score | mid score | fin score | |
|---|---|---|---|---|
| 2022-12380 | 65 | 55 | 50 | 40 |
| 2022-12370 | 95 | 100 | 50 | 80 |
| 2022-12363 | 65 | 90 | 60 | 30 |
| 2022-12488 | 55 | 80 | 75 | 80 |
| 2022-12312 | 80 | 30 | 30 | 100 |
- 출석점수를 뽑고 싶다면?
df['att score']
# df.att score # 이코드는 실행불가능2022-12380 65
2022-12370 95
2022-12363 65
2022-12488 55
2022-12312 80
2022-12377 75
2022-12463 65
2022-12471 60
2022-12400 95
2022-12469 90
2022-12318 55
2022-12432 95
2022-12443 95
2022-12367 50
2022-12458 50
2022-12396 95
2022-12482 50
2022-12452 65
2022-12387 70
2022-12354 90
Name: att score, dtype: int64- 출석점수가 90보다 작은 학생을 뽑고 싶다면?
df.loc[df['att score'] < 90, :]
# df.query('att score < 90')| att score | rep score | mid score | fin score | |
|---|---|---|---|---|
| 2022-12380 | 65 | 55 | 50 | 40 |
| 2022-12363 | 65 | 90 | 60 | 30 |
| 2022-12488 | 55 | 80 | 75 | 80 |
| 2022-12312 | 80 | 30 | 30 | 100 |
| 2022-12377 | 75 | 40 | 100 | 15 |
| 2022-12463 | 65 | 45 | 45 | 90 |
| 2022-12471 | 60 | 60 | 25 | 0 |
| 2022-12318 | 55 | 75 | 35 | 25 |
| 2022-12367 | 50 | 80 | 40 | 30 |
| 2022-12458 | 50 | 55 | 15 | 85 |
| 2022-12482 | 50 | 50 | 45 | 10 |
| 2022-12452 | 65 | 55 | 15 | 45 |
| 2022-12387 | 70 | 70 | 40 | 35 |
- 그냥 컬럼이름을 바꾸고 하는것도 방법임
df.columns = pd.Index([l.replace(' ','_') for l in list(df.columns)])
df.head()| att_score | rep_score | mid_score | fin_score | |
|---|---|---|---|---|
| 2022-12380 | 65 | 55 | 50 | 40 |
| 2022-12370 | 95 | 100 | 50 | 80 |
| 2022-12363 | 65 | 90 | 60 | 30 |
| 2022-12488 | 55 | 80 | 75 | 80 |
| 2022-12312 | 80 | 30 | 30 | 100 |
df.query('att_score<90')
df.att_score2022-12380 65
2022-12370 95
2022-12363 65
2022-12488 55
2022-12312 80
2022-12377 75
2022-12463 65
2022-12471 60
2022-12400 95
2022-12469 90
2022-12318 55
2022-12432 95
2022-12443 95
2022-12367 50
2022-12458 50
2022-12396 95
2022-12482 50
2022-12452 65
2022-12387 70
2022-12354 90
Name: att_score, dtype: int64- 그렇지만 col이름을 바꾸는게 항상 만능은 아니다.
개인습관
- row의 이름은 없는게 낫다고 생각함 // 시계열자료는 예외
np.random.seed(43052)
att = np.random.choice(np.arange(10,21)*5,20)
rep = np.random.choice(np.arange(5,21)*5,20)
mid = np.random.choice(np.arange(0,21)*5,20)
fin = np.random.choice(np.arange(0,21)*5,20)
key = ['2022-12'+str(s) for s in np.random.choice(np.arange(300,501),20,replace=False)]
df = pd.DataFrame({'att':att,'rep':rep,'mid':mid,'fin':fin},index=key)
df.head()| att | rep | mid | fin | |
|---|---|---|---|---|
| 2022-12380 | 65 | 55 | 50 | 40 |
| 2022-12370 | 95 | 100 | 50 | 80 |
| 2022-12363 | 65 | 90 | 60 | 30 |
| 2022-12488 | 55 | 80 | 75 | 80 |
| 2022-12312 | 80 | 30 | 30 | 100 |
df2 = df.reset_index().rename(columns={'index':'student_id'})
df2.head()| student_id | att | rep | mid | fin | |
|---|---|---|---|---|---|
| 0 | 2022-12380 | 65 | 55 | 50 | 40 |
| 1 | 2022-12370 | 95 | 100 | 50 | 80 |
| 2 | 2022-12363 | 65 | 90 | 60 | 30 |
| 3 | 2022-12488 | 55 | 80 | 75 | 80 |
| 4 | 2022-12312 | 80 | 30 | 30 | 100 |
- 편해
#df2.loc[0,'student_id':'rep']
#df2.loc[[0],'student_id':'rep']
#df2.loc[[0,4,5],'student_id':'rep']
#df2.loc[range(5),'student_id':'rep']
#df2.loc[5::2,'student_id':'rep'] | student_id | att | rep | |
|---|---|---|---|
| 0 | 2022-12380 | 65 | 55 |
| 1 | 2022-12370 | 95 | 100 |
| 2 | 2022-12363 | 65 | 90 |
| 3 | 2022-12488 | 55 | 80 |
| 4 | 2022-12312 | 80 | 30 |
새로운 열의 추가 (\(\star\star\star\))
- 자료
np.random.seed(43052)
att = np.random.choice(np.arange(10,21)*5,20)
rep = np.random.choice(np.arange(5,21)*5,20)
mid = np.random.choice(np.arange(0,21)*5,20)
fin = np.random.choice(np.arange(0,21)*5,20)
student_id = [ '2023-12362', '2022-12471', '2023-12333', '2022-12400', '2022-12377',
'2022-12469', '2023-12314', '2022-12363', '2023-12445', '2023-12336',
'2023-12426', '2022-12380', '2023-12422', '2022-12488', '2022-12370',
'2023-12443', '2022-12463', '2023-12491', '2023-12340', '2022-12312' ]
df = pd.DataFrame({'student_id':student_id,'att':att,'rep':rep,'mid':mid,'fin':fin})
df| student_id | att | rep | mid | fin | |
|---|---|---|---|---|---|
| 0 | 2023-12362 | 65 | 55 | 50 | 40 |
| 1 | 2022-12471 | 95 | 100 | 50 | 80 |
| 2 | 2023-12333 | 65 | 90 | 60 | 30 |
| 3 | 2022-12400 | 55 | 80 | 75 | 80 |
| 4 | 2022-12377 | 80 | 30 | 30 | 100 |
| 5 | 2022-12469 | 75 | 40 | 100 | 15 |
| 6 | 2023-12314 | 65 | 45 | 45 | 90 |
| 7 | 2022-12363 | 60 | 60 | 25 | 0 |
| 8 | 2023-12445 | 95 | 65 | 20 | 10 |
| 9 | 2023-12336 | 90 | 80 | 80 | 20 |
| 10 | 2023-12426 | 55 | 75 | 35 | 25 |
| 11 | 2022-12380 | 95 | 95 | 45 | 0 |
| 12 | 2023-12422 | 95 | 55 | 15 | 35 |
| 13 | 2022-12488 | 50 | 80 | 40 | 30 |
| 14 | 2022-12370 | 50 | 55 | 15 | 85 |
| 15 | 2023-12443 | 95 | 30 | 30 | 95 |
| 16 | 2022-12463 | 50 | 50 | 45 | 10 |
| 17 | 2023-12491 | 65 | 55 | 15 | 45 |
| 18 | 2023-12340 | 70 | 70 | 40 | 35 |
| 19 | 2022-12312 | 90 | 90 | 80 | 90 |
- 방법1: assign을 이용한 추가
df.assign(total = df.att*0.1 + df.rep*0.2 + df.mid*0.3 + df.fin*0.4) | student_id | att | rep | mid | fin | total | |
|---|---|---|---|---|---|---|
| 0 | 2023-12362 | 65 | 55 | 50 | 40 | 48.5 |
| 1 | 2022-12471 | 95 | 100 | 50 | 80 | 76.5 |
| 2 | 2023-12333 | 65 | 90 | 60 | 30 | 54.5 |
| 3 | 2022-12400 | 55 | 80 | 75 | 80 | 76.0 |
| 4 | 2022-12377 | 80 | 30 | 30 | 100 | 63.0 |
| 5 | 2022-12469 | 75 | 40 | 100 | 15 | 51.5 |
| 6 | 2023-12314 | 65 | 45 | 45 | 90 | 65.0 |
| 7 | 2022-12363 | 60 | 60 | 25 | 0 | 25.5 |
| 8 | 2023-12445 | 95 | 65 | 20 | 10 | 32.5 |
| 9 | 2023-12336 | 90 | 80 | 80 | 20 | 57.0 |
| 10 | 2023-12426 | 55 | 75 | 35 | 25 | 41.0 |
| 11 | 2022-12380 | 95 | 95 | 45 | 0 | 42.0 |
| 12 | 2023-12422 | 95 | 55 | 15 | 35 | 39.0 |
| 13 | 2022-12488 | 50 | 80 | 40 | 30 | 45.0 |
| 14 | 2022-12370 | 50 | 55 | 15 | 85 | 54.5 |
| 15 | 2023-12443 | 95 | 30 | 30 | 95 | 62.5 |
| 16 | 2022-12463 | 50 | 50 | 45 | 10 | 32.5 |
| 17 | 2023-12491 | 65 | 55 | 15 | 45 | 40.0 |
| 18 | 2023-12340 | 70 | 70 | 40 | 35 | 47.0 |
| 19 | 2022-12312 | 90 | 90 | 80 | 90 | 87.0 |
- 방법2: eval을 이용한 추가
df.eval('total = att*0.1 + rep*0.2 + mid*0.3 + fin*0.4') | student_id | att | rep | mid | fin | total | |
|---|---|---|---|---|---|---|
| 0 | 2023-12362 | 65 | 55 | 50 | 40 | 48.5 |
| 1 | 2022-12471 | 95 | 100 | 50 | 80 | 76.5 |
| 2 | 2023-12333 | 65 | 90 | 60 | 30 | 54.5 |
| 3 | 2022-12400 | 55 | 80 | 75 | 80 | 76.0 |
| 4 | 2022-12377 | 80 | 30 | 30 | 100 | 63.0 |
| 5 | 2022-12469 | 75 | 40 | 100 | 15 | 51.5 |
| 6 | 2023-12314 | 65 | 45 | 45 | 90 | 65.0 |
| 7 | 2022-12363 | 60 | 60 | 25 | 0 | 25.5 |
| 8 | 2023-12445 | 95 | 65 | 20 | 10 | 32.5 |
| 9 | 2023-12336 | 90 | 80 | 80 | 20 | 57.0 |
| 10 | 2023-12426 | 55 | 75 | 35 | 25 | 41.0 |
| 11 | 2022-12380 | 95 | 95 | 45 | 0 | 42.0 |
| 12 | 2023-12422 | 95 | 55 | 15 | 35 | 39.0 |
| 13 | 2022-12488 | 50 | 80 | 40 | 30 | 45.0 |
| 14 | 2022-12370 | 50 | 55 | 15 | 85 | 54.5 |
| 15 | 2023-12443 | 95 | 30 | 30 | 95 | 62.5 |
| 16 | 2022-12463 | 50 | 50 | 45 | 10 | 32.5 |
| 17 | 2023-12491 | 65 | 55 | 15 | 45 | 40.0 |
| 18 | 2023-12340 | 70 | 70 | 40 | 35 | 47.0 |
| 19 | 2022-12312 | 90 | 90 | 80 | 90 | 87.0 |
- 방법3: df['total'] 을 이용한 할당 // 추천X
df['total'] = df.att*0.1 + df.rep*0.2 + df.mid*0.3 + df.fin*0.4
df| student_id | att | rep | mid | fin | total | |
|---|---|---|---|---|---|---|
| 0 | 2023-12362 | 65 | 55 | 50 | 40 | 48.5 |
| 1 | 2022-12471 | 95 | 100 | 50 | 80 | 76.5 |
| 2 | 2023-12333 | 65 | 90 | 60 | 30 | 54.5 |
| 3 | 2022-12400 | 55 | 80 | 75 | 80 | 76.0 |
| 4 | 2022-12377 | 80 | 30 | 30 | 100 | 63.0 |
| 5 | 2022-12469 | 75 | 40 | 100 | 15 | 51.5 |
| 6 | 2023-12314 | 65 | 45 | 45 | 90 | 65.0 |
| 7 | 2022-12363 | 60 | 60 | 25 | 0 | 25.5 |
| 8 | 2023-12445 | 95 | 65 | 20 | 10 | 32.5 |
| 9 | 2023-12336 | 90 | 80 | 80 | 20 | 57.0 |
| 10 | 2023-12426 | 55 | 75 | 35 | 25 | 41.0 |
| 11 | 2022-12380 | 95 | 95 | 45 | 0 | 42.0 |
| 12 | 2023-12422 | 95 | 55 | 15 | 35 | 39.0 |
| 13 | 2022-12488 | 50 | 80 | 40 | 30 | 45.0 |
| 14 | 2022-12370 | 50 | 55 | 15 | 85 | 54.5 |
| 15 | 2023-12443 | 95 | 30 | 30 | 95 | 62.5 |
| 16 | 2022-12463 | 50 | 50 | 45 | 10 | 32.5 |
| 17 | 2023-12491 | 65 | 55 | 15 | 45 | 40.0 |
| 18 | 2023-12340 | 70 | 70 | 40 | 35 | 47.0 |
| 19 | 2022-12312 | 90 | 90 | 80 | 90 | 87.0 |
- 아래의 자료에서 입학년도를 추가하고 싶다면?
np.random.seed(43052)
att = np.random.choice(np.arange(10,21)*5,20)
rep = np.random.choice(np.arange(5,21)*5,20)
mid = np.random.choice(np.arange(0,21)*5,20)
fin = np.random.choice(np.arange(0,21)*5,20)
student_id = [ '2023-12362', '2022-12471', '2023-12333', '2022-12400', '2022-12377',
'2022-12469', '2023-12314', '2022-12363', '2023-12445', '2023-12336',
'2023-12426', '2022-12380', '2023-12422', '2022-12488', '2022-12370',
'2023-12443', '2022-12463', '2023-12491', '2023-12340', '2022-12312' ]
df = pd.DataFrame({'student_id':student_id,'att':att,'rep':rep,'mid':mid,'fin':fin})df.assign(year=[l.split('-')[0] for l in list(df.student_id)]).query('year=="2022"')| student_id | att | rep | mid | fin | year | |
|---|---|---|---|---|---|---|
| 1 | 2022-12471 | 95 | 100 | 50 | 80 | 2022 |
| 3 | 2022-12400 | 55 | 80 | 75 | 80 | 2022 |
| 4 | 2022-12377 | 80 | 30 | 30 | 100 | 2022 |
| 5 | 2022-12469 | 75 | 40 | 100 | 15 | 2022 |
| 7 | 2022-12363 | 60 | 60 | 25 | 0 | 2022 |
| 11 | 2022-12380 | 95 | 95 | 45 | 0 | 2022 |
| 13 | 2022-12488 | 50 | 80 | 40 | 30 | 2022 |
| 14 | 2022-12370 | 50 | 55 | 15 | 85 | 2022 |
| 16 | 2022-12463 | 50 | 50 | 45 | 10 | 2022 |
| 19 | 2022-12312 | 90 | 90 | 80 | 90 | 2022 |
HW
아래는 전북대 통계학과 학생들이 R과 Python을 공부한 평균 시간이다.
np.random.seed(20230426)
day = ['2023-04-24(Mon)','2023-04-25(Tue)','2023-04-26(Wed)','2023-04-27(Thu)','2023-04-28(Fri)',
'2023-05-01(Mon)','2023-05-02(Tue)','2023-05-03(Wed)','2023-05-04(Thu)','2023-05-05(Fri)',
'2023-05-08(Mon)','2023-05-09(Tue)','2023-05-10(Wed)','2023-05-11(Thu)','2023-05-12(Fri)']
hours1 = np.random.randn(15).cumsum()*2
hours1 = hours1 - hours1.min() +1
hours2 = np.random.randn(15).cumsum()*2
hours2 = hours2 - hours2.min() +1
df = pd.DataFrame({'hours(R)':hours1, 'hours(Python)':hours2},index=day)
df| hours(R) | hours(Python) | |
|---|---|---|
| 2023-04-24(Mon) | 11.064829 | 9.254671 |
| 2023-04-25(Tue) | 9.790750 | 7.327548 |
| 2023-04-26(Wed) | 5.993362 | 9.185495 |
| 2023-04-27(Thu) | 7.542498 | 12.525569 |
| 2023-04-28(Fri) | 8.598600 | 10.906909 |
| 2023-05-01(Mon) | 6.933549 | 9.865538 |
| 2023-05-02(Tue) | 6.456987 | 11.081043 |
| 2023-05-03(Wed) | 4.976548 | 10.240239 |
| 2023-05-04(Thu) | 6.021139 | 5.822405 |
| 2023-05-05(Fri) | 1.851839 | 5.522484 |
| 2023-05-08(Mon) | 1.000000 | 4.319094 |
| 2023-05-09(Tue) | 1.350073 | 1.000000 |
| 2023-05-10(Wed) | 3.138700 | 2.633662 |
| 2023-05-11(Thu) | 3.153756 | 4.870860 |
| 2023-05-12(Fri) | 1.353976 | 1.785441 |
(1) 데이터프레임을 변형하여 아래와 같이 만들어라.
#| hours(R) | hours(Python) | day | weekday | |
|---|---|---|---|---|
| 0 | 11.064829 | 9.254671 | 2023-04-24 | Mon |
| 1 | 9.790750 | 7.327548 | 2023-04-25 | Tue |
| 2 | 5.993362 | 9.185495 | 2023-04-26 | Wed |
| 3 | 7.542498 | 12.525569 | 2023-04-27 | Thu |
| 4 | 8.598600 | 10.906909 | 2023-04-28 | Fri |
| 5 | 6.933549 | 9.865538 | 2023-05-01 | Mon |
| 6 | 6.456987 | 11.081043 | 2023-05-02 | Tue |
| 7 | 4.976548 | 10.240239 | 2023-05-03 | Wed |
| 8 | 6.021139 | 5.822405 | 2023-05-04 | Thu |
| 9 | 1.851839 | 5.522484 | 2023-05-05 | Fri |
| 10 | 1.000000 | 4.319094 | 2023-05-08 | Mon |
| 11 | 1.350073 | 1.000000 | 2023-05-09 | Tue |
| 12 | 3.138700 | 2.633662 | 2023-05-10 | Wed |
| 13 | 3.153756 | 4.870860 | 2023-05-11 | Thu |
| 14 | 1.353976 | 1.785441 | 2023-05-12 | Fri |
(풀이)
index = [l.replace(')','').split('(') for l in df.index]
df = df.assign(
day=[day for day, _ in index],
weekday=[weekday for _,weekday in index]
).reset_index().loc[:,'hours(R)':]
df| hours(R) | hours(Python) | day | weekday | |
|---|---|---|---|---|
| 0 | 11.064829 | 9.254671 | 2023-04-24 | Mon |
| 1 | 9.790750 | 7.327548 | 2023-04-25 | Tue |
| 2 | 5.993362 | 9.185495 | 2023-04-26 | Wed |
| 3 | 7.542498 | 12.525569 | 2023-04-27 | Thu |
| 4 | 8.598600 | 10.906909 | 2023-04-28 | Fri |
| 5 | 6.933549 | 9.865538 | 2023-05-01 | Mon |
| 6 | 6.456987 | 11.081043 | 2023-05-02 | Tue |
| 7 | 4.976548 | 10.240239 | 2023-05-03 | Wed |
| 8 | 6.021139 | 5.822405 | 2023-05-04 | Thu |
| 9 | 1.851839 | 5.522484 | 2023-05-05 | Fri |
| 10 | 1.000000 | 4.319094 | 2023-05-08 | Mon |
| 11 | 1.350073 | 1.000000 | 2023-05-09 | Tue |
| 12 | 3.138700 | 2.633662 | 2023-05-10 | Wed |
| 13 | 3.153756 | 4.870860 | 2023-05-11 | Thu |
| 14 | 1.353976 | 1.785441 | 2023-05-12 | Fri |
(2) 4월달에 전북대학교 학생들은 R과 Python중 어떤 과목을 더 많이 공부하였는가?
(풀이)
df.query('day <= "2023-04-28"')['hours(R)'].sum()42.99003889835529df.query('day <= "2023-04-28"')['hours(Python)'].sum()49.20019054928582(3) ‘월-금’ 사이의 요일중 R을 가장 열심히 공부한 요일은 어느 요일인가?
(풀이1)
{s:df.loc[df.weekday == s,'hours(R)'].sum() for s in set(df.weekday)}{'Mon': 18.99837797631909,
'Tue': 17.597810683605076,
'Thu': 16.717393020928853,
'Fri': 11.804415159359687,
'Wed': 14.10860912003022}월요일에 가장 많이함
(풀이2) – groupby를 이용하여 풀어도 무방 (이 수업에서는 설명하지 않은 방법임)
(4) ’월-금’사이의 요일중 Python과 R의 합계학습량이 가장 큰 요일은 어느 요일인가?
(풀이)
{s:df.loc[df.weekday == s,'hours(R)',].sum()+df.loc[df.weekday == s,'hours(Python)'].sum() for s in set(df.weekday)}{'Mon': 42.43767989050608,
'Tue': 37.00640176680126,
'Thu': 39.93622729700404,
'Fri': 30.019248136418938,
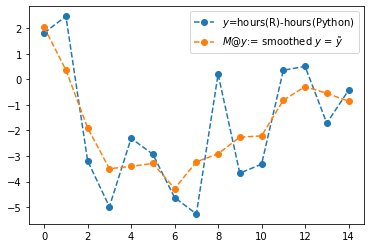
'Wed': 36.16800423923865}(5) R과 Python의 학습량 차이를 계산하고 (R-Python을 계산) maplotlib 을 이용하여 시각화하라.
(풀이)
y = df['hours(R)'] - df['hours(Python)']
plt.plot(y,'--o')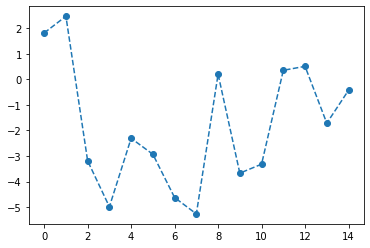
(6) R과 Python의 학습량 차이를 \({\bf y}=(y_1,\dots,y_n)\)라고 할때, 아래와 같은 변환을 이용하여 \(\tilde{\bf y}=({\tilde{y}_1}, \dots, {\tilde{y}_n})\)를 계산하라.
- \(\tilde{y}_1= \frac{1}{3}(2y_1 + y_2)\)
- \(\tilde{y}_i= \frac{1}{3}(y_{i-1}+y_i+y_{i+1})\), for \(i=2,3,\dots,n-1\)
- \(\tilde{y}_n= \frac{1}{3}(y_{n-1}+2y_{n})\)
결과를 시각화하라.
(풀이)
n = len(y)
M = np.array([abs(i-j)<2 for i in range(n) for j in range(n)]).reshape(n,n)/3
M[0,0] = 2/3
M[-1,-1] = 2/3 plt.plot(y,'--o',label=r'$y$=hours(R)-hours(Python)')
plt.plot(M@y,'--o',label=r'$M@y$:= smoothed $y$ = $\tilde{y}$')
plt.legend()<matplotlib.legend.Legend at 0x7fd1d9374340>