11/10: [순환신경망] RNN (2)
AbAcAd예제(3)
강의영상
youtube: https://youtube.com/playlist?list=PLQqh36zP38-zRWSBjuvzsjPe6JxnHO4AX
import
Define some funtions
Exam4: AbAcAd (3)
data
- 기존의 정리방식
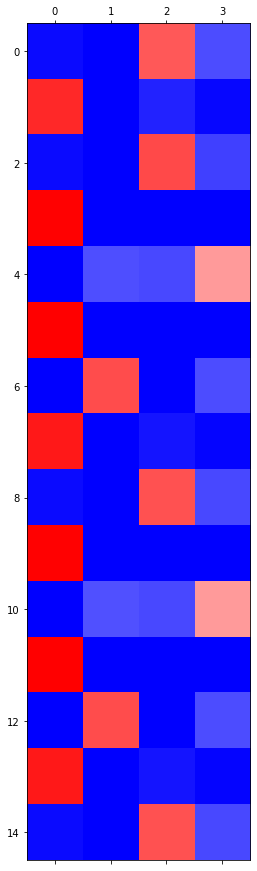
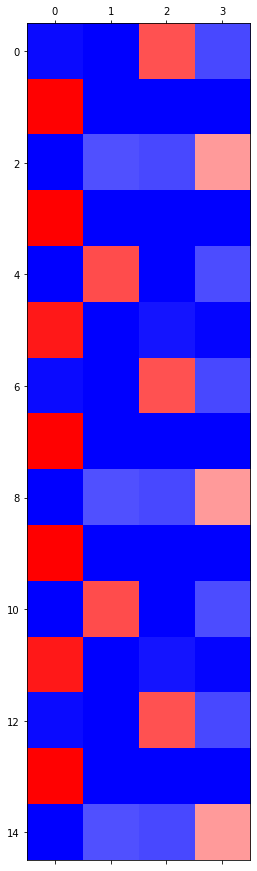
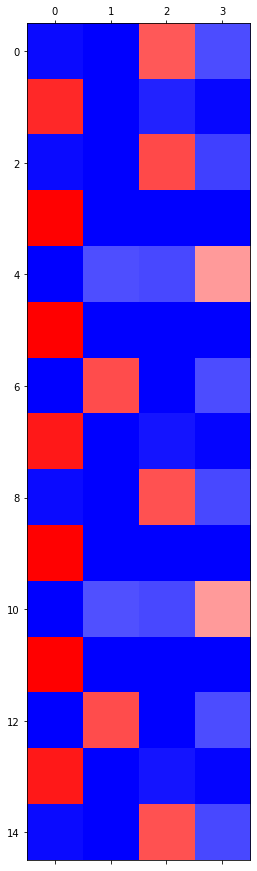
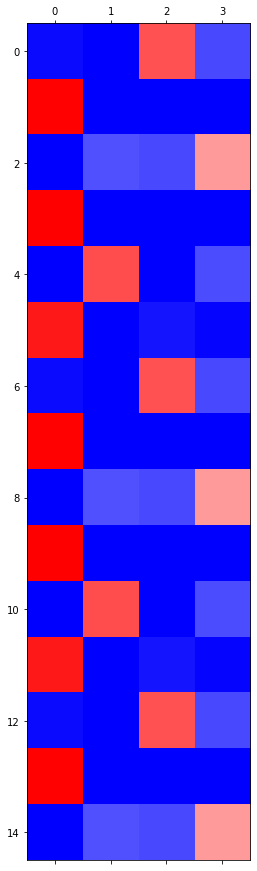


HW: hello 예제
아래와 같이 hello가 반복되는 자료가 있다고 하자.
(tensor([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
...,
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 1., 0.]]),
tensor([[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 1., 0.],
...,
[0., 0., 1., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]]))3개의 은닉노드를 가진 RNN을 설계하고 학습시켜라.