기말고사
주의: 엑셀 등을 이용하여 자료를 전처리할 경우 부분점수 없이 0점 처리함
1. 시군구별 에너지사용량 시각화 I (30점)
아래의 주소들에서 2018-2021의 시군구별 에너지 사용량에 대한 자료를 정리하고 물음에 답하라.
# 2018
https://raw.githubusercontent.com/guebin/DV2022/main/posts/Energy/Seoul2018.csv
...
https://raw.githubusercontent.com/guebin/DV2022/main/posts/Energy/Jeju-do2018.csv
# 2019
https://raw.githubusercontent.com/guebin/DV2022/main/posts/Energy/Seoul2019.csv
...
https://raw.githubusercontent.com/guebin/DV2022/main/posts/Energy/Jeju-do2019.csv
# 2020
https://raw.githubusercontent.com/guebin/DV2022/main/posts/Energy/Seoul2020.csv
...
https://raw.githubusercontent.com/guebin/DV2022/main/posts/Energy/Jeju-do2020.csv
# 2021
https://raw.githubusercontent.com/guebin/DV2022/main/posts/Energy/Seoul2021.csv
...
https://raw.githubusercontent.com/guebin/DV2022/main/posts/Energy/Jeju-do2021.csv
hint1: 코드1, 코드2를 적절하게 응용하면 쉽게 데이터를 합칠 수 있음
## 코드1
_district = [global_dict['features'][i]['properties']['name_eng'] for i in range(17)]
_year = ['2018','2019','2020','2021']
for d in _district:
for y in _year:
print(d+y)
## 코드2
_url = 'https://raw.githubusercontent.com/guebin/DV2022/main/posts/Energy/{}.csv'
pd.concat([pd.read_csv(_url.format(k)) for k in ['Seoul2018','Jeju-do2018']])hint2: 데이터프레임을 읽었을 때 ['에너지사용량(TOE)/지역난방']의 자료형이 통일되어 있지 않음을 유의하여 처리할 것.
pd.read_csv('https://raw.githubusercontent.com/guebin/DV2022/main/posts/Energy/Gangwon-do2021.csv')['에너지사용량(TOE)/지역난방'].dtypedtype('int64')pd.read_csv('https://raw.githubusercontent.com/guebin/DV2022/main/posts/Energy/Seoul2021.csv')['에너지사용량(TOE)/지역난방'].dtypedtype('O')hint3: 아래의 코드를 이용하여 geojson 파일을 확보하고 문제를 풀 것
global_dict = json.loads(requests.get('https://raw.githubusercontent.com/southkorea/southkorea-maps/master/kostat/2018/json/skorea-provinces-2018-geo.json').text)
local_dict = json.loads(requests.get('https://raw.githubusercontent.com/southkorea/southkorea-maps/master/kostat/2018/json/skorea-municipalities-2018-geo.json').text)hint4: 필요하다면 아래의 코드를 활용할 것 (활용하지 않아도 무방함)
| A | B | |
|---|---|---|
| 0 | 서초구 | 33,231 |
| 1 | 강남구 | 22,321 |
| 2 | 송파구 | 45123 |
(할당)
| A | B | C | D | |
|---|---|---|---|---|
| 0 | 서초구 | 33,231 | 2018 | Seoul |
| 1 | 강남구 | 22,321 | 2018 | Seoul |
| 2 | 송파구 | 45123 | 2018 | Seoul |
(인덱스)
| B | C | ||
|---|---|---|---|
| A | D | ||
| 서초구 | Seoul | 33,231 | 2018 |
| 강남구 | Seoul | 22,321 | 2018 |
| 송파구 | Seoul | 45123 | 2018 |
(applymap)
| B | C | ||
|---|---|---|---|
| A | D | ||
| 서초구 | Seoul | 33231 | 2018 |
| 강남구 | Seoul | 22321 | 2018 |
| 송파구 | Seoul | 45123 | 2018 |
(1) 아래의 지역에 대한 4년간 전기 에너지 사용량의 총합을 구하고 folium을 이용하여 시각화 하라.
['Seoul',
'Busan',
'Daegu',
'Incheon',
'Gwangju',
'Daejeon',
'Ulsan',
'Sejongsi',
'Gyeonggi-do',
'Gangwon-do',
'Chungcheongbuk-do',
'Chungcheongnam-do',
'Jeollabuk-do',
'Jeollanam-do',
'Gyeongsangbuk-do',
'Gyeongsangnam-do',
'Jeju-do']- location = [36,128], zoom_start=7 로 설정
(풀이)
- 단계1: 데이터프레임 정리
df= pd.concat([pd.read_csv(_url.format(d+y)).assign(year=y,district=d) for d in _district_eng for y in _year])\
.reset_index(drop=True)\
.set_axis(['지역local','건물동수','연면적','전기','도시가스','지역난방','연도','지역global'],axis=1)\
.set_index(['지역global','지역local'])\
.applymap(lambda x: int(str(x).replace(',',''))).reset_index()
df| 지역global | 지역local | 건물동수 | 연면적 | 전기 | 도시가스 | 지역난방 | 연도 | |
|---|---|---|---|---|---|---|---|---|
| 0 | Seoul | 종로구 | 17929 | 9141777 | 64818 | 82015 | 111 | 2018 |
| 1 | Seoul | 중구 | 10598 | 10056233 | 81672 | 75260 | 563 | 2018 |
| 2 | Seoul | 용산구 | 17201 | 10639652 | 52659 | 85220 | 12043 | 2018 |
| 3 | Seoul | 성동구 | 14180 | 11631770 | 60559 | 107416 | 0 | 2018 |
| 4 | Seoul | 광진구 | 21520 | 12054796 | 70609 | 130308 | 0 | 2018 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 995 | Jeju-do | 서귀포시 | 34729 | 7233931 | 34641 | 1306 | 0 | 2019 |
| 996 | Jeju-do | 제주시 | 66504 | 19819923 | 99212 | 22179 | 0 | 2020 |
| 997 | Jeju-do | 서귀포시 | 34880 | 7330040 | 35510 | 1639 | 0 | 2020 |
| 998 | Jeju-do | 제주시 | 67053 | 20275738 | 103217 | 25689 | 0 | 2021 |
| 999 | Jeju-do | 서귀포시 | 35230 | 7512206 | 37884 | 2641 | 0 | 2021 |
1000 rows × 8 columns
- 단계2: 시각화할 자료 정리
| 지역global | 전기 | |
|---|---|---|
| 0 | Busan | 2860998 |
| 1 | Chungcheongbuk-do | 1413048 |
| 2 | Chungcheongnam-do | 1795949 |
| 3 | Daegu | 1802007 |
| 4 | Daejeon | 1221429 |
| 5 | Gangwon-do | 1491560 |
| 6 | Gwangju | 1154501 |
| 7 | Gyeonggi-do | 9084472 |
| 8 | Gyeongsangbuk-do | 2045804 |
| 9 | Gyeongsangnam-do | 2450436 |
| 10 | Incheon | 1988226 |
| 11 | Jeju-do | 536540 |
| 12 | Jeollabuk-do | 1416208 |
| 13 | Jeollanam-do | 1341756 |
| 14 | Sejongsi | 263956 |
| 15 | Seoul | 9331349 |
| 16 | Ulsan | 779840 |
- 단계3: 시각화
m = folium.Map(
location = [36,128],
zoom_start=7,
scrollWheelZoom = False
)
folium.Choropleth(
geo_data=global_dict,
data=df.groupby(['지역global'])['전기'].sum().reset_index(),
columns=['지역global','전기'],
key_on='properties.name_eng',
).add_to(m)
m(2) 서울의 4년간 전기에너지 사용량의 총합을 구하고 folium을 이용하여 구별로 시각화 하라.
hint1: 아래의 리스트에서
11로 시작하는 원소들이 서울지역이다.
hint2: 서울특별시의 “중구”는 유일한 구 이름이 아님을 유의하여 자료를 처리할 것. (예를들어 부산에도 “중구”, 대구에도 “중구”가 존재함)
(풀이)
- 단계1: local_dict2 정리
- 단계2: 시각화할 자료정리
| 지역local | 전기 | |
|---|---|---|
| 0 | 강남구 | 905469 |
| 1 | 강동구 | 322585 |
| 2 | 강북구 | 215655 |
| 3 | 강서구 | 438579 |
| 4 | 관악구 | 393429 |
| 5 | 광진구 | 307727 |
| 6 | 구로구 | 326921 |
| 7 | 금천구 | 218396 |
| 8 | 노원구 | 354521 |
| 9 | 도봉구 | 205777 |
| 10 | 동대문구 | 300022 |
| 11 | 동작구 | 298972 |
| 12 | 마포구 | 444166 |
| 13 | 서대문구 | 286668 |
| 14 | 서초구 | 650482 |
| 15 | 성동구 | 300004 |
| 16 | 성북구 | 344506 |
| 17 | 송파구 | 654551 |
| 18 | 양천구 | 339078 |
| 19 | 영등포구 | 459870 |
| 20 | 용산구 | 251535 |
| 21 | 은평구 | 339143 |
| 22 | 종로구 | 313612 |
| 23 | 중구 | 394690 |
| 24 | 중랑구 | 264991 |
- 단계3: 시각화
m = folium.Map(
location = [37.55,127],
zoom_start=11,
scrollWheelZoom = False
)
folium.Choropleth(
geo_data=local_dict2,
data=df.query('지역global=="Seoul"').groupby('지역local')['전기'].sum().reset_index(),
columns=['지역local','전기'],
key_on='properties.name',
).add_to(m)
m- location = [37.55,127], zoom_start=11 로 설정
(3) 서울의 전기에너지 사용비율을 (연도별,구별)로 구하고 이를 plotly의 choropleth_mapbox를 이용하여 시각화 하라. (연도에 따라 choropleth map이 바뀌도록 시각화 할 것)
hint1: 2020년의 관악구의 전기에너지 사용비율은 아래와 같이 계산한다.
\(\frac{\text{2020관악구의 ``에너지사용량(TOE)/전기''}}{\text{2020관악구의 ``에너지사용량(TOE)/전기''}+\text{2020관악구의 ``에너지사용량(TOE)/도시가스''}+\text{2020년 관악구의 ``에너지사용량(TOE)/지역난방''}}\)
hint2: 아래의 코드 참고할 것.
fig = px.choropleth_mapbox(data_frame=???,
geojson=???,
color=???,
locations=???,
featureidkey=???,
center={"lat": 37.55, "lon": 126.95},
mapbox_style="carto-positron",
animation_frame=???, # 2028,2019,2020,2021와 같이 년도가 명시된 column의 이름을 쓸 것
range_color=[0.31,0.56],
height=800,
zoom=10)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})(풀이)
- 1단계: 시각화할 자료정리
| 지역global | 지역local | 건물동수 | 연면적 | 전기 | 도시가스 | 지역난방 | 연도 | 전기사용비율 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Seoul | 종로구 | 17929 | 9141777 | 64818 | 82015 | 111 | 2018 | 0.441107 |
| 1 | Seoul | 중구 | 10598 | 10056233 | 81672 | 75260 | 563 | 2018 | 0.518569 |
| 2 | Seoul | 용산구 | 17201 | 10639652 | 52659 | 85220 | 12043 | 2018 | 0.351243 |
| 3 | Seoul | 성동구 | 14180 | 11631770 | 60559 | 107416 | 0 | 2018 | 0.360524 |
| 4 | Seoul | 광진구 | 21520 | 12054796 | 70609 | 130308 | 0 | 2018 | 0.351434 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 95 | Seoul | 관악구 | 31299 | 22230193 | 136043 | 196643 | 78 | 2021 | 0.408827 |
| 96 | Seoul | 서초구 | 16686 | 32824535 | 242700 | 181974 | 39854 | 2021 | 0.522466 |
| 97 | Seoul | 강남구 | 22464 | 48871036 | 364645 | 236446 | 95742 | 2021 | 0.523289 |
| 98 | Seoul | 송파구 | 22727 | 38819901 | 236444 | 185492 | 94175 | 2021 | 0.458126 |
| 99 | Seoul | 강동구 | 18715 | 24990185 | 110313 | 144513 | 16676 | 2021 | 0.406306 |
100 rows × 9 columns
- 2단계: 시각화
fig = px.choropleth_mapbox(data_frame=df.eval('전기사용비율 = 전기/(전기+도시가스+지역난방)').query('지역global=="Seoul"'),
geojson=local_dict2,
color='전기사용비율',
locations="지역local",
featureidkey="properties.name",
center={"lat": 37.55, "lon": 127},
mapbox_style="carto-positron",
animation_frame='연도',
range_color=[0.31,0.56],
height=800,
zoom=10)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})2. 시군구별 에너지사용량 시각화 II (50점)
문제1과 동일한 자료에 대하여 아래의 물음에 답하라.
(1) 전주시 덕진구와 완산구에서 사용하는 전기양은 전라북도 전체의 몇 프로인지 연도별로 계산하고 아래의 예시와 같이 시각화 하라.
(풀이)
- 단계1: 시각화할 자료 정리
data = df.query('지역global=="Jeollabuk-do"')\
.groupby(['연도'])[['전기']].sum().reset_index()\
.rename({'전기':'전라북도전기'},axis=1)\
.merge(df.query('지역global=="Jeollabuk-do"'))\
.eval("전기사용비율=전기/전라북도전기")\
.query('지역local == "덕진구" or 지역local == "완산구"')\
.assign(전기사용비율 = lambda df: np.round(df['전기사용비율']*100,2))
data | 연도 | 전라북도전기 | 지역global | 지역local | 건물동수 | 연면적 | 전기 | 도시가스 | 지역난방 | 전기사용비율 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2018 | 356715 | Jeollabuk-do | 완산구 | 24316 | 15641523 | 72699 | 110116 | 0 | 20.38 |
| 1 | 2018 | 356715 | Jeollabuk-do | 덕진구 | 21544 | 12849472 | 55943 | 93614 | 0 | 15.68 |
| 15 | 2019 | 350862 | Jeollabuk-do | 완산구 | 24007 | 15887048 | 70407 | 107398 | 0 | 20.07 |
| 16 | 2019 | 350862 | Jeollabuk-do | 덕진구 | 21838 | 14031054 | 60082 | 96283 | 0 | 17.12 |
| 30 | 2020 | 351573 | Jeollabuk-do | 완산구 | 23896 | 16243948 | 70624 | 109893 | 0 | 20.09 |
| 31 | 2020 | 351573 | Jeollabuk-do | 덕진구 | 21803 | 14312769 | 60857 | 99518 | 0 | 17.31 |
| 45 | 2021 | 357058 | Jeollabuk-do | 완산구 | 23634 | 16469222 | 71668 | 109775 | 0 | 20.07 |
| 46 | 2021 | 357058 | Jeollabuk-do | 덕진구 | 21860 | 14935582 | 63098 | 100534 | 0 | 17.67 |
- 단계2: 시각화
(2) 면적대비 총 에너지사용량이 많은 상위20개의 지역을 찾고 아래의 예시와 같이 시각화 하라.
(풀이)
- 단계1: 시각화할 자료 정리
data = df.eval('면적대비에너지사용량 = (전기+도시가스+지역난방)/ 연면적')\
.assign(면적대비에너지사용량 = lambda df: list(map(lambda x: np.round(x,4),df['면적대비에너지사용량'])))\
.sort_values(by='면적대비에너지사용량',ascending=False).reset_index(drop=True).iloc[:20]\
.assign(지역연도=lambda df: list(map(lambda x,y: x+'/'+str(y), df['지역local'],df['연도'])))\
.rename({'지역연도':'지역/연도'},axis=1)
data| 지역global | 지역local | 건물동수 | 연면적 | 전기 | 도시가스 | 지역난방 | 연도 | 면적대비에너지사용량 | 지역/연도 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Seoul | 관악구 | 26318 | 14896412 | 87602 | 167297 | 0 | 2018 | 0.0171 | 관악구/2018 |
| 1 | Seoul | 광진구 | 21520 | 12054796 | 70609 | 130308 | 0 | 2018 | 0.0167 | 광진구/2018 |
| 2 | Gyeonggi-do | 중원구 | 13242 | 6353510 | 32946 | 67857 | 4768 | 2018 | 0.0166 | 중원구/2018 |
| 3 | Seoul | 강북구 | 23678 | 9496358 | 49566 | 108311 | 0 | 2018 | 0.0166 | 강북구/2018 |
| 4 | Seoul | 관악구 | 26460 | 14997859 | 85416 | 158543 | 0 | 2019 | 0.0163 | 관악구/2019 |
| 5 | Seoul | 종로구 | 17929 | 9141777 | 64818 | 82015 | 111 | 2018 | 0.0161 | 종로구/2018 |
| 6 | Seoul | 은평구 | 25534 | 14271100 | 76127 | 136469 | 13822 | 2018 | 0.0159 | 은평구/2018 |
| 7 | Gyeonggi-do | 중원구 | 12912 | 6390717 | 32484 | 63925 | 5324 | 2021 | 0.0159 | 중원구/2021 |
| 8 | Gyeonggi-do | 중원구 | 12970 | 6327917 | 31924 | 63586 | 4503 | 2019 | 0.0158 | 중원구/2019 |
| 9 | Seoul | 마포구 | 19003 | 14946106 | 94151 | 122285 | 20307 | 2018 | 0.0158 | 마포구/2018 |
| 10 | Gyeonggi-do | 중원구 | 12960 | 6332577 | 31807 | 63432 | 4546 | 2020 | 0.0158 | 중원구/2020 |
| 11 | Seoul | 광진구 | 21556 | 12272738 | 68756 | 123447 | 0 | 2019 | 0.0157 | 광진구/2019 |
| 12 | Seoul | 중구 | 10598 | 10056233 | 81672 | 75260 | 563 | 2018 | 0.0157 | 중구/2018 |
| 13 | Seoul | 동작구 | 20144 | 13342622 | 68158 | 138503 | 2076 | 2018 | 0.0156 | 동작구/2018 |
| 14 | Seoul | 강북구 | 23334 | 9458987 | 47731 | 100045 | 0 | 2019 | 0.0156 | 강북구/2019 |
| 15 | Seoul | 강북구 | 23058 | 9440702 | 47190 | 99468 | 0 | 2020 | 0.0155 | 강북구/2020 |
| 16 | Seoul | 마포구 | 22621 | 23134516 | 168020 | 149218 | 41874 | 2021 | 0.0155 | 마포구/2021 |
| 17 | Seoul | 서대문구 | 17933 | 12159965 | 65234 | 116563 | 6701 | 2018 | 0.0155 | 서대문구/2018 |
| 18 | Seoul | 은평구 | 24409 | 14567215 | 75855 | 132606 | 15344 | 2020 | 0.0154 | 은평구/2020 |
| 19 | Seoul | 광진구 | 21269 | 12194019 | 66974 | 120397 | 0 | 2020 | 0.0154 | 광진구/2020 |
서울특별시와 경기도에 속한 구역을 아래와 같이 구분하여 시각화 하라.
(3) 각 시도별로 4년간 에너지사용량(=전기+도시가스+지역난방)이 가장 많은 2개의 구를 뽑고 아래와 같이 시각화 하라.
(풀이1)
- 단계1: 에너지사용량을 계산
| 지역global | 지역local | 건물동수 | 연면적 | 전기 | 도시가스 | 지역난방 | 연도 | 에너지사용량 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Seoul | 종로구 | 17929 | 9141777 | 64818 | 82015 | 111 | 2018 | 146944 |
| 1 | Seoul | 중구 | 10598 | 10056233 | 81672 | 75260 | 563 | 2018 | 157495 |
| 2 | Seoul | 용산구 | 17201 | 10639652 | 52659 | 85220 | 12043 | 2018 | 149922 |
| 3 | Seoul | 성동구 | 14180 | 11631770 | 60559 | 107416 | 0 | 2018 | 167975 |
| 4 | Seoul | 광진구 | 21520 | 12054796 | 70609 | 130308 | 0 | 2018 | 200917 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 995 | Jeju-do | 서귀포시 | 34729 | 7233931 | 34641 | 1306 | 0 | 2019 | 35947 |
| 996 | Jeju-do | 제주시 | 66504 | 19819923 | 99212 | 22179 | 0 | 2020 | 121391 |
| 997 | Jeju-do | 서귀포시 | 34880 | 7330040 | 35510 | 1639 | 0 | 2020 | 37149 |
| 998 | Jeju-do | 제주시 | 67053 | 20275738 | 103217 | 25689 | 0 | 2021 | 128906 |
| 999 | Jeju-do | 서귀포시 | 35230 | 7512206 | 37884 | 2641 | 0 | 2021 | 40525 |
1000 rows × 9 columns
- 단계2: 4년간 에너지사용량을 구함
df.eval('에너지사용량=전기+도시가스+지역난방')\
.groupby(['지역local','지역global'])\
.agg({'에너지사용량':np.sum}).reset_index().rename({'에너지사용량':'4년간에너지사용량'},axis=1)| 지역local | 지역global | 4년간에너지사용량 | |
|---|---|---|---|
| 0 | 가평군 | Gyeonggi-do | 121123 |
| 1 | 강남구 | Seoul | 1951762 |
| 2 | 강동구 | Seoul | 891347 |
| 3 | 강릉시 | Gangwon-do | 312812 |
| 4 | 강북구 | Seoul | 636983 |
| ... | ... | ... | ... |
| 245 | 화성시 | Gyeonggi-do | 1353424 |
| 246 | 화순군 | Jeollanam-do | 88249 |
| 247 | 화천군 | Gangwon-do | 20574 |
| 248 | 횡성군 | Gangwon-do | 68539 |
| 249 | 흥덕구 | Chungcheongbuk-do | 533631 |
250 rows × 3 columns
- 단계3: ’지역global’로 그룹핑된 리스트 생성
lst = df.eval('에너지사용량=전기+도시가스+지역난방')\
.groupby(['지역local','지역global'])\
.agg({'에너지사용량':np.sum}).reset_index().rename({'에너지사용량':'4년간에너지사용량'},axis=1)\
.groupby('지역global')\
.pipe(list)
lst[0] # 편의상 리스트의 첫원소만 출력 ('Busan',
지역local 지역global 4년간에너지사용량
5 강서구 Busan 200386
39 금정구 Busan 451212
41 기장군 Busan 287926
48 남구 Busan 491030
69 동구 Busan 156302
78 동래구 Busan 444854
96 부산진구 Busan 690344
101 북구 Busan 493913
107 사상구 Busan 330533
109 사하구 Busan 522150
115 서구 Busan 180523
135 수영구 Busan 322032
154 연제구 Busan 354725
158 영도구 Busan 179922
203 중구 Busan 117134
242 해운대구 Busan 689901)- 단계4: 단계3의 결과를 이용하여 4년간에너지사용량이 가장 큰 2개의 구만 선택
data = pd.concat(list(map(lambda x: x[1].sort_values(by='4년간에너지사용량',ascending=False).reset_index(drop=True).iloc[:2],lst))).reset_index(drop=True)
data| 지역local | 지역global | 4년간에너지사용량 | |
|---|---|---|---|
| 0 | 부산진구 | Busan | 690344 |
| 1 | 해운대구 | Busan | 689901 |
| 2 | 흥덕구 | Chungcheongbuk-do | 533631 |
| 3 | 서원구 | Chungcheongbuk-do | 411988 |
| 4 | 서북구 | Chungcheongnam-do | 732292 |
| 5 | 아산시 | Chungcheongnam-do | 609252 |
| 6 | 달서구 | Daegu | 1029601 |
| 7 | 수성구 | Daegu | 828941 |
| 8 | 서구 | Daejeon | 899639 |
| 9 | 유성구 | Daejeon | 777654 |
| 10 | 원주시 | Gangwon-do | 731907 |
| 11 | 춘천시 | Gangwon-do | 605107 |
| 12 | 북구 | Gwangju | 841553 |
| 13 | 광산구 | Gwangju | 769056 |
| 14 | 부천시 | Gyeonggi-do | 1401396 |
| 15 | 화성시 | Gyeonggi-do | 1353424 |
| 16 | 구미시 | Gyeongsangbuk-do | 757997 |
| 17 | 경산시 | Gyeongsangbuk-do | 535216 |
| 18 | 김해시 | Gyeongsangnam-do | 882701 |
| 19 | 양산시 | Gyeongsangnam-do | 606947 |
| 20 | 서구 | Incheon | 990225 |
| 21 | 남동구 | Incheon | 942758 |
| 22 | 제주시 | Jeju-do | 472036 |
| 23 | 서귀포시 | Jeju-do | 149688 |
| 24 | 완산구 | Jeollabuk-do | 722580 |
| 25 | 덕진구 | Jeollabuk-do | 629929 |
| 26 | 순천시 | Jeollanam-do | 454538 |
| 27 | 여수시 | Jeollanam-do | 437734 |
| 28 | 세종시 | Sejongsi | 600744 |
| 29 | 강남구 | Seoul | 1951762 |
| 30 | 송파구 | Seoul | 1594228 |
| 31 | 남구 | Ulsan | 607820 |
| 32 | 중구 | Ulsan | 395158 |
- 단계5: 시각화
(풀이2) – 수강생중 한명인 김진실 학생의 풀이. 학생의 동의하에 코드를 공개함.
- 단계1: 시각화에 사용할 코드 정리
- 단계2: 시각화
풀이1,풀이2의 비교
제가 본래 의도한 풀이1보다 김진실 학생이 제안한 풀이2가 더 좋은 풀이라 생각합니다. 왜냐하면
- 에너지사용량 순서로 정렬이 되어있어 시각화가 좀 더 예쁘게 나오고 (주관적인 생각입니다..)
- 코드가 훨씬 간결하기
때문입니다. 풀이2의 아이디어는 sort_values와 groupby의 순서로 바꾸어도 상관없다는 아이디어에서 출발합니다. 원래는 그룹핑을 한 뒤에 정렬을 하고 가장 값이 큰 2개를 뽑도록 문제가 구성되어 있는데 사실 정렬을 먼저하고 그룹핑을 한뒤 값이 가장 큰 2개의 지역을 뽑아도 결과는 같습니다. 이는 sort_values 함수가 가지는 특이한 성질1 때문에 성립합니다. (만약에 데이터를 그룹별로 묶은뒤에 소비량이 가장 큰 2개의 구를 뽑는 문제가 아니라 그룹별로 묶은뒤에 Q1,Q3 값을 뽑아서 시각하라는 문제였다면 이 방법대로 풀 수가 없겠죠)
풀이1은 그룹별로 묶은 뒤에 그 그룹별로 어떠한 함수 \(f\)를 취하고 싶을 경우 활용될 수 있는 일반적인 풀이입니다. (말그대로 데이터를 그룹별로 쪼개고, 어떠한 연산을 취하고, 그 뒤에 다시 concat으로 합치는 과정입니다) 풀이2보다 코드가 좀 더 길지만 확장성이 좋다는 면에서는 장점이 있습니다.
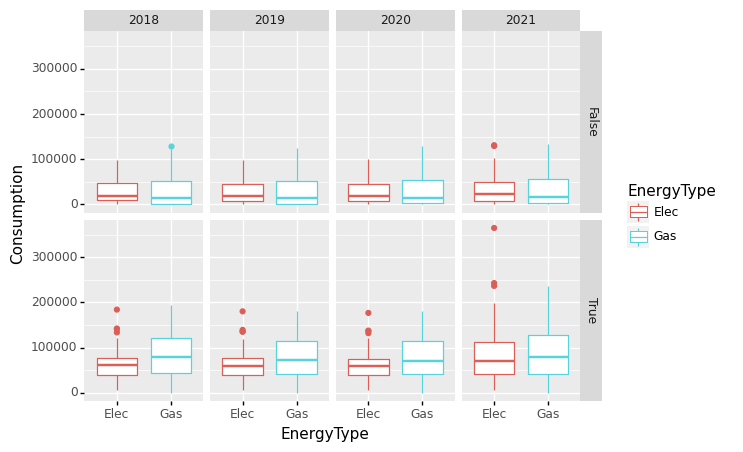
(4) ‘Seoul’, ‘Incheon’, ‘Gyeonggi-do’ 지역을 수도권으로 그 외의 지역은 비수도권으로 구분하라. 아래의 시각화 예시를 참고하여 수도관과 비 수도권의 전기와 도시가스사용량을 시각화하라.
(풀이)
- 단계1: 시각화를 위한 데이터정리
data= df.assign(MetropolitanArea=list(map(lambda x: x in ['Seoul', 'Incheon', 'Gyeonggi-do'],df['지역global'])))\
.rename({'전기':'Elec','도시가스':'Gas','연도':'Year'},axis=1)\
.loc[:,['Elec','Gas','Year','MetropolitanArea']]\
.set_index(['Year','MetropolitanArea'])\
.stack()\
.reset_index()\
.rename({'level_2':'EnergyType',0:'Consumption'},axis=1)
data| Year | MetropolitanArea | EnergyType | Consumption | |
|---|---|---|---|---|
| 0 | 2018 | True | Elec | 64818 |
| 1 | 2018 | True | Gas | 82015 |
| 2 | 2018 | True | Elec | 81672 |
| 3 | 2018 | True | Gas | 75260 |
| 4 | 2018 | True | Elec | 52659 |
| ... | ... | ... | ... | ... |
| 1995 | 2020 | False | Gas | 1639 |
| 1996 | 2021 | False | Elec | 103217 |
| 1997 | 2021 | False | Gas | 25689 |
| 1998 | 2021 | False | Elec | 37884 |
| 1999 | 2021 | False | Gas | 2641 |
2000 rows × 4 columns
- 단계2: 시각화
3. 심슨의 역설 (20점)
아래는 1973년 가을학기 버클리대학의 입학통계이다.
pd.read_csv("https://raw.githubusercontent.com/guebin/DV2022/master/posts/Simpson.csv",index_col=0,header=[0,1])| male | female | |||
|---|---|---|---|---|
| fail | pass | fail | pass | |
| A | 314 | 511 | 19 | 89 |
| B | 208 | 352 | 7 | 18 |
| C | 204 | 121 | 391 | 202 |
| D | 279 | 138 | 244 | 131 |
| E | 137 | 54 | 299 | 94 |
| F | 149 | 224 | 103 | 238 |
(1) 남녀합격률을 plotly를 사용하여 시각화 하라.
(풀이)
- 단계0: 강의노트와 동일한 방식으로 df, data 생성
df=pd.read_csv("https://raw.githubusercontent.com/guebin/DV2022/master/posts/Simpson.csv",index_col=0,header=[0,1])\
.stack().stack().reset_index()\
.rename({'level_0':'department','level_1':'result','level_2':'gender',0:'count'},axis=1)
df.head()| department | result | gender | count | |
|---|---|---|---|---|
| 0 | A | fail | female | 19 |
| 1 | A | fail | male | 314 |
| 2 | A | pass | female | 89 |
| 3 | A | pass | male | 511 |
| 4 | B | fail | female | 7 |
data= df.groupby(['gender','result']).agg({'count':np.sum}).reset_index()\
.merge(df.groupby('gender').agg({'count':np.sum}).reset_index().rename({'count':'count2'},axis=1))\
.eval('rate = count/count2').query('result=="pass"')
data.head()| gender | result | count | count2 | rate | |
|---|---|---|---|---|---|
| 1 | female | pass | 772 | 1835 | 0.420708 |
| 3 | male | pass | 1400 | 2691 | 0.520253 |
- 단계1: 소수점처리
| gender | result | count | count2 | rate | |
|---|---|---|---|---|---|
| 1 | female | pass | 772 | 1835 | 42.07 |
| 3 | male | pass | 1400 | 2691 | 52.03 |
- 단계2: 시각화
data.assign(rate = np.round(data['rate']*100,2))\
.plot.bar(backend='plotly',y='gender',x='rate',color='gender',barmode='group',text='rate')(2) 학과별 남녀합격률을 plotly를 사용하여 시각화 하라.
(풀이)
- 단계0: 강의노트와 동일한 방식으로 data2 생성
data2=df.merge(df.groupby(['department','gender']).agg({'count':np.sum}).reset_index().rename({'count':'count2'},axis=1))\
.eval('rate = count/count2').query('result=="pass"')
data2| department | result | gender | count | count2 | rate | |
|---|---|---|---|---|---|---|
| 1 | A | pass | female | 89 | 108 | 0.824074 |
| 3 | A | pass | male | 511 | 825 | 0.619394 |
| 5 | B | pass | female | 18 | 25 | 0.720000 |
| 7 | B | pass | male | 352 | 560 | 0.628571 |
| 9 | C | pass | female | 202 | 593 | 0.340641 |
| 11 | C | pass | male | 121 | 325 | 0.372308 |
| 13 | D | pass | female | 131 | 375 | 0.349333 |
| 15 | D | pass | male | 138 | 417 | 0.330935 |
| 17 | E | pass | female | 94 | 393 | 0.239186 |
| 19 | E | pass | male | 54 | 191 | 0.282723 |
| 21 | F | pass | female | 238 | 341 | 0.697947 |
| 23 | F | pass | male | 224 | 373 | 0.600536 |
- 단계1: 시각화
Footnotes
groupby와 순서를 교환해도 상관없다는 성질↩︎