기말고사 해설




import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
tnp.experimental_enable_numpy_behavior()
%load_ext tensorboard
import graphviz
def gv(s): return graphviz.Source('digraph G{ rankdir="LR"'+ s + ';}')
(1) tf.keras.datasets.fashion_mnist.load_data()을 이용하여 fashion_mnist 자료를 불러온 뒤 아래의 네트워크를 이용하여 적합하라. (6점)
- 평가지표로 accuracy를 이용할 것
- epoch은 10으로 설정할 것
- optimizer는 adam을 이용할 것
gv('''
splines=line
subgraph cluster_1{
style=filled;
color=lightgrey;
"x1"
"x2"
".."
"x784"
label = "Layer 0"
}
subgraph cluster_2{
style=filled;
color=lightgrey;
"x1" -> "node1"
"x2" -> "node1"
".." -> "node1"
"x784" -> "node1"
"x1" -> "node2"
"x2" -> "node2"
".." -> "node2"
"x784" -> "node2"
"x1" -> "..."
"x2" -> "..."
".." -> "..."
"x784" -> "..."
"x1" -> "node20"
"x2" -> "node20"
".." -> "node20"
"x784" -> "node20"
label = "Layer 1: relu"
}
subgraph cluster_3{
style=filled;
color=lightgrey;
"node1" -> "node1 "
"node2" -> "node1 "
"..." -> "node1 "
"node20" -> "node1 "
"node1" -> "node2 "
"node2" -> "node2 "
"..." -> "node2 "
"node20" -> "node2 "
"node1" -> "... "
"node2" -> "... "
"..." -> "... "
"node20" -> "... "
"node1" -> "node30 "
"node2" -> "node30 "
"..." -> "node30 "
"node20" -> "node30 "
label = "Layer 2: relu"
}
subgraph cluster_4{
style=filled;
color=lightgrey;
"node1 " -> "y10"
"node2 " -> "y10"
"... " -> "y10"
"node30 " -> "y10"
"node1 " -> "y1"
"node2 " -> "y1"
"... " -> "y1"
"node30 " -> "y1"
"node1 " -> "."
"node2 " -> "."
"... " -> "."
"node30 " -> "."
label = "Layer 3: softmax"
}
''')
(풀이)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
X = tf.constant(x_train.reshape(-1,28,28,1),dtype=tf.float64)
y = tf.keras.utils.to_categorical(y_train)
XX = tf.constant(x_test.reshape(-1,28,28,1),dtype=tf.float64)
yy = tf.keras.utils.to_categorical(y_test)
net = tf.keras.Sequential()
net.add(tf.keras.layers.Flatten())
net.add(tf.keras.layers.Dense(20,activation='relu'))
net.add(tf.keras.layers.Dense(30,activation='relu'))
net.add(tf.keras.layers.Dense(10,activation='softmax'))
net.compile(optimizer='adam',loss=tf.losses.categorical_crossentropy,metrics='accuracy')
net.fit(X,y,epochs=10)
(2) (1)에서 적합된 네트워크를 이용하여 test data의 accuracy를 구하라. (6점)
(풀이)
net.evaluate(XX,yy)
(3) train set에서 20%의 자료를 validation 으로 분리하여 50에폭동안 학습하라. 텐서보드를 이용하여 train accuracy와 validation accuracy를 시각화 하고 결과를 해석하라. 오버피팅이라고 볼 수 있는가? (6점)
(풀이)
net = tf.keras.Sequential()
net.add(tf.keras.layers.Flatten())
net.add(tf.keras.layers.Dense(20,activation='relu'))
net.add(tf.keras.layers.Dense(30,activation='relu'))
net.add(tf.keras.layers.Dense(10,activation='softmax'))
net.compile(optimizer='adam',loss=tf.losses.categorical_crossentropy,metrics='accuracy')
cb1 = tf.keras.callbacks.TensorBoard()
net.fit(X,y,epochs=50,validation_split=0.2,callbacks=cb1,verbose=0)
validation loss가 줄어들다가 증가한다면 오버피팅으로 판단한다. 그렇지 않으면 오버핏이 아니다.
(4) (3)에서 적합된 네트워크를 이용하여 test data의 accuracy를 구하라. (2)의 결과와 비교하라. (6점)
(풀이)
net.evaluate(XX,yy)
accuracy가 상승함. 따라서 에폭을 늘린것이 유의미한 결정이라 볼 수 있다.
(5) 조기종료기능을 이용하여 (3)의 네트워크를 다시 학습하라. 학습결과를 텐서보드를 이용하여 시각화 하라. (6점)
- patience=3 으로 설정할 것
(풀이)
!rm -rf logs
net = tf.keras.Sequential()
net.add(tf.keras.layers.Flatten())
net.add(tf.keras.layers.Dense(20,activation='relu'))
net.add(tf.keras.layers.Dense(30,activation='relu'))
net.add(tf.keras.layers.Dense(10,activation='softmax'))
net.compile(optimizer='adam',loss=tf.losses.categorical_crossentropy,metrics='accuracy')
cb1 = tf.keras.callbacks.TensorBoard()
cb2 = tf.keras.callbacks.EarlyStopping(patience=3)
net.fit(X,y,epochs=50,verbose=0,validation_split=0.2,callbacks=[cb1,cb2])
#%tensorboard --logdir logs --host 0.0.0.0
(1) tf.keras.datasets.fashion_mnist.load_data()을 이용하여 fashion_mnist 자료를 불러온 뒤 아래의 네트워크를 이용하여 적합하라. (10점)
- 이때 n1=6, n2=16, n3=120 으로 설정한다, 드랍아웃비율은 20%로 설정한다.
net.summary()를 출력하여 설계결과를 확인하라.
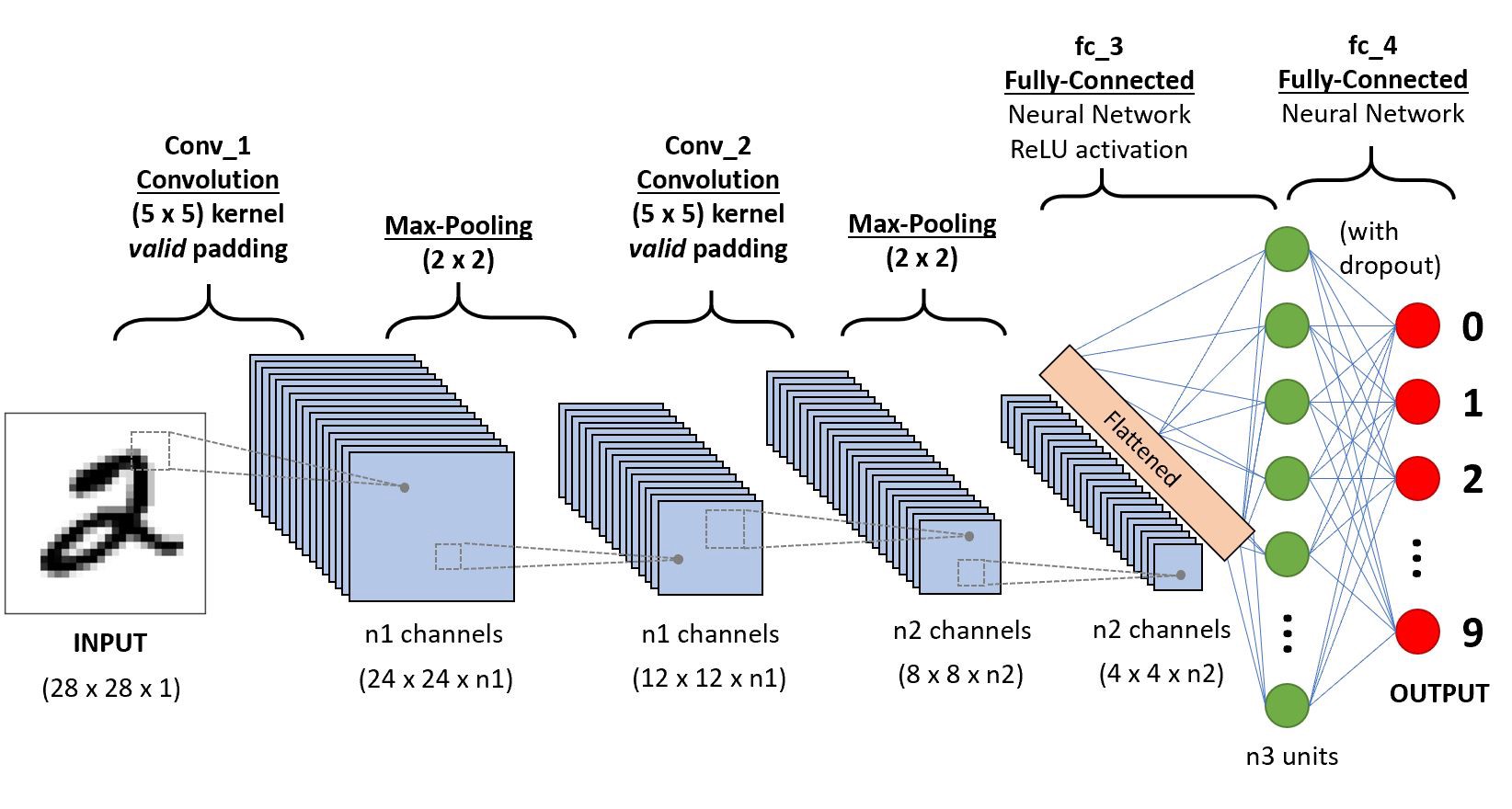
(풀이)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
X = tf.constant(x_train.reshape(-1,28,28,1),dtype=tf.float64)
y = tf.keras.utils.to_categorical(y_train)
XX = tf.constant(x_test.reshape(-1,28,28,1),dtype=tf.float64)
yy = tf.keras.utils.to_categorical(y_test)
net = tf.keras.Sequential()
net.add(tf.keras.layers.Conv2D(6,(5,5),activation='relu')) # activation이 relu임은 그림에서 명시되지 않았으므로 생략해도 무방함.
net.add(tf.keras.layers.MaxPool2D())
net.add(tf.keras.layers.Conv2D(16,(5,5),activation='relu')) # activation이 relu임은 그림에서 명시되지 않았으므로 생략해도 무방함.
net.add(tf.keras.layers.MaxPool2D())
net.add(tf.keras.layers.Flatten())
net.add(tf.keras.layers.Dense(120,activation='relu'))
net.add(tf.keras.layers.Dropout(0.2))
net.add(tf.keras.layers.Dense(10,activation='softmax'))
net.compile(optimizer='adam',loss=tf.losses.categorical_crossentropy,metrics='accuracy')
net.fit(X,y,epochs=5)
net.summary()
(2) n1=(6,64,128), n2=(16,256)에 대하여 test set의 loss가 최소화되는 조합을 찾아라. 결과를 텐서보드로 시각화하는 코드를 작성하라. (20점)
- epoc은 3회로 한정한다.
- validation_split은 0.2로 설정한다.
(풀이)
from tensorboard.plugins.hparams import api as hp
!rm -rf logs
for n1 in [6,64,128]:
for n2 in [16,256]:
logdir = 'logs/hp_{}_{}'.format(n1,n2)
with tf.summary.create_file_writer(logdir).as_default():
net = tf.keras.Sequential()
net.add(tf.keras.layers.Conv2D(n1,(5,5),activation='relu'))
net.add(tf.keras.layers.MaxPool2D())
net.add(tf.keras.layers.Conv2D(n2,(5,5),activation='relu'))
net.add(tf.keras.layers.MaxPool2D())
net.add(tf.keras.layers.Flatten())
net.add(tf.keras.layers.Dense(120,activation='relu'))
net.add(tf.keras.layers.Dropout(0.2))
net.add(tf.keras.layers.Dense(10,activation='softmax'))
net.compile(optimizer='adam',loss=tf.losses.categorical_crossentropy,metrics='accuracy')
cb3 = hp.KerasCallback(logdir, {'n1':n1, 'n2':n2})
net.fit(X,y,epochs=3,validation_split=0.2,callbacks=cb3)
tf.summary.scalar('loss(테스트셋)',net.evaluate(XX,yy)[0], step=1)
tf.keras.datasets.cifar10.load_data()을 이용하여 CIFAR10을 불러온 뒤 적당한 네트워크를 사용하여 적합하라.
- 결과를 텐서보드로 시각화할 필요는 없다.
- 자유롭게 모형을 설계하여 적합하라.
- test set의 accuracy가 70%이상인 경우만 정답으로 인정한다.
(풀이)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
X=x_train.reshape(-1,32,32,3)/255
y=tf.keras.utils.to_categorical(y_train)
XX=x_test.reshape(-1,32,32,3)/255
yy=tf.keras.utils.to_categorical(y_test)
net = tf.keras.Sequential()
net.add(tf.keras.layers.Conv2D(128,(2,2),activation='relu'))
net.add(tf.keras.layers.Conv2D(128,(2,2),activation='relu'))
net.add(tf.keras.layers.MaxPool2D())
net.add(tf.keras.layers.Conv2D(256,(2,2),activation='relu'))
net.add(tf.keras.layers.Conv2D(256,(2,2),activation='relu'))
net.add(tf.keras.layers.MaxPool2D())
net.add(tf.keras.layers.Flatten())
net.add(tf.keras.layers.Dense(256,activation='relu'))
net.add(tf.keras.layers.Dense(10,activation='softmax'))
net.compile(optimizer='adam',loss=tf.losses.categorical_crossentropy,metrics='accuracy')
net.fit(X,y,epochs=5,validation_split=0.2)
net.evaluate(XX,yy)
(1) (1,128,128,3)의 shape을 가진 텐서가 tf.keras.layers.Conv2D(5,(2,2))으로 만들어진 커널을 통과할시 나오는 shape은?
(풀이)
l=tf.keras.layers.Conv2D(5,(2,2))
x=tnp.arange(1*128*128*3).reshape(1,128,128,3)/255
l(x).shape
(2) (1,24,24,16)의 shape을 가진 텐서가 tf.keras.layers.Flatten()을 통과할때 나오는 텐서의 shape은?
(풀이)
l=tf.keras.layers.Flatten()
x=tnp.arange(1*24*24*16).reshape(1,24,24,16)/255
l(x).shape
(3)-(4)
아래와 같은 모형을 고려하자.
$$y_i= \beta_0 + \sum_{k=1}^{5} \beta_k \cos(k t_i)+\epsilon_i$$
여기에서 $t=(t_1,\dots,t_{1000})=$ np.linspace(0,5,1000) 이다. 그리고 $\epsilon_i \sim i.i.d~ N(0,\sigma^2)$, 즉 서로 독립인 표준정규분포에서 추출된 샘플이다. 위의 모형에서 아래와 같은 데이터를 관측했다고 가정하자. ($\beta_0,\dots,\beta_5$의 참값은 각각 -2, 3, 1, 0, 0, 0.5 이다.)
np.random.seed(43052)
t= np.linspace(0,5,1000)
y = -2+ 3*np.cos(t) + 1*np.cos(2*t) + 0.5*np.cos(5*t) + np.random.randn(1000)*0.2
plt.plot(t,y,'.',alpha=0.1)

(3) 모형에 대한 설명 중 옳은 것을 모두 골라라.
(하영) 이 모형의 경우 MSEloss를 최소화하는 $\hat{\beta}_0,\dots,\hat{\beta}_5$를 구하는것은 최대우도함수를 최대화하는 $\hat{\beta}_0,\dots,\hat{\beta}_5$를 구하는 것과 같다.
(재인) 하영의 말이 옳은 이유는 오차항이 정규분포를 따른다는 가정이 있기 때문이다.
~(서연) 이 모형에서 적절한 학습률이 선택되더라도 경사하강법을 이용하면 MSEloss를 최소화하는 $\hat{\beta}_0,\dots,\hat{\beta}_5$를 종종 구할 수 없는 문제가 생긴다. 왜냐하면 손실함수가 convex하지 않아서 local minimum에 빠질 위험이 있기 때문이다.~
- 이 모형은 ${\bf y}={\bf X}{\boldsymbol \beta}+{\boldsymbol \epsilon}$꼴이므로 선형모형으로 볼 수 있다. 따라서 제곱오차손실을 사용할 경우 손실함수는 항상 convex하다.
~(규빈) 만약에 경사하강법 대신 확률적 경사하강법을 쓴다면 local minimum을 언제나 탈출 할 수 있다. 따라서 서연이 언급한 문제점은 생기지 않는다.~
- 확률적경사하강법을 쓴다고 해도 local minimum에 빠지는 문제가 완전히 해결되지는 않는다.
(4) 다음은 위의 모형을 학습한 결과이다. 옳게 해석한 것을 모두 고르시오.
y = y.reshape(1000,1)
x1 = np.cos(t)
x2 = np.cos(2*t)
x3 = np.cos(3*t)
x4 = np.cos(4*t)
x5 = np.cos(5*t)
X = tf.stack([x1,x2,x3,x4,x5],axis=1)
net = tf.keras.Sequential()
net.add(tf.keras.layers.Dense(1))
net.compile(loss='mse',optimizer='adam')
net.fit(X,y,epochs=500,batch_size=100, validation_split=0.45,verbose=0)
plt.plot(y,'.',alpha=0.1)
plt.plot(net(X),'--')

(재인) 처음 550개의 데이터만 학습하고 이후의 450개의 데이터는 학습하지 않고 validation으로 이용하였다.
(서연) validation에서의 적합결과가 좋지 않다.
~(규빈) validation의 적합결과가 좋지 않기 때문에 오버피팅을 의심할 수 있다. 따라서 만약에 네트워크에 드랍아웃층을 추가한다면 오버피팅을 방지하는 효과가 있어 validation의 loss가 줄어들 것이다.~
- 오버핏이 아닌 상황이다. (강의노트 참고)
(하영) 이 모형의 경우 더 많은 epoch으로 학습한다면 train loss와 validation loss를 둘 다 줄일 수 있다.
(5) 다음을 잘 읽고 참 거짓을 판별하라.
Convolution은 선형변환이다.
~CNN을 이용하면 언제나 손실함수를 MSEloss로 선택해야 한다.~
- 그런법은 없다.
~CNN은 adam optimizer를 통해서만 최적화할 수 있다.~
- 그런법은 없다.
~이미지자료는 CNN을 이용하여서만 분석할 수 있으며 DNN으로는 분석불가능하다.~
- DNN으로도 이미지자료를 분석한다. (강의노트 참고)
~CNN은 칼라이미지일 경우에만 적용가능하다.~
- 흑백이미지일 경우도 적용가능하다.