lambda, map, 판다스–인덱싱(1)
강의영상
https://youtube.com/playlist?list=PLQqh36zP38-wxe8lWPtjKVy-D10Ul4E_7
imports
lambda, map (\(\star\))
lambda
- 예제1: 람다표현식(lambda expression)자체가 하나의 오브젝트임
<function __main__.<lambda>(x)>- “lambda x: (x-2)**2” 는 \(lambda(x)=(x-2)^2\)의 느낌으로 기억하면 쉬움
(사용방법)
- 예제2: 람다표현식에 이름을 줄 수 있음.
위의 코드는 아래와 같다.
- 예제3: 조건부 출력
- 예제4: 람다표현식들의 리스트

- 예제5: 람다표현식들의 딕셔너리
{'f1': <function __main__.<lambda>(x)>,
'f2': <function __main__.<lambda>(x)>,
'f3': <function __main__.<lambda>(x)>}
- 예제6: 람다표현식을 리턴하는 함수 (함수를 리턴하는 함수)
(예비학습) 함수 \(g(x)\)가 정의되어 있을때 \(\frac{d}{dx}g(x)\)의 값을 계산해보기
(목표) 도함수를 구해주는 derivate 함수를 정의하자. 이 함수는 임의의 함수 g를 입력으로 받으면, g의 도함수(gg)가 리턴되는 기능을 가진다.
(사용1)
plt.plot(x,g(x),label=r'$f(x)=sin(x)$')
plt.plot(x,gg(x),label=r'$\frac{d}{dx}f(x)=cos(x)$')
plt.legend(fontsize=15)<matplotlib.legend.Legend at 0x7fa54cde3a50>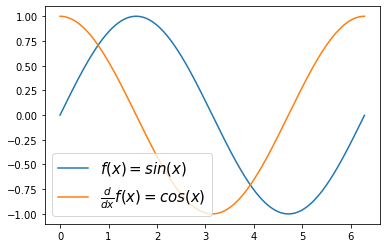
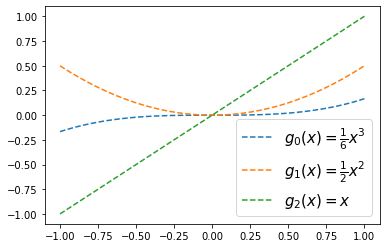
(사용2)
x = np.linspace(-1,1,100)
plt.plot(x,g0(x),'--',label=r'$g_0(x)=\frac{1}{6}x^3$')
plt.plot(x,g1(x),'--',label=r'$g_1(x)=\frac{1}{2}x^2$')
plt.plot(x,g2(x),'--',label=r'$g_2(x)=x$')
plt.legend(fontsize=15)<matplotlib.legend.Legend at 0x7fa54cccc2d0>
- 예제7: 예제6의 다른표현
(사용1)
plt.plot(x,g(x),label=r'$f(x)=sin(x)$')
plt.plot(x,gg(x),label=r'$\frac{d}{dx}f(x)=cos(x)$')
plt.legend(fontsize=15)<matplotlib.legend.Legend at 0x7fa54cdb1b10>
(사용2)
map
- 개념: $(f,[x_1,x_2,,x_n] )=$
- 예제1:
(다른구현1)
(다른구현2)
(다른구현3)
(다른구현4)–최악
(다른구현5)–더 최악
- 예제2: 문자열을 입력으로 받고 대문자이면 True, 소문자이면 False
입력: A,B,C,a,b,c
출력: T,T,T,F,F,F- 예제3: 두개의 입력을 받는 함수 (map을 이용하는 것이 리스트 컴프리헨션보다 조금 편한것 같다)
(다른구현)– 리스트컴프리헨션
- 예제4: map은 “하나의 함수에 다양한 입력”을 적용하는 경우에만 사용가능, 리스트컴프리헨션은 “다양한 함수에 다양한 입력” 지원
map으로 구현시도 \(\to\) 실패
리스트컴프리헨션으로 구현시도 \(\to\) 성공
- 종합: map과 리스트컴프리헨션과 비교
- map은 for문을 위한 \(i\)등의 인덱스를 쓰지 않지만 리스트컴프리헨션은 필요함
- map은 좀더 리스트컴프리헨션보다 제약적으로 사용할 수 밖에 없음.
판다스: 인덱싱 1단계– 인덱싱의 4가지 컨셉
데이터프레임 준비
- 데이터준비
| att | rep | mid | fin | |
|---|---|---|---|---|
| 0 | 65 | 45 | 0 | 10 |
| 1 | 95 | 30 | 60 | 10 |
| 2 | 65 | 85 | 15 | 20 |
| 3 | 55 | 35 | 35 | 5 |
| 4 | 80 | 60 | 55 | 70 |
| ... | ... | ... | ... | ... |
| 195 | 55 | 70 | 40 | 95 |
| 196 | 65 | 85 | 25 | 85 |
| 197 | 85 | 85 | 100 | 10 |
| 198 | 80 | 65 | 35 | 60 |
| 199 | 50 | 95 | 45 | 85 |
200 rows × 4 columns
- 앞으로는 위와 같은 df형태를 가정할 것이다. 즉 column의 이름은 문자열, row의 이름은 0부터 시작하는 정수로 가정한다.
- 아래와 같은 형태는 일단 생각하지 않는다.
df의 4가지 컨셉
- 원소에 접근하는 4가지 방법: ., [], .iloc[], .loc[]
컨셉1: 클래스느낌
- 컨셉1: df는 인스턴스이다. 그리고 df.att, df.rep,df.mid, df.fin 와 같이 col이름에 대응하는 속성이 있다.
0 10
1 10
2 20
3 5
4 70
..
195 95
196 85
197 10
198 60
199 85
Name: fin, Length: 200, dtype: int64- 언제유용? col의 이름을 대충 알고 있을 경우 자동완성으로 쉽게 선택가능
컨셉2: 딕셔너리 + \(\alpha\) 느낌
- 컨셉2: df는 컬럼이름이 key, 컬럼의데이터가 value가 되는 dictionary로 이해할 수 있다. 즉 아래의 dct와 같은 딕셔너리로 이해할 수 있다.
(예시) .keys() 메소드를 이용하여 컬럼들의 이름을 살펴볼 수 있음.
(dict_keys(['att', 'rep', 'mid', 'fin']),
Index(['att', 'rep', 'mid', 'fin'], dtype='object'))# col indexing
- 예시1: dct가 가능하면 df도 가능하다.
0 65
1 95
2 65
3 55
4 80
..
195 55
196 65
197 85
198 80
199 50
Name: att, Length: 200, dtype: int64- 예시2: dct가 가능하면 df도 가능하다. (2)
0 65
1 95
2 65
3 55
4 80
..
195 55
196 65
197 85
198 80
199 50
Name: att, Length: 200, dtype: int64- 예시3: dct에서 불가능하지만 df에서 가능한것도 있다.
| att | rep | |
|---|---|---|
| 0 | 65 | 45 |
| 1 | 95 | 30 |
| 2 | 65 | 85 |
| 3 | 55 | 35 |
| 4 | 80 | 60 |
| ... | ... | ... |
| 195 | 55 | 70 |
| 196 | 65 | 85 |
| 197 | 85 | 85 |
| 198 | 80 | 65 |
| 199 | 50 | 95 |
200 rows × 2 columns
- 예시4: dct에서 불가능하지만 df에서 가능한것도 있다. (2)
# row indexing
- 예시5: dct에서 불가능하지만 df에서 가능한것도 있다. (3)
컨셉3: 넘파이느낌
- 컨셉3: df.iloc은 넘파이에러이처럼 생각가능하다. 즉 아래의 arr와 같은 넘파이어레이로 생각가능하다.
# row indexing
- 예시1: 단일레이블
- 예시2: 레이블의 리스트
array([[65, 45, 0, 10],
[95, 30, 60, 10],
[65, 85, 15, 20]])| att | rep | mid | fin | |
|---|---|---|---|---|
| 0 | 65 | 45 | 0 | 10 |
| 1 | 95 | 30 | 60 | 10 |
| 2 | 65 | 85 | 15 | 20 |
- 예시3: 슬랑이싱
array([[65, 45, 0, 10],
[95, 30, 60, 10],
[65, 85, 15, 20]])# col indexing
- 예시1: 단일레이블
0 65
1 95
2 65
3 55
4 80
..
195 55
196 65
197 85
198 80
199 50
Name: att, Length: 200, dtype: int64- 예시2: 레이블의 리스트
| att | mid | |
|---|---|---|
| 0 | 65 | 0 |
| 1 | 95 | 60 |
| 2 | 65 | 15 |
| 3 | 55 | 35 |
| 4 | 80 | 55 |
| ... | ... | ... |
| 195 | 55 | 40 |
| 196 | 65 | 25 |
| 197 | 85 | 100 |
| 198 | 80 | 35 |
| 199 | 50 | 45 |
200 rows × 2 columns
- 예시3: 슬랑이싱
# row + col indexing
컨셉4: 데이터프레임 느낌
- 컨셉4: df.loc은 새로운 느낌.. (R에 익숙하면 df.loc이 dataframe 혹은 티블느낌이라고 보시면 됩니다)
# A tibble: 5 × 2
model year
<chr> <int>
1 a4 1999
2 a4 1999
3 a4 2008
4 a4 2008
5 a4 1999# row indexing
- 예시1: 단일레이블
- 예시2: 레이블의 리스트
| att | rep | mid | fin | |
|---|---|---|---|---|
| 0 | 65 | 45 | 0 | 10 |
| 1 | 95 | 30 | 60 | 10 |
| 2 | 65 | 85 | 15 | 20 |
- 예시3: 슬라이싱 (끝점포함 O)
# col indexing
- 예시1: 단일레이블
0 65
1 95
2 65
3 55
4 80
..
195 55
196 65
197 85
198 80
199 50
Name: att, Length: 200, dtype: int64- 예시2: 레이블의 리스트
| att | mid | |
|---|---|---|
| 0 | 65 | 0 |
| 1 | 95 | 60 |
| 2 | 65 | 15 |
| 3 | 55 | 35 |
| 4 | 80 | 55 |
| ... | ... | ... |
| 195 | 55 | 40 |
| 196 | 65 | 25 |
| 197 | 85 | 100 |
| 198 | 80 | 35 |
| 199 | 50 | 45 |
200 rows × 2 columns
- 예시3: 슬라이싱 (끝점포함 O)
# row + col indexing
컨셉1~4 정리
. |
[] |
.iloc |
.loc |
|
|---|---|---|---|---|
| row/단일레이블 | X | X | O | O |
| col/단일레이블 | O | O | O | O |
| row/레이블리스트 | X | X | O | O |
| col/레이블리스트 | X | O | O | O |
| row/슬라이싱 | X | O | O | O |
| col/슬라이싱 | X | X | O | O |
- col 이름을 알아야하는 부담감 - . : 앞글자만 대충 알아도 자동완성 가능 - []: 정확한 col 이름을 알아야 함 - .loc: 보통 정확한 col 이름을 알아야 하지만 슬라이싱 이용시 양 끝의 컬럼이름만 알면 무방 - .iloc: 정확한 col 이름을 몰라도 번호로 인덱싱 가능
- 자주하는 실수
판다스: 인덱싱 2단계– 필터링(특정조건에 맞는 row를 선택)
att > 90 and rep < 50
- 방법1: .query()를 이용
| att | rep | mid | fin | |
|---|---|---|---|---|
| 1 | 95 | 30 | 60 | 10 |
| 12 | 95 | 35 | 0 | 25 |
| 48 | 95 | 45 | 35 | 80 |
| 56 | 95 | 25 | 95 | 90 |
| 78 | 95 | 45 | 90 | 35 |
| 107 | 100 | 30 | 60 | 65 |
| 112 | 100 | 35 | 70 | 0 |
| 113 | 95 | 45 | 55 | 65 |
| 163 | 100 | 25 | 10 | 20 |
| 174 | 100 | 40 | 40 | 15 |
| 176 | 100 | 30 | 70 | 70 |
| 184 | 100 | 30 | 30 | 85 |
| 190 | 95 | 35 | 40 | 95 |
| 192 | 100 | 40 | 80 | 80 |
| att | rep | mid | fin | |
|---|---|---|---|---|
| 1 | 95 | 30 | 60 | 10 |
| 12 | 95 | 35 | 0 | 25 |
| 48 | 95 | 45 | 35 | 80 |
| 56 | 95 | 25 | 95 | 90 |
| 78 | 95 | 45 | 90 | 35 |
| 107 | 100 | 30 | 60 | 65 |
| 112 | 100 | 35 | 70 | 0 |
| 113 | 95 | 45 | 55 | 65 |
| 163 | 100 | 25 | 10 | 20 |
| 174 | 100 | 40 | 40 | 15 |
| 176 | 100 | 30 | 70 | 70 |
| 184 | 100 | 30 | 30 | 85 |
| 190 | 95 | 35 | 40 | 95 |
| 192 | 100 | 40 | 80 | 80 |
| att | rep | mid | fin | |
|---|---|---|---|---|
| 1 | 95 | 30 | 60 | 10 |
| 12 | 95 | 35 | 0 | 25 |
| 48 | 95 | 45 | 35 | 80 |
| 56 | 95 | 25 | 95 | 90 |
| 78 | 95 | 45 | 90 | 35 |
| 107 | 100 | 30 | 60 | 65 |
| 112 | 100 | 35 | 70 | 0 |
| 113 | 95 | 45 | 55 | 65 |
| 163 | 100 | 25 | 10 | 20 |
| 174 | 100 | 40 | 40 | 15 |
| 176 | 100 | 30 | 70 | 70 |
| 184 | 100 | 30 | 30 | 85 |
| 190 | 95 | 35 | 40 | 95 |
| 192 | 100 | 40 | 80 | 80 |
- 방법2: [], .iloc, .loc
df[(df.att > 90)&(df.rep < 50)]
df.loc[(df.att > 90)&(df.rep < 50)]
df.iloc[list((df.att > 90)&(df.rep < 50))]| att | rep | mid | fin | |
|---|---|---|---|---|
| 1 | 95 | 30 | 60 | 10 |
| 12 | 95 | 35 | 0 | 25 |
| 48 | 95 | 45 | 35 | 80 |
| 56 | 95 | 25 | 95 | 90 |
| 78 | 95 | 45 | 90 | 35 |
| 107 | 100 | 30 | 60 | 65 |
| 112 | 100 | 35 | 70 | 0 |
| 113 | 95 | 45 | 55 | 65 |
| 163 | 100 | 25 | 10 | 20 |
| 174 | 100 | 40 | 40 | 15 |
| 176 | 100 | 30 | 70 | 70 |
| 184 | 100 | 30 | 30 | 85 |
| 190 | 95 | 35 | 40 | 95 |
| 192 | 100 | 40 | 80 | 80 |
- 방법3: [], .iloc, .loc // map, lambda
df[list(map(lambda x,y: (x>90)&(y<50), df.att, df.rep))]
# df[map(lambda x,y: (x>90)&(y<50), df.att, df.rep)] # 이것은 불가능| att | rep | mid | fin | |
|---|---|---|---|---|
| 1 | 95 | 30 | 60 | 10 |
| 12 | 95 | 35 | 0 | 25 |
| 48 | 95 | 45 | 35 | 80 |
| 56 | 95 | 25 | 95 | 90 |
| 78 | 95 | 45 | 90 | 35 |
| 107 | 100 | 30 | 60 | 65 |
| 112 | 100 | 35 | 70 | 0 |
| 113 | 95 | 45 | 55 | 65 |
| 163 | 100 | 25 | 10 | 20 |
| 174 | 100 | 40 | 40 | 15 |
| 176 | 100 | 30 | 70 | 70 |
| 184 | 100 | 30 | 30 | 85 |
| 190 | 95 | 35 | 40 | 95 |
| 192 | 100 | 40 | 80 | 80 |
df.iloc[list(map(lambda x,y: (x>90)&(y<50), df.att, df.rep))]
df.iloc[map(lambda x,y: (x>90)&(y<50), df.att, df.rep)]| att | rep | mid | fin | |
|---|---|---|---|---|
| 1 | 95 | 30 | 60 | 10 |
| 12 | 95 | 35 | 0 | 25 |
| 48 | 95 | 45 | 35 | 80 |
| 56 | 95 | 25 | 95 | 90 |
| 78 | 95 | 45 | 90 | 35 |
| 107 | 100 | 30 | 60 | 65 |
| 112 | 100 | 35 | 70 | 0 |
| 113 | 95 | 45 | 55 | 65 |
| 163 | 100 | 25 | 10 | 20 |
| 174 | 100 | 40 | 40 | 15 |
| 176 | 100 | 30 | 70 | 70 |
| 184 | 100 | 30 | 30 | 85 |
| 190 | 95 | 35 | 40 | 95 |
| 192 | 100 | 40 | 80 | 80 |
df.loc[list(map(lambda x,y: (x>90)&(y<50), df.att, df.rep))]
df.loc[map(lambda x,y: (x>90)&(y<50), df.att, df.rep)]| att | rep | mid | fin | |
|---|---|---|---|---|
| 1 | 95 | 30 | 60 | 10 |
| 12 | 95 | 35 | 0 | 25 |
| 48 | 95 | 45 | 35 | 80 |
| 56 | 95 | 25 | 95 | 90 |
| 78 | 95 | 45 | 90 | 35 |
| 107 | 100 | 30 | 60 | 65 |
| 112 | 100 | 35 | 70 | 0 |
| 113 | 95 | 45 | 55 | 65 |
| 163 | 100 | 25 | 10 | 20 |
| 174 | 100 | 40 | 40 | 15 |
| 176 | 100 | 30 | 70 | 70 |
| 184 | 100 | 30 | 30 | 85 |
| 190 | 95 | 35 | 40 | 95 |
| 192 | 100 | 40 | 80 | 80 |
att > mean(att)
- 방법1: .query()를 이용
| att | rep | mid | fin | |
|---|---|---|---|---|
| 1 | 95 | 30 | 60 | 10 |
| 4 | 80 | 60 | 55 | 70 |
| 8 | 95 | 55 | 65 | 90 |
| 9 | 90 | 25 | 95 | 50 |
| 11 | 95 | 60 | 25 | 55 |
| ... | ... | ... | ... | ... |
| 184 | 100 | 30 | 30 | 85 |
| 190 | 95 | 35 | 40 | 95 |
| 192 | 100 | 40 | 80 | 80 |
| 197 | 85 | 85 | 100 | 10 |
| 198 | 80 | 65 | 35 | 60 |
95 rows × 4 columns
- 방법2: [], .iloc, .loc
| att | rep | mid | fin | |
|---|---|---|---|---|
| 1 | 95 | 30 | 60 | 10 |
| 4 | 80 | 60 | 55 | 70 |
| 8 | 95 | 55 | 65 | 90 |
| 9 | 90 | 25 | 95 | 50 |
| 11 | 95 | 60 | 25 | 55 |
| ... | ... | ... | ... | ... |
| 184 | 100 | 30 | 30 | 85 |
| 190 | 95 | 35 | 40 | 95 |
| 192 | 100 | 40 | 80 | 80 |
| 197 | 85 | 85 | 100 | 10 |
| 198 | 80 | 65 | 35 | 60 |
95 rows × 4 columns
- 방법3: [], .iloc, .loc // map, lambda
df[list(map(lambda x: x>df.att.mean() , df.att))]
# df[map(lambda x: x>df.att.mean() , df.att)] # 이것은 불가능| att | rep | mid | fin | |
|---|---|---|---|---|
| 1 | 95 | 30 | 60 | 10 |
| 4 | 80 | 60 | 55 | 70 |
| 8 | 95 | 55 | 65 | 90 |
| 9 | 90 | 25 | 95 | 50 |
| 11 | 95 | 60 | 25 | 55 |
| ... | ... | ... | ... | ... |
| 184 | 100 | 30 | 30 | 85 |
| 190 | 95 | 35 | 40 | 95 |
| 192 | 100 | 40 | 80 | 80 |
| 197 | 85 | 85 | 100 | 10 |
| 198 | 80 | 65 | 35 | 60 |
95 rows × 4 columns
df.iloc[list(map(lambda x: x>df.att.mean() , df.att))]
df.iloc[map(lambda x: x>df.att.mean() , df.att)]| att | rep | mid | fin | |
|---|---|---|---|---|
| 1 | 95 | 30 | 60 | 10 |
| 4 | 80 | 60 | 55 | 70 |
| 8 | 95 | 55 | 65 | 90 |
| 9 | 90 | 25 | 95 | 50 |
| 11 | 95 | 60 | 25 | 55 |
| ... | ... | ... | ... | ... |
| 184 | 100 | 30 | 30 | 85 |
| 190 | 95 | 35 | 40 | 95 |
| 192 | 100 | 40 | 80 | 80 |
| 197 | 85 | 85 | 100 | 10 |
| 198 | 80 | 65 | 35 | 60 |
95 rows × 4 columns
df.loc[list(map(lambda x: x>df.att.mean() , df.att))]
df.loc[map(lambda x: x>df.att.mean() , df.att)]| att | rep | mid | fin | |
|---|---|---|---|---|
| 1 | 95 | 30 | 60 | 10 |
| 4 | 80 | 60 | 55 | 70 |
| 8 | 95 | 55 | 65 | 90 |
| 9 | 90 | 25 | 95 | 50 |
| 11 | 95 | 60 | 25 | 55 |
| ... | ... | ... | ... | ... |
| 184 | 100 | 30 | 30 | 85 |
| 190 | 95 | 35 | 40 | 95 |
| 192 | 100 | 40 | 80 | 80 |
| 197 | 85 | 85 | 100 | 10 |
| 198 | 80 | 65 | 35 | 60 |
95 rows × 4 columns
. |
[] |
.iloc |
.loc |
|
|---|---|---|---|---|
| row/단일레이블 | X | X | O | O |
| col/단일레이블 | O | O | O | O |
| row/레이블리스트 | X | X | O | O |
| col/레이블리스트 | X | O | O | O |
| row/슬라이싱 | X | O | O | O |
| col/슬라이싱 | X | X | O | O |
| row/bool,list | X | O | O | O |
| row/bool,ser | X | O | X | O |
| row/bool,map | X | X | O | O |
숙제
1. 10월12일 숙제
아래와 같이 0~9까지 포함된 리스트를 만들어라
아래와 동일한 기능을 수행하는 함수를 lambda expression으로 정의하라.
map과 lambda expression 을 이용하여 아래와 같은 결과를 만들어라. (리스트컴프리헨션, for문 사용금지)
2. 10월14일 숙제
다음과 같은 데이터프레임을 불러온 뒤 물음에 답하라
| att | rep | mid | fin | |
|---|---|---|---|---|
| 0 | 65 | 45 | 0 | 10 |
| 1 | 95 | 30 | 60 | 10 |
| 2 | 65 | 85 | 15 | 20 |
| 3 | 55 | 35 | 35 | 5 |
| 4 | 80 | 60 | 55 | 70 |
| ... | ... | ... | ... | ... |
| 195 | 55 | 70 | 40 | 95 |
| 196 | 65 | 85 | 25 | 85 |
| 197 | 85 | 85 | 100 | 10 |
| 198 | 80 | 65 | 35 | 60 |
| 199 | 50 | 95 | 45 | 85 |
200 rows × 4 columns
(1) 기말고사 성적이 중간고사 성적보다 향상된 학생들을 출력하라. 즉 mid < fin 인 학생들을 출력하라. (다양한 방법으로 연습할 것, 제출은 한 가지 방법으로 구현해도 감점없음)
| att | rep | mid | fin | |
|---|---|---|---|---|
| 0 | 65 | 45 | 0 | 10 |
| 2 | 65 | 85 | 15 | 20 |
| 4 | 80 | 60 | 55 | 70 |
| 5 | 75 | 40 | 75 | 85 |
| 6 | 65 | 70 | 60 | 75 |
| ... | ... | ... | ... | ... |
| 194 | 65 | 40 | 65 | 70 |
| 195 | 55 | 70 | 40 | 95 |
| 196 | 65 | 85 | 25 | 85 |
| 198 | 80 | 65 | 35 | 60 |
| 199 | 50 | 95 | 45 | 85 |
93 rows × 4 columns
(2) 기말고사 성적이 중간고사 성적보다 향상된 학생들의 출석과 레포트 점수를 출력하라.