seaborn(1)–seaborn특징,boxplot,lineplot
강의영상
https://youtube.com/playlist?list=PLQqh36zP38-yKl-lbn597pdBzbYRDj2i_
imports
seaborn 특징
- 특1: 입력으로 데이터프레임을 선호한다. (matplotlib은 array를 선호)
- 그렇다고 해서 데이터프레임이 아닌 경우 그림이 아예 안 그려지지는 않는다.
- 데이터프레임 형태는 long form 과 wide form 이 있다. (ref) // 참고로 long form이 더 우수한 저장형태에요!
- wide-df = [array1,array2,array3]
- long-df = [array_val, array_cat]
- 특2: matplotlib을 존경함. (ref)
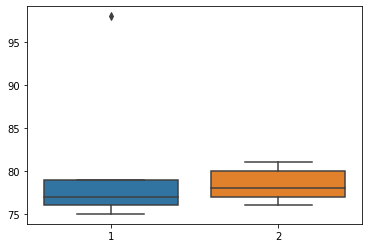
sns boxplot
- 데이터: 전북고등학교
plt 복습
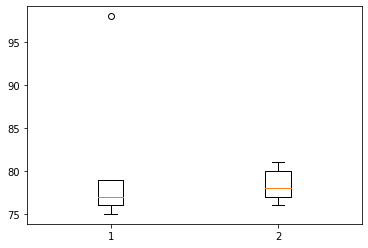
sns wide df
| 1 | 2 | |
|---|---|---|
| 0 | 75 | 76 |
| 1 | 75 | 76 |
| 2 | 76 | 77 |
| 3 | 76 | 77 |
| 4 | 77 | 78 |
| 5 | 77 | 78 |
| 6 | 79 | 80 |
| 7 | 79 | 80 |
| 8 | 79 | 80 |
| 9 | 98 | 81 |
- 예시1
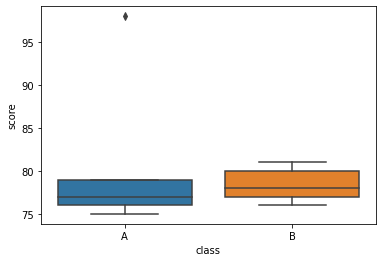
sns long df
| score | class | |
|---|---|---|
| 0 | 75 | A |
| 1 | 75 | A |
| 2 | 76 | A |
| 3 | 76 | A |
| 4 | 77 | A |
| 5 | 77 | A |
| 6 | 79 | A |
| 7 | 79 | A |
| 8 | 79 | A |
| 9 | 98 | A |
| 10 | 76 | B |
| 11 | 76 | B |
| 12 | 77 | B |
| 13 | 77 | B |
| 14 | 78 | B |
| 15 | 78 | B |
| 16 | 80 | B |
| 17 | 80 | B |
| 18 | 80 | B |
| 19 | 81 | B |
- 예시1
sns: array
- 예시1
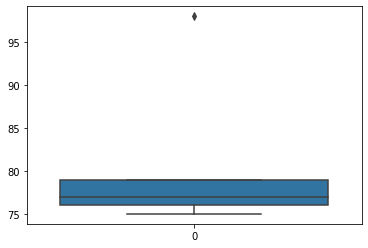
- 예시2
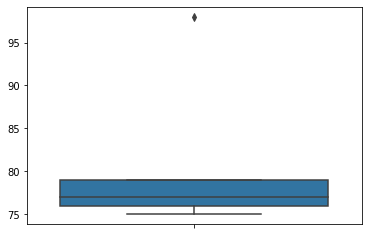
- 예시3

sns histplot
- 데이터
plt 복습
- 예시1
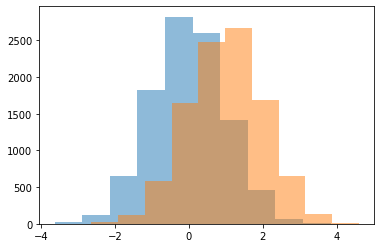
- 예시2
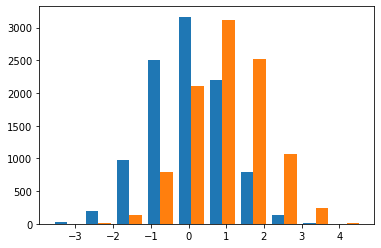
sns: wide df
| x | y | |
|---|---|---|
| 0 | -2.110587 | 0.712687 |
| 1 | 0.176404 | 1.587615 |
| 2 | 0.592212 | 0.362025 |
| 3 | 0.957655 | 0.485939 |
| 4 | 1.689412 | 0.582304 |
| ... | ... | ... |
| 9995 | -0.935895 | 0.047778 |
| 9996 | 1.521599 | 1.946658 |
| 9997 | -0.595255 | 0.671715 |
| 9998 | 0.952991 | 2.263997 |
| 9999 | 0.850642 | 1.578771 |
10000 rows × 2 columns
- 예시1

- 예시2
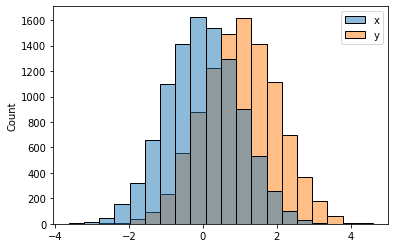
- 예시3
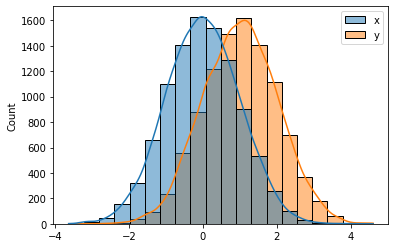
- 예시4

- 예시5
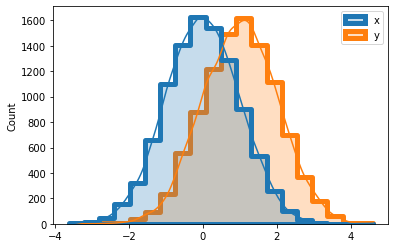
sns: long df
| val | var | |
|---|---|---|
| 0 | -2.110587 | x |
| 1 | 0.176404 | x |
| 2 | 0.592212 | x |
| 3 | 0.957655 | x |
| 4 | 1.689412 | x |
| ... | ... | ... |
| 19995 | 0.047778 | y |
| 19996 | 1.946658 | y |
| 19997 | 0.671715 | y |
| 19998 | 2.263997 | y |
| 19999 | 1.578771 | y |
20000 rows × 2 columns
- 예시1
<AxesSubplot:xlabel='val', ylabel='Count'>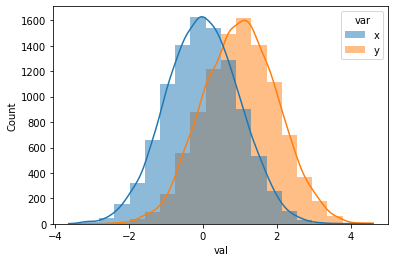
- 예시2

sns: array
- 예시1
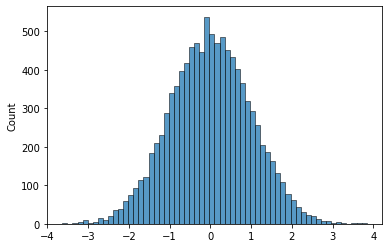
- 예시2
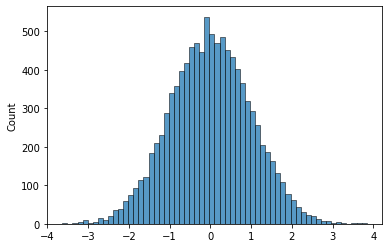
- 예시3

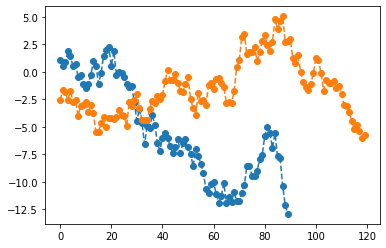
sns lineplot
- data
plt 복습
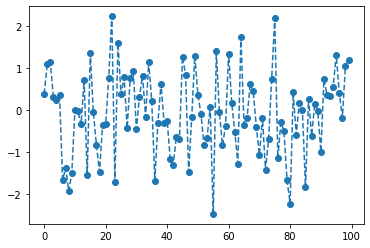

sns: array
- 예시1
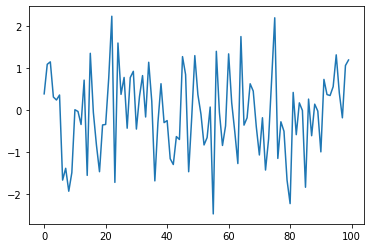
- 예시2

sns: wide df
| eps | y | |
|---|---|---|
| 0 | 0.383420 | 0.383420 |
| 1 | 1.084175 | 1.467595 |
| 2 | 1.142778 | 2.610373 |
| 3 | 0.307894 | 2.918267 |
| 4 | 0.237787 | 3.156054 |
| ... | ... | ... |
| 95 | 1.308688 | -10.598788 |
| 96 | 0.405376 | -10.193412 |
| 97 | -0.185070 | -10.378481 |
| 98 | 1.055388 | -9.323094 |
| 99 | 1.187014 | -8.136079 |
100 rows × 2 columns
- 예시1
- 예시2
- 예시3
- 예시4
sns: long df
df2= pd.DataFrame({'idx':list(range(100))*2,'val':np.concatenate([ϵ,y]),'cat':['eps']*100 + ['y']*100 })
df2| idx | val | cat | |
|---|---|---|---|
| 0 | 0 | 0.383420 | eps |
| 1 | 1 | 1.084175 | eps |
| 2 | 2 | 1.142778 | eps |
| 3 | 3 | 0.307894 | eps |
| 4 | 4 | 0.237787 | eps |
| ... | ... | ... | ... |
| 195 | 95 | -10.598788 | y |
| 196 | 96 | -10.193412 | y |
| 197 | 97 | -10.378481 | y |
| 198 | 98 | -9.323094 | y |
| 199 | 99 | -8.136079 | y |
200 rows × 3 columns
- 예시1
- 예시2
<AxesSubplot:xlabel='idx', ylabel='val'>
- 예시3
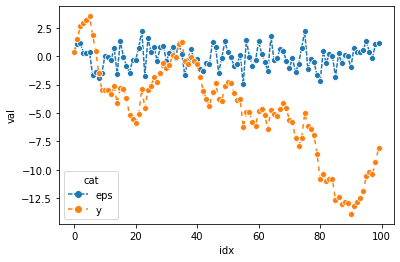
숙제
- 아래의 그림에 대응하는 그림을 seaborn을 이용하여 그려라.