산점도 응용예제 1,2,3 (표본상관계수, 앤스콤플랏, 무상관)
강의영상
https://youtube.com/playlist?list=PLQqh36zP38-wzG-Xph83hc_mMpS6P5ely
imports
산점도 응용예제1 - 표본상관계수
예제소개
- 아래와 같은 자료를 수집하였다고 하자.
- 몸무게 = [44,48,49,58,62,68,69,70,76,79]
- 키 = [159,160,162,165,167,162,165,175,165,172]
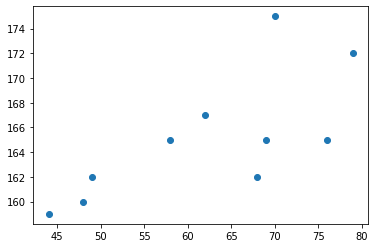
- 키가 큰 사람일수록 몸무게도 많이 나간다. (반대도 성립)
- 키와 몸무게는 관계가 있어보인다. (정비례)
- 얼만큼 정비례인지?
- 이 질문에 대답하기 위해서는 상관계수의 개념을 알아야 한다.
- 상관계수는 산점도에서 가장 중요한 개념중 하나.
상관계수의 정의
- (표본)상관계수
\[r=\frac{\sum_{i=1}^{n}(x_i-\bar{x})(y_i-\bar{y}) }{\sqrt{\sum_{i=1}^{n}(x_i-\bar{x})^2\sum_{i=1}^{n}(y_i-\bar{y})^2 }}=\sum_{i=1}^{n}\tilde{x}_i\tilde{y}_i \]
- 단, \(\tilde{x}_i=\frac{(x_i-\bar{x})}{\sqrt{\sum_{i=1}^n(x_i-\bar{x})^2}}\), \(\tilde{y}_i=\frac{(y_i-\bar{y})}{\sqrt{\sum_{i=1}^n(y_i-\bar{y})^2}}\)
* 표본의 의미
평균과 표본평균
array([ 0.38342049, 1.0841745 , 1.14277825, 0.30789368, 0.23778744,
0.35595116, -1.66307542, -1.38277318, -1.92684484, -1.4862163 ])- x는 의 각 원소는 모두
평균이 0인 정규분포에서 추출했다고 표현
- \({\tt x}=(x_1,\dots, x_{10})\)의
표본평균은 \({\bar x}=0.09434107867212947\) 라고 표현
상관계수의 의미
- 의미?


- \(\tilde{x}_i\)와 \(\tilde{y}_i\)를 계산하기 위해서 \(a=\sqrt{\sum_{i=1}^{n}(x_i-\bar{x})^2}, b=\sqrt{\sum_{i=1}^{n}(y_i-\bar{y})^2}\)를 계산하자.
(방법1)
(2.8842557251032446, 15.218409903797438)- 해석: \(a>b\) 이므로 \(\{x_i\}\)들이 \(\{y_i\}\)들 보다 좀 더 퍼져있다. (=평균근처에 몰려있지 않다)
(방법2)
- 사실 \(a,b\)는 아래와 같이 계산할 수 있다.
\(a=\sqrt{n}\times{\tt np.std(x)}\)
\(b=\sqrt{n}\times{\tt np.std(y)}\)
- \({\tt np.std(x)}=\sqrt{\frac{1}{n}\sum_{i=1}^{n}(x_i-\bar{x})^2}\)
- \({\tt np.std(y)}=\sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i-\bar{y})^2}\)
note: \({\tt np.std(x,ddof=1)}=\sqrt{\frac{1}{n-1}\sum_{i=1}^{n}(x_i-\bar{x})^2}\)
- 이제 \((\tilde{x}_i,\tilde{y}_i)\)를 ax3에 그려보자.

질문: \(r\)의 값이 양수인가? 음수인가?
- plotly 사용하여 \((\tilde{x}_i,\tilde{y}_i)\)를 그려보자.
- \(\tilde{x}_i\), \(\tilde{y}_i\) 를 곱한값이 양수인것과 음수인것을 체크해보자.
- 양수인쪽이 많은지 음수인쪽이 많은지 생각해보자.
- \(r=\sum_{i=1}^{n}\tilde{x}_i \tilde{y}_i\) 의 부호는?
그림을 보고 상관계수의 부호를 알아내는 방법
- \((x_i,y_i)\)의 산점도를 보고 \((\tilde{x}_i, \tilde{y}_i)\) 의 산점도를 상상 \(\to\) 1,3 분면에 점들이 많으면 양수, 2,4 분면에 점들이 많으면 음수
그림을 보고 상관계수의 절대값을 알아내는 방법
- 이해를 위한 예시
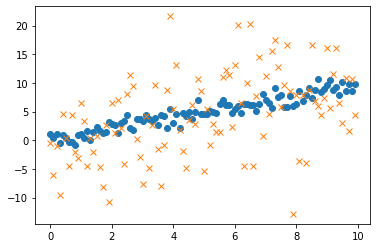
각 데이터셋의 표준상관계수를 각각 \(r_1\)(파란색), \(r_2\)(주황색)라고 하자.
(1) \(r_1\), \(r_2\)의 부호는 양수인가? 음수인가? –> 양수
(2) \(r_1,r_2\)의 값중 어떠한 값이 더 절대값이 큰가? –> 잘모르겠음. 따져보자.
fig, ax = plt.subplots(1,2)
ax[0].plot(x,y1,'o')
ax[0].plot(x,y2,'x')
ax[1].plot(x,yy1,'o')
ax[1].plot(x,yy2,'x')
- 그림을 보고 상관계수의 절대값을 알아내는 방법!: 직선근처에 몰려있으면 절대값이 커요!
산점도 응용예제2 – 앤스콤의 4분할
- Anscombe’s quartet: 교과서에 나오는 그림임.
- 교훈1: 데이터를 분석하기 전에 항상 시각화를 하라.
x = [10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5]
y1 = [8.04, 6.95, 7.58, 8.81, 8.33, 9.96, 7.24, 4.26, 10.84, 4.82, 5.68]
y2 = [9.14, 8.14, 8.74, 8.77, 9.26, 8.10, 6.13, 3.10, 9.13, 7.26, 4.74]
y3 = [7.46, 6.77, 12.74, 7.11, 7.81, 8.84, 6.08, 5.39, 8.15, 6.42, 5.73]
x4 = [8, 8, 8, 8, 8, 8, 8, 19, 8, 8, 8]
y4 = [6.58, 5.76, 7.71, 8.84, 8.47, 7.04, 5.25, 12.50, 5.56, 7.91, 6.89]fig, ((ax1,ax2),(ax3,ax4)) = plt.subplots(2,2)
ax1.plot(x,y1,'o')
ax2.plot(x,y2,'o')
ax3.plot(x,y3,'o')
ax4.plot(x4,y4,'o') 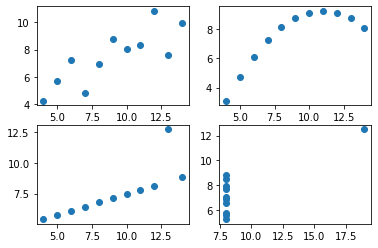
- 첫번째 그림의 상관계수를 구해보자. 즉 corr(x,y1)을 구해보자.
- 사실 아래와 같이 구해도 된다.
- corr(x,y1), corr(x,y2), corr(x,y3)를 구해보자.
array([[1. , 0.81642052, 0.81623651, 0.81628674],
[0.81642052, 1. , 0.7500054 , 0.46871668],
[0.81623651, 0.7500054 , 1. , 0.58791933],
[0.81628674, 0.46871668, 0.58791933, 1. ]])- 앤스콤의 4분할중 1,2,3 번째 그림의 상관계수는 0.81642052, 0.81623651, 0.81628674 이라는 의미
- 즉 corr(x,y1)=0.81642052, corr(x,y2)=0.81623651, corr(x,y3)=0.81628674 임
* 참고로 np.corrcoef([x,y1,y2,y3])의 계산결과는 정확하게
\[\begin{bmatrix} corr(x,x) & corr(x,y1) & corr(x,y2) & corr(x,y3) \\ corr(y1,x) & corr(y1,y1) & corr(y1,y2) & corr(y1,y3) \\ corr(y2,x) & corr(y2,y1) & corr(y2,y2) & corr(y2,y3) \\ corr(y3,x) & corr(y3,y1) & corr(y3,y2) & corr(y3,y3)\end{bmatrix}\]
를 의미함
- 앤스콤플랏의 4개의 그림은 모두 같은 상관계수를 가진다. \(\to\) 하지만 4개의 그림은 느낌이 전혀 다르다.
- 같은 표본상관계수를 가진다고 하여 같은 관계성을 가지는 것은 아니다. 표본상관계수는 x,y의 비례정도를 측정하는데 그 값이 1에 가깝다고 하여 꼭 정비례의 관계가 있음을 의미하는게 아니다. \((x_i,y_i)\)의 산점도가 선형성을 보일때만 “표본상관계수가 1이므로 정비례의 관계에 있다” 라는 논리전개가 성립한다.
- 앤스콤의 1번째 플랏: 산점도가 선형 \(\to\) 표본상관계수가 0.816 = 정비례의 관계가 0.816 정도
- 앤스콤의 2번째 플랏: 산점도가 선형이 아님 \(\to\) 표본상관계수가 크게 의미없음
- 앤스콤의 3번째 플랏: 산점도가 선형인듯 보이나 하나의 이상치가 있음 \(\to\) 하나의 이상치가 표본상관계수의 값을 무너뜨릴 수 있으므로 표본상관계수값을 신뢰할 수 없음.
- 앤스콤의 4번째 플랏: 산점도를 그려보니 이상한그림 \(\to\) 표존상관계수를 계산할수는 있음. 그런데 그게 무슨 의미가 있을지?
- 앤스콤의 3번째 플랏: 하나의 이상치가 상관계수를 무너뜨리는 경우 시각화

- 하나의 점을 잘 추가하면 이 상관계수값을 -1에 수렴시킬 수 있다?

- 교훈2: 상관계수를 해석하기에 앞서서 산점도가 선형성을 보이는지 체크할 것! 항상 통계학과에서 배우는 통계량 (혹은 논리전개)는 적절한 가정하에서만 말이된다는 사실을 기억할 것!
산점도 응용예제3 – 무상관은 관계가 없다는 뜻?

- 표본상관계수의 값이 0에 가까운 것은 두 변수의 직선관계가 약한것을 의미한 것이지 두 변수 사이에 아무런 함수관계가 없다는 것을 의미하는 것은 아니다.
숙제
아래의 그림을 보고 물음에 답하라.
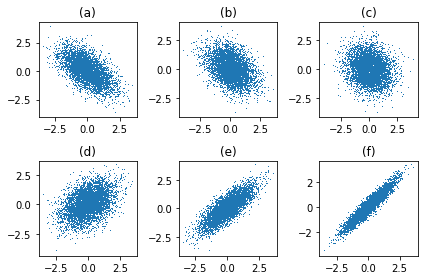
(1) 산점도 (a) - (f) 중 표본상관계수가 양수라 생각되는 그림은?
(2) 산점도 (a) - (f) 중 표본상관계수의 절대값이 가장 큰 그림은? 절대값이 가장 작은 그림은?