#!pip install autogluon.multimodal 14wk-60: 자전거대여 / 하이퍼파라메터 튜닝
1. 강의영상
2. Imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn.preprocessing
#---#}
from autogluon.tabular import TabularPredictor
from autogluon.timeseries import TimeSeriesDataFrame, TimeSeriesPredictor
from autogluon.common import space
#---#
import IPython
import os
import warnings
warnings.filterwarnings('ignore')3. Data
- 자료 다운로드
!kaggle competitions download -c bike-sharing-demandDownloading bike-sharing-demand.zip to /home/cgb2/Dropbox/07_lectures/2023-09-MP2023/posts
100%|█████████████████████████████████████████| 189k/189k [00:00<00:00, 763kB/s]
100%|█████████████████████████████████████████| 189k/189k [00:00<00:00, 762kB/s]!unzip bike-sharing-demand.zip -d dataArchive: bike-sharing-demand.zip
inflating: data/sampleSubmission.csv
inflating: data/test.csv
inflating: data/train.csv sampleSubmission = pd.read_csv('data/sampleSubmission.csv')
df_train = pd.read_csv('data/train.csv')
df_test = pd.read_csv('data/test.csv') !rm -rf data
!rm bike-sharing-demand.zip4. 기본전처리 및 분석 프로세스
- 전처리
def preprocessing(df_train,df_test):
df_train_featured = df_train.copy()
df_test_featured = df_test.copy()
#----#
df_train_featured = df_train_featured.drop(['casual','registered'],axis=1)
#--#
df_train_featured['hour'] = df_train_featured['datetime'].apply(pd.to_datetime).dt.hour
df_test_featured['hour'] = df_test_featured['datetime'].apply(pd.to_datetime).dt.hour
df_train_featured['weekday'] = df_train_featured['datetime'].apply(pd.to_datetime).dt.weekday
df_test_featured['weekday'] = df_test_featured['datetime'].apply(pd.to_datetime).dt.weekday
#--#
df_train_featured = df_train_featured.drop(['datetime'],axis=1)
df_test_featured = df_test_featured.drop(['datetime'],axis=1)
#--#
df_train_featured = df_train_featured.drop(['atemp'],axis=1)
df_test_featured = df_test_featured.drop(['atemp'],axis=1)
return df_train_featured, df_test_featured- 함수들
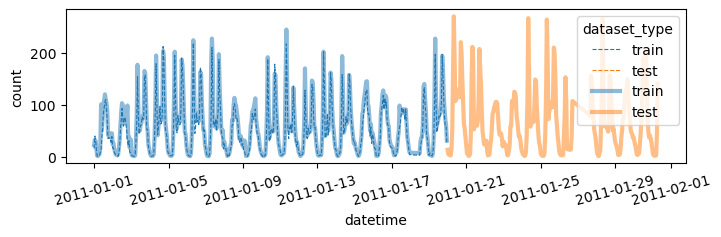
def plot(yhat,yyhat):
df = pd.concat([
df_train.assign(count_hat = yhat, dataset_type = 'train'),
df_test.assign(count_hat = yyhat, dataset_type = 'test')
]).reset_index(drop=True)
df['datetime'] = pd.to_datetime(df['datetime'])
sns.lineplot(
df.sort_values('datetime')[:(24*28)],
x='datetime',y='count',
hue='dataset_type',
linestyle='--',
lw=0.8
)
sns.lineplot(
df.sort_values('datetime')[:(24*28)],
x='datetime',y='count_hat',
hue='dataset_type',
alpha=0.5,
lw=3
)
fig = plt.gcf()
fig.set_size_inches(8,2)
plt.xticks(rotation=15);
fig.show()def submit(yyhat):
sampleSubmission['count'] = yyhat
sampleSubmission['count'] = sampleSubmission['count'].apply(lambda x: x if x>0 else 0)
sampleSubmission.to_csv("submission.csv",index=False)
!kaggle competitions submit -c bike-sharing-demand -f submission.csv -m "Message"
!rm submission.csvdef auto(df_train, df_test):
# step1
df_train_featured, df_test_featured = preprocessing(df_train, df_test) # preprocessing
df_train_featured['count'] = np.log1p(df_train_featured['count']) # transform
# step2~4
yhat,yyhat = fit_predict(df_train_featured,df_test_featured)
yhat = np.expm1(yhat) # inverse_trans
yyhat = np.expm1(yyhat) # inverse_trans
# 시각화
plot(yhat,yyhat)
# 제출
submit(yyhat)5. 하이퍼파라메터 튜닝
- 기본 HP
{
"NN_TORCH": {},
"GBM": [
{"extra_trees": True, "ag_args": {"name_suffix": "XT"}},
{},
"GBMLarge"
],
"CAT": {},
"XGB": {},
"FASTAI": {},
"RF": [
{"criterion": "gini", "ag_args": {"name_suffix": "Gini", "problem_types": ["binary", "multiclass"]}},
{"criterion": "entropy", "ag_args": {"name_suffix": "Entr", "problem_types": ["binary", "multiclass"]}},
{"criterion": "squared_error", "ag_args": {"name_suffix": "MSE", "problem_types": ["regression"]}}
],
"XT": [
{"criterion": "gini", "ag_args": {"name_suffix": "Gini", "problem_types": ["binary", "multiclass"]}},
{"criterion": "entropy", "ag_args": {"name_suffix": "Entr", "problem_types": ["binary", "multiclass"]}},
{"criterion": "squared_error", "ag_args": {"name_suffix": "MSE", "problem_types": ["regression"]}}
],
"KNN": [
{"weights": "uniform", "ag_args": {"name_suffix": "Unif"}},
{"weights": "distance", "ag_args": {"name_suffix": "Dist"}}
]
}- fit_predict 함수 수정
def fit_predict(df_train_featured, df_test_featured):
# step1
# step2
predictr= TabularPredictor(label='count',verbosity=False)
# step3
hp = {
"RF": [
{"criterion": "squared_error", "ag_args": {"name_suffix": "MSE", "problem_types": ["regression"]}}
]
}
predictr.fit(
df_train_featured,
hyperparameters = hp
)
# step4
yhat = predictr.predict(df_train_featured)
yyhat = predictr.predict(df_test_featured)
# display
display(predictr.leaderboard())
return yhat, yyhat auto(df_train,df_test)| model | score_val | eval_metric | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | RandomForestMSE | -0.401983 | root_mean_squared_error | 0.044126 | 0.869338 | 0.044126 | 0.869338 | 1 | True | 1 |
| 1 | WeightedEnsemble_L2 | -0.401983 | root_mean_squared_error | 0.044359 | 0.870885 | 0.000233 | 0.001547 | 2 | True | 2 |
100%|█████████████████████████████████████████| 243k/243k [00:02<00:00, 122kB/s]
Successfully submitted to Bike Sharing Demand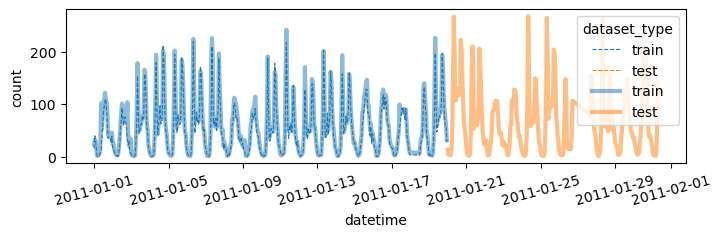
ref: https://auto.gluon.ai/0.8.1/api/autogluon.tabular.models.html
- LightGBM model: https://lightgbm.readthedocs.io/en/latest/
- CatBoost model: https://catboost.ai/
- XGBoost model: https://xgboost.readthedocs.io/en/latest/
- Random Forest model (scikit-learn): https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
- Extra Trees model (scikit-learn): https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.ExtraTreesClassifier.html#sklearn.ensemble.ExtraTreesClassifier
- Linear model (scikit-learn): https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
- 방금 돌린것은 아래와 결과가 동일함.
def fit_predict(df_train_featured, df_test_featured):
# step1
# step2
predictr= TabularPredictor(label='count',verbosity=False)
# step3
hp = {
"RF": [
{"n_estimators":300, "criterion": "squared_error", "ag_args": {"name_suffix": "MSE", "problem_types": ["regression"]}}
]
}
predictr.fit(
df_train_featured,
hyperparameters = hp
)
# step4
yhat = predictr.predict(df_train_featured)
yyhat = predictr.predict(df_test_featured)
# display
display(predictr.leaderboard())
return yhat, yyhat auto(df_train,df_test)| model | score_val | eval_metric | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | RandomForestMSE | -0.401983 | root_mean_squared_error | 0.034022 | 0.712419 | 0.034022 | 0.712419 | 1 | True | 1 |
| 1 | WeightedEnsemble_L2 | -0.401983 | root_mean_squared_error | 0.034240 | 0.713953 | 0.000218 | 0.001534 | 2 | True | 2 |
100%|█████████████████████████████████████████| 243k/243k [00:02<00:00, 121kB/s]
Successfully submitted to Bike Sharing Demand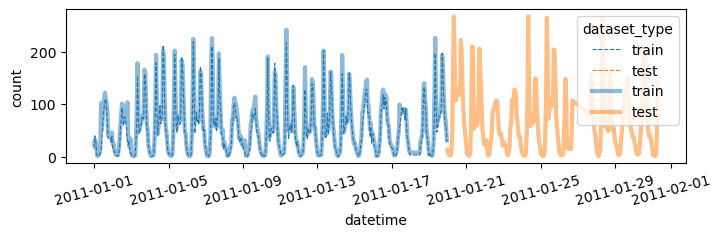
- 알아낸 방법?
df_train_featured, df_test_featured = preprocessing(df_train,df_test)predictr= TabularPredictor(label='count',verbosity=False)
# step3
hp = {
"RF": [
{"criterion": "squared_error", "ag_args": {"name_suffix": "MSE", "problem_types": ["regression"]}}
]
}
predictr.fit(
df_train_featured,
hyperparameters = hp
)<autogluon.tabular.predictor.predictor.TabularPredictor at 0x7f5f8525b2d0>predictr.info()['model_info']['RandomForestMSE']['hyperparameters']{'n_estimators': 300,
'max_leaf_nodes': 15000,
'n_jobs': -1,
'random_state': 0,
'bootstrap': True,
'criterion': 'squared_error'}- RF에서 더 다양한 파라메터를 실험해보자.
def fit_predict(df_train_featured, df_test_featured):
# step1
# step2
predictr= TabularPredictor(label='count',verbosity=False)
# step3
hp = {
"RF": [ {"criterion": "squared_error", "n_estimators":i, "max_leaf_nodes":j, "ag_args": {"name_suffix": f"({i},{j})"}} for i in [300,400,500] for j in [10000,15000]]
}
predictr.fit(
df_train_featured,
hyperparameters = hp
)
# step4
yhat = predictr.predict(df_train_featured)
yyhat = predictr.predict(df_test_featured)
# display
display(predictr.leaderboard())
return yhat, yyhat auto(df_train,df_test)| model | score_val | eval_metric | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | RandomForest(500,10000) | -0.401733 | root_mean_squared_error | 0.054719 | 1.484488 | 0.054719 | 1.484488 | 1 | True | 5 |
| 1 | WeightedEnsemble_L2 | -0.401733 | root_mean_squared_error | 0.054930 | 1.555554 | 0.000211 | 0.071066 | 2 | True | 7 |
| 2 | RandomForest(500,15000) | -0.401733 | root_mean_squared_error | 0.064742 | 1.486831 | 0.064742 | 1.486831 | 1 | True | 6 |
| 3 | RandomForest(300,15000) | -0.401983 | root_mean_squared_error | 0.034378 | 0.778114 | 0.034378 | 0.778114 | 1 | True | 2 |
| 4 | RandomForest(300,10000) | -0.401983 | root_mean_squared_error | 0.044908 | 0.723808 | 0.044908 | 0.723808 | 1 | True | 1 |
| 5 | RandomForest(400,10000) | -0.402192 | root_mean_squared_error | 0.054852 | 1.019239 | 0.054852 | 1.019239 | 1 | True | 3 |
| 6 | RandomForest(400,15000) | -0.402192 | root_mean_squared_error | 0.054879 | 1.250339 | 0.054879 | 1.250339 | 1 | True | 4 |
100%|█████████████████████████████████████████| 242k/242k [00:01<00:00, 139kB/s]
Successfully submitted to Bike Sharing Demand