import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn.preprocessing
#---#}
from autogluon.tabular import TabularPredictor
from autogluon.timeseries import TimeSeriesDataFrame, TimeSeriesPredictor
from autogluon.common import space
#---#
import warnings
warnings.filterwarnings('ignore')14wk-59: 자전거대여 / 자료분석(Autogluon)
1. 강의영상
2. Imports
3. Data
ref: https://www.kaggle.com/competitions/bike-sharing-demand
- 자료 다운로드
!kaggle competitions download -c bike-sharing-demandWarning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /root/.kaggle/kaggle.json'
Downloading bike-sharing-demand.zip to /root/Dropbox
100%|█████████████████████████████████████████| 189k/189k [00:00<00:00, 829kB/s]
100%|█████████████████████████████████████████| 189k/189k [00:00<00:00, 829kB/s]!unzip bike-sharing-demand.zip -d dataArchive: bike-sharing-demand.zip
inflating: data/sampleSubmission.csv
inflating: data/test.csv
inflating: data/train.csv sampleSubmission = pd.read_csv('data/sampleSubmission.csv')
df_train = pd.read_csv('data/train.csv')
df_test = pd.read_csv('data/test.csv') !rm -rf data
!rm bike-sharing-demand.zip- 자료관찰
display("train",df_train,"test",df_test)'train'| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 0.0000 | 3 | 13 | 16 |
| 1 | 2011-01-01 01:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0000 | 8 | 32 | 40 |
| 2 | 2011-01-01 02:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0000 | 5 | 27 | 32 |
| 3 | 2011-01-01 03:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0000 | 3 | 10 | 13 |
| 4 | 2011-01-01 04:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0000 | 0 | 1 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 10881 | 2012-12-19 19:00:00 | 4 | 0 | 1 | 1 | 15.58 | 19.695 | 50 | 26.0027 | 7 | 329 | 336 |
| 10882 | 2012-12-19 20:00:00 | 4 | 0 | 1 | 1 | 14.76 | 17.425 | 57 | 15.0013 | 10 | 231 | 241 |
| 10883 | 2012-12-19 21:00:00 | 4 | 0 | 1 | 1 | 13.94 | 15.910 | 61 | 15.0013 | 4 | 164 | 168 |
| 10884 | 2012-12-19 22:00:00 | 4 | 0 | 1 | 1 | 13.94 | 17.425 | 61 | 6.0032 | 12 | 117 | 129 |
| 10885 | 2012-12-19 23:00:00 | 4 | 0 | 1 | 1 | 13.12 | 16.665 | 66 | 8.9981 | 4 | 84 | 88 |
10886 rows × 12 columns
'test'| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-20 00:00:00 | 1 | 0 | 1 | 1 | 10.66 | 11.365 | 56 | 26.0027 |
| 1 | 2011-01-20 01:00:00 | 1 | 0 | 1 | 1 | 10.66 | 13.635 | 56 | 0.0000 |
| 2 | 2011-01-20 02:00:00 | 1 | 0 | 1 | 1 | 10.66 | 13.635 | 56 | 0.0000 |
| 3 | 2011-01-20 03:00:00 | 1 | 0 | 1 | 1 | 10.66 | 12.880 | 56 | 11.0014 |
| 4 | 2011-01-20 04:00:00 | 1 | 0 | 1 | 1 | 10.66 | 12.880 | 56 | 11.0014 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6488 | 2012-12-31 19:00:00 | 1 | 0 | 1 | 2 | 10.66 | 12.880 | 60 | 11.0014 |
| 6489 | 2012-12-31 20:00:00 | 1 | 0 | 1 | 2 | 10.66 | 12.880 | 60 | 11.0014 |
| 6490 | 2012-12-31 21:00:00 | 1 | 0 | 1 | 1 | 10.66 | 12.880 | 60 | 11.0014 |
| 6491 | 2012-12-31 22:00:00 | 1 | 0 | 1 | 1 | 10.66 | 13.635 | 56 | 8.9981 |
| 6492 | 2012-12-31 23:00:00 | 1 | 0 | 1 | 1 | 10.66 | 13.635 | 65 | 8.9981 |
6493 rows × 9 columns
- train/test가 나누어진 시점 해석
display("train",df_train[::24][:20], "test",df_test[::24][:10])'train'| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 0.0000 | 3 | 13 | 16 |
| 24 | 2011-01-02 00:00:00 | 1 | 0 | 0 | 2 | 18.86 | 22.725 | 88 | 19.9995 | 4 | 13 | 17 |
| 48 | 2011-01-03 01:00:00 | 1 | 0 | 1 | 1 | 8.20 | 8.335 | 44 | 27.9993 | 0 | 2 | 2 |
| 72 | 2011-01-04 04:00:00 | 1 | 0 | 1 | 1 | 5.74 | 9.090 | 63 | 6.0032 | 0 | 2 | 2 |
| 96 | 2011-01-05 05:00:00 | 1 | 0 | 1 | 1 | 9.02 | 11.365 | 47 | 11.0014 | 0 | 3 | 3 |
| 120 | 2011-01-06 06:00:00 | 1 | 0 | 1 | 2 | 5.74 | 8.335 | 63 | 7.0015 | 0 | 36 | 36 |
| 144 | 2011-01-07 07:00:00 | 1 | 0 | 1 | 1 | 8.20 | 10.605 | 69 | 8.9981 | 8 | 76 | 84 |
| 168 | 2011-01-08 07:00:00 | 1 | 0 | 0 | 2 | 6.56 | 9.090 | 74 | 7.0015 | 1 | 8 | 9 |
| 192 | 2011-01-09 07:00:00 | 1 | 0 | 0 | 1 | 3.28 | 4.545 | 53 | 12.9980 | 1 | 5 | 6 |
| 216 | 2011-01-10 07:00:00 | 1 | 0 | 1 | 1 | 4.92 | 6.060 | 50 | 15.0013 | 2 | 75 | 77 |
| 240 | 2011-01-11 09:00:00 | 1 | 0 | 1 | 2 | 7.38 | 9.850 | 51 | 11.0014 | 3 | 127 | 130 |
| 264 | 2011-01-12 11:00:00 | 1 | 0 | 1 | 1 | 8.20 | 9.090 | 51 | 26.0027 | 3 | 32 | 35 |
| 288 | 2011-01-13 11:00:00 | 1 | 0 | 1 | 2 | 8.20 | 8.335 | 44 | 30.0026 | 4 | 33 | 37 |
| 312 | 2011-01-14 12:00:00 | 1 | 0 | 1 | 1 | 8.20 | 9.850 | 44 | 16.9979 | 2 | 59 | 61 |
| 336 | 2011-01-15 12:00:00 | 1 | 0 | 0 | 1 | 9.84 | 11.365 | 48 | 15.0013 | 15 | 74 | 89 |
| 360 | 2011-01-16 12:00:00 | 1 | 0 | 0 | 1 | 9.84 | 10.605 | 41 | 19.0012 | 29 | 75 | 104 |
| 384 | 2011-01-17 12:00:00 | 1 | 1 | 0 | 2 | 7.38 | 9.850 | 47 | 8.9981 | 10 | 70 | 80 |
| 408 | 2011-01-19 00:00:00 | 1 | 0 | 1 | 2 | 9.02 | 13.635 | 93 | 0.0000 | 0 | 3 | 3 |
| 432 | 2011-02-01 01:00:00 | 1 | 0 | 1 | 2 | 6.56 | 9.090 | 69 | 7.0015 | 0 | 3 | 3 |
| 456 | 2011-02-02 02:00:00 | 1 | 0 | 1 | 3 | 9.02 | 11.365 | 93 | 8.9981 | 4 | 0 | 4 |
'test'| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-20 00:00:00 | 1 | 0 | 1 | 1 | 10.66 | 11.365 | 56 | 26.0027 |
| 24 | 2011-01-21 00:00:00 | 1 | 0 | 1 | 2 | 9.84 | 11.365 | 70 | 16.9979 |
| 48 | 2011-01-22 00:00:00 | 1 | 0 | 0 | 1 | 1.64 | 1.515 | 45 | 16.9979 |
| 72 | 2011-01-23 01:00:00 | 1 | 0 | 0 | 1 | 1.64 | 3.790 | 57 | 7.0015 |
| 96 | 2011-01-24 03:00:00 | 1 | 0 | 1 | 1 | 1.64 | 1.515 | 45 | 16.9979 |
| 120 | 2011-01-25 04:00:00 | 1 | 0 | 1 | 1 | 5.74 | 8.335 | 74 | 7.0015 |
| 144 | 2011-01-26 06:00:00 | 1 | 0 | 1 | 3 | 8.20 | 9.090 | 86 | 19.0012 |
| 168 | 2011-01-28 05:00:00 | 1 | 0 | 1 | 2 | 7.38 | 10.605 | 80 | 7.0015 |
| 192 | 2011-01-29 06:00:00 | 1 | 0 | 0 | 1 | 6.56 | 9.090 | 64 | 8.9981 |
| 216 | 2011-01-30 07:00:00 | 1 | 0 | 0 | 1 | 5.74 | 10.605 | 86 | 0.0000 |
- 시계열분석을 해야하나?
코드들을 확인 (https://www.kaggle.com/c/bike-sharing-demand/code?competitionId=3948&sortBy=voteCount) -> 시계열분석은 아닌것 같지않어?
- 데이터분석전략: 딱히 기세를 모델링할 필요를 못느끼겠음.
- 오히려 시계열을 피처엔지어링하여 회귀문제로 바꾸는게 적절하다.
- 시계열 -> 요일,시간의 피처추출 + 외부자료를 활용하여 휴일유무 체크 + 외부자료를 해당요일의 날씨체크 -> lm(y~X)의 회귀문제로 해석!
4. 적합1 -> 제출1
A. 적합
set(df_train.columns) - set(df_test.columns){'casual', 'count', 'registered'}- 데이터 전처리
df_train_featured = df_train.copy()
df_test_featured = df_test.copy()
#---#
df_train_featured = df_train_featured.drop(['casual','registered'],axis=1)- step2~4
# step1 -- pass
# step2
predictr = TabularPredictor(label='count')
# step3
predictr.fit(df_train_featured)
# step4
yhat = predictr.predict(df_train_featured)
yyhat = predictr.predict(df_test_featured)No path specified. Models will be saved in: "AutogluonModels/ag-20231209_040303"
No presets specified! To achieve strong results with AutoGluon, it is recommended to use the available presets.
Recommended Presets (For more details refer to https://auto.gluon.ai/stable/tutorials/tabular/tabular-essentials.html#presets):
presets='best_quality' : Maximize accuracy. Default time_limit=3600.
presets='high_quality' : Strong accuracy with fast inference speed. Default time_limit=3600.
presets='good_quality' : Good accuracy with very fast inference speed. Default time_limit=3600.
presets='medium_quality' : Fast training time, ideal for initial prototyping.
Beginning AutoGluon training ...
AutoGluon will save models to "AutogluonModels/ag-20231209_040303"
=================== System Info ===================
AutoGluon Version: 1.0.0
Python Version: 3.11.6
Operating System: Linux
Platform Machine: x86_64
Platform Version: #140-Ubuntu SMP Thu Aug 4 02:23:37 UTC 2022
CPU Count: 128
Memory Avail: 403.41 GB / 503.74 GB (80.1%)
Disk Space Avail: 1159.47 GB / 1757.88 GB (66.0%)
===================================================
Train Data Rows: 10886
Train Data Columns: 9
Label Column: count
AutoGluon infers your prediction problem is: 'regression' (because dtype of label-column == int and many unique label-values observed).
Label info (max, min, mean, stddev): (977, 1, 191.57413, 181.14445)
If 'regression' is not the correct problem_type, please manually specify the problem_type parameter during predictor init (You may specify problem_type as one of: ['binary', 'multiclass', 'regression'])
Problem Type: regression
Preprocessing data ...
Using Feature Generators to preprocess the data ...
Fitting AutoMLPipelineFeatureGenerator...
Available Memory: 413090.20 MB
Train Data (Original) Memory Usage: 1.45 MB (0.0% of available memory)
Inferring data type of each feature based on column values. Set feature_metadata_in to manually specify special dtypes of the features.
Stage 1 Generators:
Fitting AsTypeFeatureGenerator...
Note: Converting 2 features to boolean dtype as they only contain 2 unique values.
Stage 2 Generators:
Fitting FillNaFeatureGenerator...
Stage 3 Generators:
Fitting IdentityFeatureGenerator...
Fitting DatetimeFeatureGenerator...
Stage 4 Generators:
Fitting DropUniqueFeatureGenerator...
Stage 5 Generators:
Fitting DropDuplicatesFeatureGenerator...
Types of features in original data (raw dtype, special dtypes):
('float', []) : 3 | ['temp', 'atemp', 'windspeed']
('int', []) : 5 | ['season', 'holiday', 'workingday', 'weather', 'humidity']
('object', ['datetime_as_object']) : 1 | ['datetime']
Types of features in processed data (raw dtype, special dtypes):
('float', []) : 3 | ['temp', 'atemp', 'windspeed']
('int', []) : 3 | ['season', 'weather', 'humidity']
('int', ['bool']) : 2 | ['holiday', 'workingday']
('int', ['datetime_as_int']) : 5 | ['datetime', 'datetime.year', 'datetime.month', 'datetime.day', 'datetime.dayofweek']
0.0s = Fit runtime
9 features in original data used to generate 13 features in processed data.
Train Data (Processed) Memory Usage: 0.93 MB (0.0% of available memory)
Data preprocessing and feature engineering runtime = 0.06s ...
AutoGluon will gauge predictive performance using evaluation metric: 'root_mean_squared_error'
This metric's sign has been flipped to adhere to being higher_is_better. The metric score can be multiplied by -1 to get the metric value.
To change this, specify the eval_metric parameter of Predictor()
Automatically generating train/validation split with holdout_frac=0.1, Train Rows: 9797, Val Rows: 1089
User-specified model hyperparameters to be fit:
{
'NN_TORCH': {},
'GBM': [{'extra_trees': True, 'ag_args': {'name_suffix': 'XT'}}, {}, 'GBMLarge'],
'CAT': {},
'XGB': {},
'FASTAI': {},
'RF': [{'criterion': 'gini', 'ag_args': {'name_suffix': 'Gini', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'entropy', 'ag_args': {'name_suffix': 'Entr', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'squared_error', 'ag_args': {'name_suffix': 'MSE', 'problem_types': ['regression', 'quantile']}}],
'XT': [{'criterion': 'gini', 'ag_args': {'name_suffix': 'Gini', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'entropy', 'ag_args': {'name_suffix': 'Entr', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'squared_error', 'ag_args': {'name_suffix': 'MSE', 'problem_types': ['regression', 'quantile']}}],
'KNN': [{'weights': 'uniform', 'ag_args': {'name_suffix': 'Unif'}}, {'weights': 'distance', 'ag_args': {'name_suffix': 'Dist'}}],
}
Fitting 11 L1 models ...
Fitting model: KNeighborsUnif ...
-109.7394 = Validation score (-root_mean_squared_error)
0.01s = Training runtime
0.05s = Validation runtime
Fitting model: KNeighborsDist ...
-92.4421 = Validation score (-root_mean_squared_error)
0.01s = Training runtime
0.05s = Validation runtime
Fitting model: LightGBMXT ...
-135.958 = Validation score (-root_mean_squared_error)
4.83s = Training runtime
0.03s = Validation runtime
Fitting model: LightGBM ...
-134.0804 = Validation score (-root_mean_squared_error)
1.76s = Training runtime
0.02s = Validation runtime
Fitting model: RandomForestMSE ...
-122.0128 = Validation score (-root_mean_squared_error)
0.73s = Training runtime
0.08s = Validation runtime
Fitting model: CatBoost ...
-134.2362 = Validation score (-root_mean_squared_error)
5.98s = Training runtime
0.01s = Validation runtime
Fitting model: ExtraTreesMSE ...
-128.4294 = Validation score (-root_mean_squared_error)
0.62s = Training runtime
0.07s = Validation runtime
Fitting model: NeuralNetFastAI ...
-136.2374 = Validation score (-root_mean_squared_error)
7.58s = Training runtime
0.01s = Validation runtime
Fitting model: XGBoost ...
-135.0751 = Validation score (-root_mean_squared_error)
0.92s = Training runtime
0.0s = Validation runtime
Fitting model: NeuralNetTorch ...
-140.2172 = Validation score (-root_mean_squared_error)
17.69s = Training runtime
0.01s = Validation runtime
Fitting model: LightGBMLarge ...
-132.1736 = Validation score (-root_mean_squared_error)
2.43s = Training runtime
0.01s = Validation runtime
Fitting model: WeightedEnsemble_L2 ...
Ensemble Weights: {'KNeighborsDist': 1.0}
-92.4421 = Validation score (-root_mean_squared_error)
0.3s = Training runtime
0.0s = Validation runtime
AutoGluon training complete, total runtime = 44.11s ... Best model: "WeightedEnsemble_L2"
TabularPredictor saved. To load, use: predictor = TabularPredictor.load("AutogluonModels/ag-20231209_040303")[1000] valid_set's rmse: 136.065- 적합한것을 관찰해보자.
plt.plot(df_train['count'][:300],'--',label='y')
plt.plot(yhat[:300],alpha=0.5,lw=4,label='yhat')
plt.legend()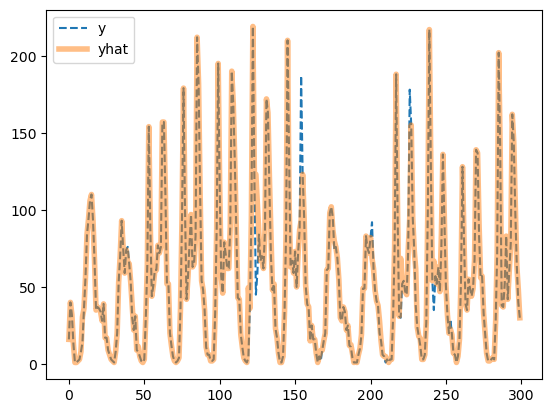
- 잘 맞추는데?.. (수상할 정도로)
B. 제출
- 제출
sampleSubmission['count'] = yyhat
sampleSubmission.to_csv("submission.csv",index=False)
!kaggle competitions submit -c bike-sharing-demand -f submission.csv -m "Message"
!rm submission.csvWarning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /root/.kaggle/kaggle.json'
100%|████████████████████████████████████████| 188k/188k [00:02<00:00, 80.1kB/s]
Successfully submitted to Bike Sharing Demand- 순위확인
3171/3242 # 냈다면0.9780999383096853- yyhat을 살펴봄
plt.plot(yyhat[:300])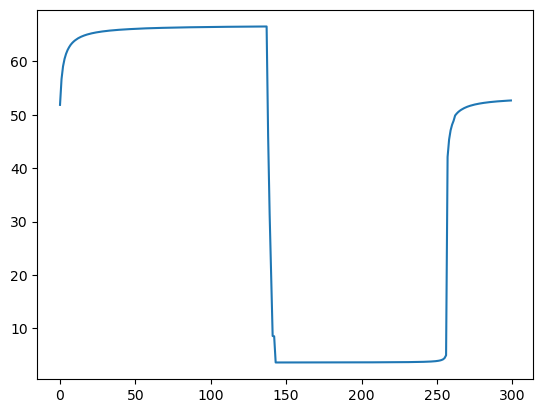
- yhat이랑 모양자체가 너무 다름
5. 적합2 -> 제출2
A. 피처엔지니어링
- 이미 시계열로 적합할 의지가 없으므로 datetime열은 삭제하는게 좋겠음. (인덱스의 역할만 하는 쓸모없는 변수)
df_train_featured = df_train.copy()
df_test_featured = df_test.copy()
#----#
df_train_featured = df_train_featured.drop(['casual','registered'],axis=1)
#--#
df_train_featured = df_train_featured.drop(['datetime'],axis=1)
df_test_featured = df_test_featured.drop(['datetime'],axis=1)B. 적합
- 조용히 적합 (verbosity=False)
# step1 -- pass
# step2
predictr = TabularPredictor(label='count',verbosity=False)
# step3
predictr.fit(df_train_featured)
# step4
yhat = predictr.predict(df_train_featured)
yyhat = predictr.predict(df_test_featured)- 적합결과 시각화
plt.plot(df_train['count'][:300],'--',label='y')
plt.plot(yhat[:300],alpha=0.5,lw=4,label='yhat')
plt.legend()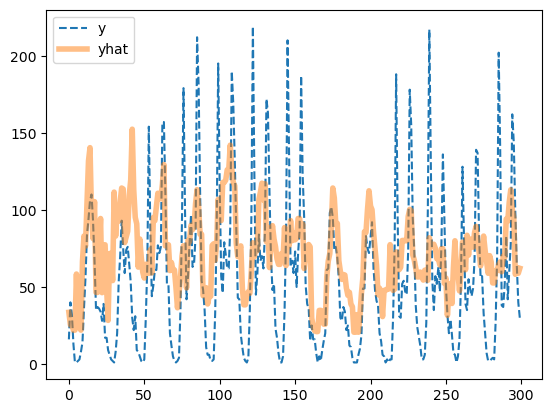
- 오히려 좋아
plt.plot(yyhat[:300],alpha=0.5,lw=4,color='C1')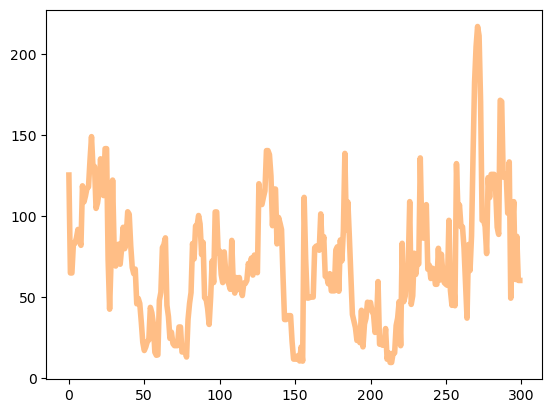
- 더 예쁜 시각화
df = pd.concat([
df_train.assign(count_hat = yhat, dataset_type = 'train'),
df_test.assign(count_hat = yyhat, dataset_type = 'test')
])
df['datetime'] = pd.to_datetime(df['datetime'])
sns.lineplot(
df.sort_values('datetime')[:(24*28)],
x='datetime',y='count',
hue='dataset_type',
linestyle='--',
lw=0.8
)
sns.lineplot(
df.sort_values('datetime')[:(24*28)],
x='datetime',y='count_hat',
hue='dataset_type',
alpha=0.5,
lw=3
)
fig = plt.gcf()
fig.set_size_inches(8,2)
plt.xticks(rotation=15);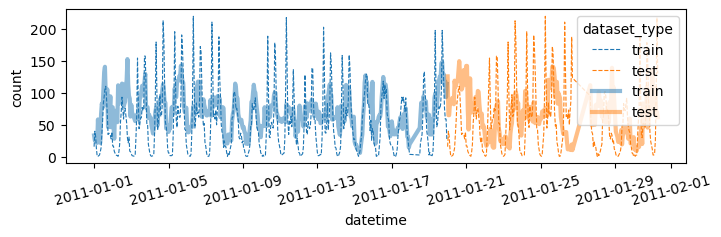
시각화코드를 함수로 구현
def plot(yhat,yyhat):
df = pd.concat([
df_train.assign(count_hat = yhat, dataset_type = 'train'),
df_test.assign(count_hat = yyhat, dataset_type = 'test')
])
df['datetime'] = pd.to_datetime(df['datetime'])
sns.lineplot(
df.sort_values('datetime')[:(24*28)],
x='datetime',y='count',
hue='dataset_type',
linestyle='--',
lw=0.8
)
sns.lineplot(
df.sort_values('datetime')[:(24*28)],
x='datetime',y='count_hat',
hue='dataset_type',
alpha=0.5,
lw=3
)
fig = plt.gcf()
fig.set_size_inches(8,2)
plt.xticks(rotation=15);
fig.show()plot(yhat,yyhat)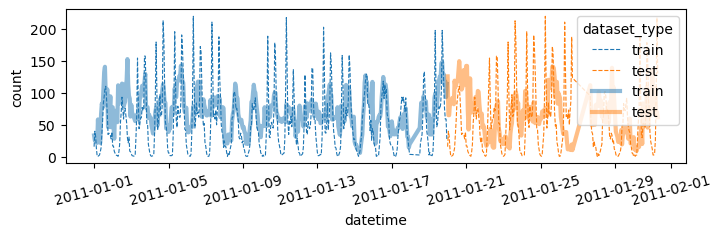
C. 제출
- 제출
sampleSubmission['count'] = yyhat
sampleSubmission.to_csv("submission.csv",index=False)
!kaggle competitions submit -c bike-sharing-demand -f submission.csv -m "Message"
!rm submission.csvWarning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /root/.kaggle/kaggle.json'
100%|████████████████████████████████████████| 188k/188k [00:02<00:00, 90.6kB/s]
Successfully submitted to Bike Sharing Demand- 순위확인
2951/3242 # 냈다면0.9102405922270204D. Pipeline Automation – 싹다 함수로 구현
def fit_predict(df_train_featured, df_test_featured):
# step1 -- pass
# step2
predictr = TabularPredictor(label='count',verbosity=False)
# step3
predictr.fit(df_train_featured)
# step4
yhat = predictr.predict(df_train_featured)
yyhat = predictr.predict(df_test_featured)
# display
display(predictr.leaderboard())
return yhat, yyhat def submit(yyhat):
sampleSubmission['count'] = yyhat
sampleSubmission['count'] = sampleSubmission['count'].apply(lambda x: x if x>0 else 0)
sampleSubmission.to_csv("submission.csv",index=False)
!kaggle competitions submit -c bike-sharing-demand -f submission.csv -m "Message"
!rm submission.csvdef auto(df_train_featured, df_test_featured):
yhat,yyhat = fit_predict(df_train_featured, df_test_featured)
plot(yhat,yyhat)
submit(yyhat)auto(df_train_featured,df_test_featured)| model | score_val | eval_metric | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | WeightedEnsemble_L2 | -147.070191 | root_mean_squared_error | 0.182348 | 27.768169 | 0.000302 | 0.255333 | 2 | True | 12 |
| 1 | CatBoost | -148.454154 | root_mean_squared_error | 0.003159 | 2.127904 | 0.003159 | 2.127904 | 1 | True | 6 |
| 2 | NeuralNetFastAI | -149.187971 | root_mean_squared_error | 0.011869 | 6.467161 | 0.011869 | 6.467161 | 1 | True | 8 |
| 3 | LightGBMLarge | -149.213280 | root_mean_squared_error | 0.050402 | 2.185691 | 0.050402 | 2.185691 | 1 | True | 11 |
| 4 | LightGBMXT | -149.261116 | root_mean_squared_error | 0.044096 | 2.682556 | 0.044096 | 2.682556 | 1 | True | 3 |
| 5 | XGBoost | -149.642096 | root_mean_squared_error | 0.002989 | 0.475692 | 0.002989 | 0.475692 | 1 | True | 9 |
| 6 | LightGBM | -149.739171 | root_mean_squared_error | 0.032944 | 1.124256 | 0.032944 | 1.124256 | 1 | True | 4 |
| 7 | NeuralNetTorch | -151.804414 | root_mean_squared_error | 0.008298 | 13.536022 | 0.008298 | 13.536022 | 1 | True | 10 |
| 8 | ExtraTreesMSE | -156.627917 | root_mean_squared_error | 0.064222 | 0.513502 | 0.064222 | 0.513502 | 1 | True | 7 |
| 9 | RandomForestMSE | -157.475877 | root_mean_squared_error | 0.076336 | 0.700238 | 0.076336 | 0.700238 | 1 | True | 5 |
| 10 | KNeighborsUnif | -165.533975 | root_mean_squared_error | 0.053163 | 0.010039 | 0.053163 | 0.010039 | 1 | True | 1 |
| 11 | KNeighborsDist | -176.146340 | root_mean_squared_error | 0.048289 | 0.010116 | 0.048289 | 0.010116 | 1 | True | 2 |
Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /root/.kaggle/kaggle.json'
100%|█████████████████████████████████████████| 243k/243k [00:02<00:00, 110kB/s]
Successfully submitted to Bike Sharing Demand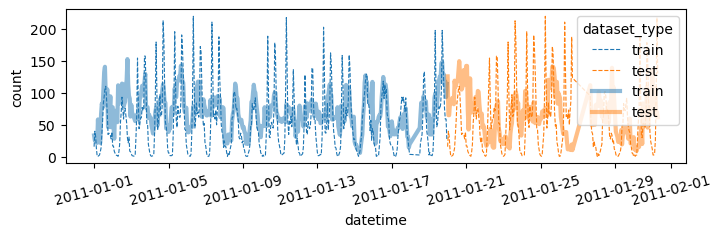
6. 적합3 -> 제출3
A. 시간정보 피처엔지니어링
df_train_featured = df_train.copy()
df_test_featured = df_test.copy()
#----#
df_train_featured = df_train_featured.drop(['casual','registered'],axis=1)
#--#
df_train_featured['hour'] = df_train_featured['datetime'].apply(pd.to_datetime).dt.hour
df_test_featured['hour'] = df_test_featured['datetime'].apply(pd.to_datetime).dt.hour
df_train_featured['weekday'] = df_train_featured['datetime'].apply(pd.to_datetime).dt.weekday
df_test_featured['weekday'] = df_test_featured['datetime'].apply(pd.to_datetime).dt.weekday
#--#
df_train_featured = df_train_featured.drop(['datetime'],axis=1)
df_test_featured = df_test_featured.drop(['datetime'],axis=1)B. 적합 -> 시각화 -> 제출
auto(df_train_featured,df_test_featured)| model | score_val | eval_metric | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | WeightedEnsemble_L2 | -59.472505 | root_mean_squared_error | 0.160467 | 102.555544 | 0.000273 | 0.230394 | 2 | True | 12 |
| 1 | LightGBMLarge | -60.899261 | root_mean_squared_error | 0.036844 | 3.531039 | 0.036844 | 3.531039 | 1 | True | 11 |
| 2 | CatBoost | -61.268467 | root_mean_squared_error | 0.005855 | 53.566333 | 0.005855 | 53.566333 | 1 | True | 6 |
| 3 | LightGBM | -61.447456 | root_mean_squared_error | 0.027921 | 4.429928 | 0.027921 | 4.429928 | 1 | True | 4 |
| 4 | XGBoost | -61.749260 | root_mean_squared_error | 0.004624 | 1.050335 | 0.004624 | 1.050335 | 1 | True | 9 |
| 5 | LightGBMXT | -62.400538 | root_mean_squared_error | 0.078089 | 11.691257 | 0.078089 | 11.691257 | 1 | True | 3 |
| 6 | RandomForestMSE | -67.993149 | root_mean_squared_error | 0.078065 | 0.678181 | 0.078065 | 0.678181 | 1 | True | 5 |
| 7 | ExtraTreesMSE | -68.246627 | root_mean_squared_error | 0.077494 | 0.657480 | 0.077494 | 0.657480 | 1 | True | 7 |
| 8 | NeuralNetTorch | -70.123163 | root_mean_squared_error | 0.006862 | 28.056258 | 0.006862 | 28.056258 | 1 | True | 10 |
| 9 | NeuralNetFastAI | -70.953605 | root_mean_squared_error | 0.012594 | 7.461864 | 0.012594 | 7.461864 | 1 | True | 8 |
| 10 | KNeighborsDist | -115.023130 | root_mean_squared_error | 0.042271 | 0.012108 | 0.042271 | 0.012108 | 1 | True | 2 |
| 11 | KNeighborsUnif | -117.802477 | root_mean_squared_error | 0.054112 | 0.011977 | 0.054112 | 0.011977 | 1 | True | 1 |
Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /root/.kaggle/kaggle.json'
100%|█████████████████████████████████████████| 240k/240k [00:02<00:00, 100kB/s]
Successfully submitted to Bike Sharing Demand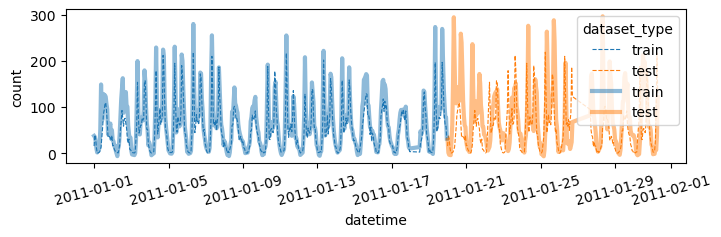
7. 추가적인 피처엔지니어링
A. Step1 – 관련없는 변수 삭제
- 지금까지 수행한 피처엔지니어링
df_train_featured = df_train.copy()
df_test_featured = df_test.copy()
#----#
df_train_featured = df_train_featured.drop(['casual','registered'],axis=1)
#--#
df_train_featured['hour'] = df_train_featured['datetime'].apply(pd.to_datetime).dt.hour
df_test_featured['hour'] = df_test_featured['datetime'].apply(pd.to_datetime).dt.hour
df_train_featured['weekday'] = df_train_featured['datetime'].apply(pd.to_datetime).dt.weekday
df_test_featured['weekday'] = df_test_featured['datetime'].apply(pd.to_datetime).dt.weekday
#--#
df_train_featured = df_train_featured.drop(['datetime'],axis=1)
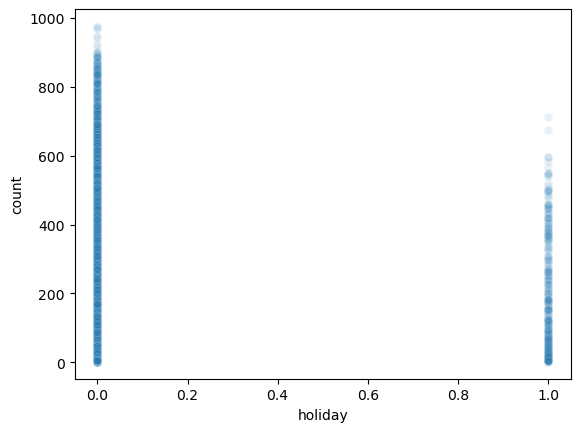
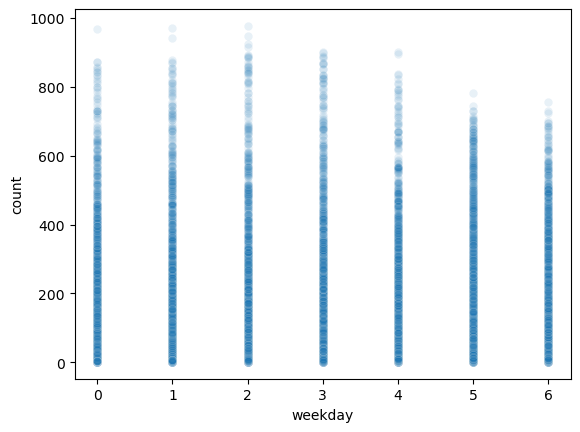
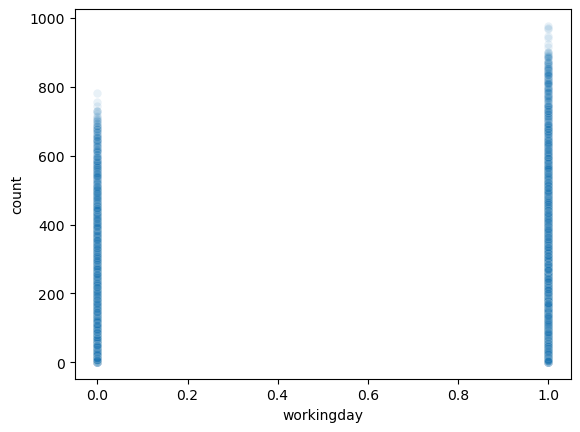
df_test_featured = df_test_featured.drop(['datetime'],axis=1)sns.heatmap(df_train_featured.set_index('count').reset_index().corr(),vmin=-1,cmap='bwr')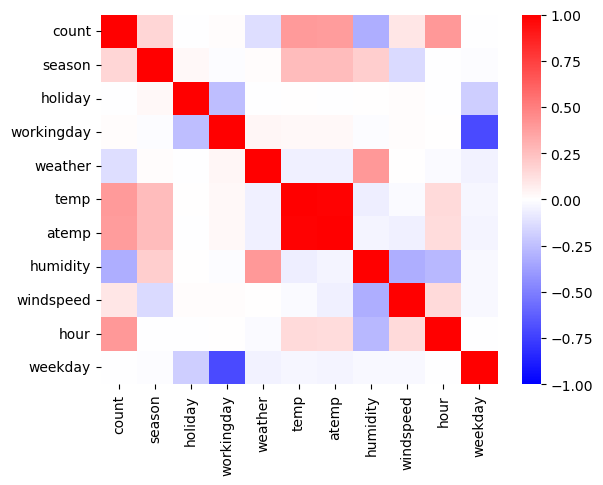
holiday,workingday,weekday는count와 관련이 없어보인다. –> 제외하고 분석
auto(
df_train_featured.drop(['holiday', 'workingday', 'weekday'],axis=1),
df_test_featured.drop(['holiday', 'workingday', 'weekday'],axis=1)
)| model | score_val | eval_metric | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | WeightedEnsemble_L2 | -100.811852 | root_mean_squared_error | 0.130116 | 32.678869 | 0.000304 | 0.258545 | 2 | True | 12 |
| 1 | CatBoost | -101.264453 | root_mean_squared_error | 0.003053 | 3.094043 | 0.003053 | 3.094043 | 1 | True | 6 |
| 2 | LightGBMXT | -102.499627 | root_mean_squared_error | 0.021793 | 2.806028 | 0.021793 | 2.806028 | 1 | True | 3 |
| 3 | LightGBMLarge | -102.767101 | root_mean_squared_error | 0.027591 | 2.559321 | 0.027591 | 2.559321 | 1 | True | 11 |
| 4 | XGBoost | -103.481823 | root_mean_squared_error | 0.003191 | 0.496949 | 0.003191 | 0.496949 | 1 | True | 9 |
| 5 | LightGBM | -103.565687 | root_mean_squared_error | 0.047415 | 1.806251 | 0.047415 | 1.806251 | 1 | True | 4 |
| 6 | RandomForestMSE | -106.378229 | root_mean_squared_error | 0.077816 | 0.727026 | 0.077816 | 0.727026 | 1 | True | 5 |
| 7 | NeuralNetTorch | -106.419608 | root_mean_squared_error | 0.008311 | 19.564728 | 0.008311 | 19.564728 | 1 | True | 10 |
| 8 | ExtraTreesMSE | -106.730503 | root_mean_squared_error | 0.076892 | 0.508729 | 0.076892 | 0.508729 | 1 | True | 7 |
| 9 | NeuralNetFastAI | -107.815196 | root_mean_squared_error | 0.013042 | 6.475207 | 0.013042 | 6.475207 | 1 | True | 8 |
| 10 | KNeighborsUnif | -128.806002 | root_mean_squared_error | 0.052252 | 0.010688 | 0.052252 | 0.010688 | 1 | True | 1 |
| 11 | KNeighborsDist | -128.946333 | root_mean_squared_error | 0.050873 | 0.010892 | 0.050873 | 0.010892 | 1 | True | 2 |
Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /root/.kaggle/kaggle.json'
100%|█████████████████████████████████████████| 242k/242k [00:02<00:00, 121kB/s]
Successfully submitted to Bike Sharing Demand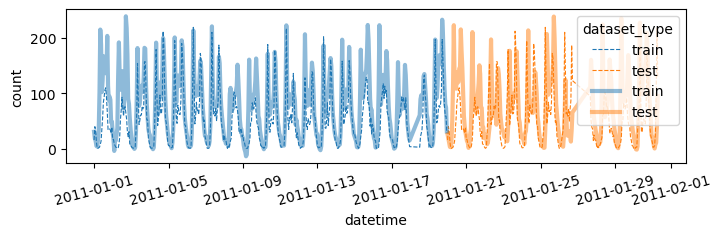
- 안좋아졌음..
- 왜 이런 결과가 나오는가?
sex = np.array([0,0,0,0]*100+[0] + [1]+[1,1,1,1]*100 + [2]*401)
surv = np.array([0,0,0,0]*100+[1] + [0]+[1,1,1,1]*100 + [0]*401)
surv_conti = surv + np.random.randn(len(surv))*0.1
_df = pd.DataFrame({'sex':sex, 'surv':surv, 'surv_conti':surv_conti})
_df.corr()| sex | surv | surv_conti | |
|---|---|---|---|
| sex | 1.000000 | -0.002160 | 0.002214 |
| surv | -0.002160 | 1.000000 | 0.977947 |
| surv_conti | 0.002214 | 0.977947 | 1.000000 |
sns.scatterplot(_df, x='sex',y='surv_conti',alpha=0.5)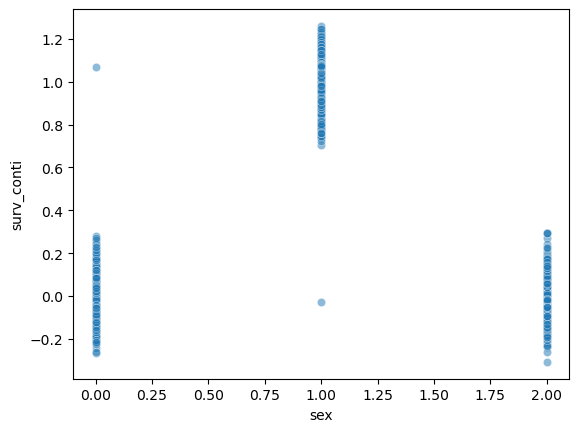
surv_conti.mean()0.3337914660254895sns.heatmap(_df.corr(),cmap='bwr',vmin=-1)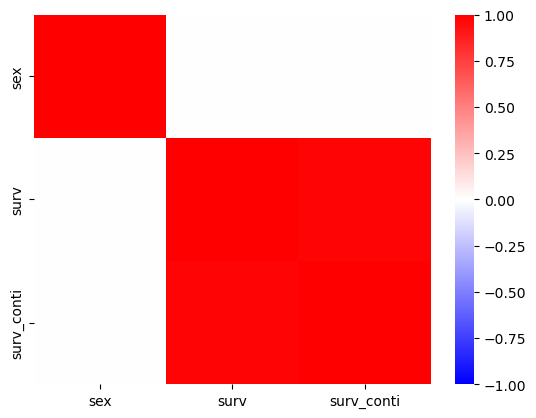
- 우리의 예제
sns.scatterplot(
df_train_featured,
x='holiday',
y='count',
alpha=0.1
)
sns.scatterplot(
df_train_featured,
x='weekday',
y='count',
alpha=0.1
)
sns.scatterplot(
df_train_featured,
x='workingday',
y='count',
alpha=0.1
)
B. Step2 – atemp 혹은 temp 삭제
- 지금까지 한 피처엔지니어링
df_train_featured = df_train.copy()
df_test_featured = df_test.copy()
#----#
df_train_featured = df_train_featured.drop(['casual','registered'],axis=1)
#--#
df_train_featured['hour'] = df_train_featured['datetime'].apply(pd.to_datetime).dt.hour
df_test_featured['hour'] = df_test_featured['datetime'].apply(pd.to_datetime).dt.hour
df_train_featured['weekday'] = df_train_featured['datetime'].apply(pd.to_datetime).dt.weekday
df_test_featured['weekday'] = df_test_featured['datetime'].apply(pd.to_datetime).dt.weekday
#--#
df_train_featured = df_train_featured.drop(['datetime'],axis=1)
df_test_featured = df_test_featured.drop(['datetime'],axis=1)sns.heatmap(df_train_featured.set_index('count').reset_index().corr(),vmin=-1,cmap='bwr')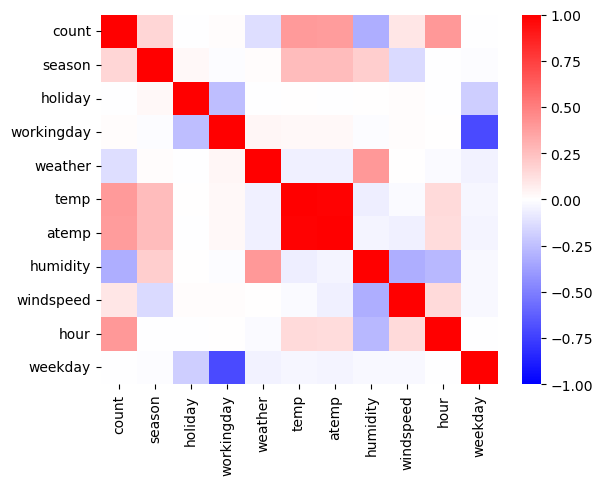
- temp와 atemp가 동시에 있어서 공선성 문제를 만들 수 있어보임.
- 둘중 하나를 제거하는게 좋을것 같음.
auto(
df_train_featured.drop(['temp'],axis=1),
df_test_featured.drop(['temp'],axis=1)
)| model | score_val | eval_metric | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | WeightedEnsemble_L2 | -59.874523 | root_mean_squared_error | 0.213646 | 94.690214 | 0.000268 | 0.274809 | 2 | True | 12 |
| 1 | LightGBMLarge | -61.029920 | root_mean_squared_error | 0.025669 | 4.190605 | 0.025669 | 4.190605 | 1 | True | 11 |
| 2 | LightGBM | -61.580307 | root_mean_squared_error | 0.051359 | 4.562051 | 0.051359 | 4.562051 | 1 | True | 4 |
| 3 | CatBoost | -61.849961 | root_mean_squared_error | 0.004514 | 30.347588 | 0.004514 | 30.347588 | 1 | True | 6 |
| 4 | XGBoost | -62.741724 | root_mean_squared_error | 0.005328 | 1.198318 | 0.005328 | 1.198318 | 1 | True | 9 |
| 5 | LightGBMXT | -63.351618 | root_mean_squared_error | 0.118029 | 15.534946 | 0.118029 | 15.534946 | 1 | True | 3 |
| 6 | ExtraTreesMSE | -67.852239 | root_mean_squared_error | 0.075321 | 0.542953 | 0.075321 | 0.542953 | 1 | True | 7 |
| 7 | RandomForestMSE | -68.525817 | root_mean_squared_error | 0.077494 | 0.725492 | 0.077494 | 0.725492 | 1 | True | 5 |
| 8 | NeuralNetTorch | -69.257115 | root_mean_squared_error | 0.008478 | 38.581897 | 0.008478 | 38.581897 | 1 | True | 10 |
| 9 | NeuralNetFastAI | -71.600811 | root_mean_squared_error | 0.014673 | 8.173447 | 0.014673 | 8.173447 | 1 | True | 8 |
| 10 | KNeighborsDist | -114.334789 | root_mean_squared_error | 0.052239 | 0.011158 | 0.052239 | 0.011158 | 1 | True | 2 |
| 11 | KNeighborsUnif | -116.835940 | root_mean_squared_error | 0.054235 | 0.013121 | 0.054235 | 0.013121 | 1 | True | 1 |
Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /root/.kaggle/kaggle.json'
100%|████████████████████████████████████████| 241k/241k [00:02<00:00, 97.9kB/s]
Successfully submitted to Bike Sharing Demand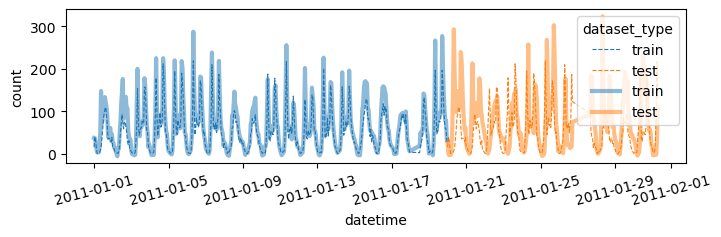
auto(
df_train_featured.drop(['atemp'],axis=1),
df_test_featured.drop(['atemp'],axis=1)
)| model | score_val | eval_metric | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | WeightedEnsemble_L2 | -59.150386 | root_mean_squared_error | 0.112297 | 97.533941 | 0.000265 | 0.235395 | 2 | True | 12 |
| 1 | LightGBMLarge | -60.667457 | root_mean_squared_error | 0.059140 | 4.487036 | 0.059140 | 4.487036 | 1 | True | 11 |
| 2 | CatBoost | -60.919338 | root_mean_squared_error | 0.004688 | 24.538936 | 0.004688 | 24.538936 | 1 | True | 6 |
| 3 | LightGBMXT | -61.740606 | root_mean_squared_error | 0.018670 | 7.857827 | 0.018670 | 7.857827 | 1 | True | 3 |
| 4 | LightGBM | -62.028032 | root_mean_squared_error | 0.019760 | 4.145746 | 0.019760 | 4.145746 | 1 | True | 4 |
| 5 | XGBoost | -62.503591 | root_mean_squared_error | 0.005588 | 1.158510 | 0.005588 | 1.158510 | 1 | True | 9 |
| 6 | NeuralNetTorch | -66.530385 | root_mean_squared_error | 0.009775 | 56.269001 | 0.009775 | 56.269001 | 1 | True | 10 |
| 7 | RandomForestMSE | -67.814371 | root_mean_squared_error | 0.077477 | 0.720543 | 0.077477 | 0.720543 | 1 | True | 5 |
| 8 | ExtraTreesMSE | -67.843089 | root_mean_squared_error | 0.075053 | 0.525805 | 0.075053 | 0.525805 | 1 | True | 7 |
| 9 | NeuralNetFastAI | -71.099099 | root_mean_squared_error | 0.016411 | 8.586244 | 0.016411 | 8.586244 | 1 | True | 8 |
| 10 | KNeighborsDist | -112.678494 | root_mean_squared_error | 0.054687 | 0.011276 | 0.054687 | 0.011276 | 1 | True | 2 |
| 11 | KNeighborsUnif | -115.103505 | root_mean_squared_error | 0.055619 | 0.010588 | 0.055619 | 0.010588 | 1 | True | 1 |
Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /root/.kaggle/kaggle.json'
100%|█████████████████████████████████████████| 241k/241k [00:02<00:00, 104kB/s]
Successfully submitted to Bike Sharing Demand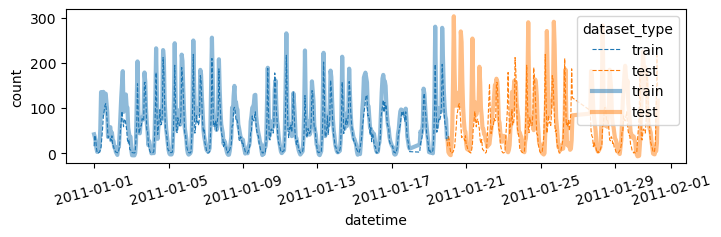
C. Step3 – season을 범주로?
- 지금까지한 피처엔지니어링
df_train_featured = df_train.copy()
df_test_featured = df_test.copy()
#----#
df_train_featured = df_train_featured.drop(['casual','registered'],axis=1)
#--#
df_train_featured['hour'] = df_train_featured['datetime'].apply(pd.to_datetime).dt.hour
df_test_featured['hour'] = df_test_featured['datetime'].apply(pd.to_datetime).dt.hour
df_train_featured['weekday'] = df_train_featured['datetime'].apply(pd.to_datetime).dt.weekday
df_test_featured['weekday'] = df_test_featured['datetime'].apply(pd.to_datetime).dt.weekday
#--#
df_train_featured = df_train_featured.drop(['datetime'],axis=1)
df_test_featured = df_test_featured.drop(['datetime'],axis=1)
#--#
df_train_featured = df_train_featured.drop(['atemp'],axis=1)
df_test_featured = df_test_featured.drop(['atemp'],axis=1)- 사실 season의 의미는 season - 1 = spring, 2 = summer, 3 = fall, 4 = winter 임
- 지금은 season이 1,2,3,4로 코딩되어 있는데, 이것을 문자열로 바꾸면 더 좋지 않을까?
auto(
df_train_featured.assign(season = df_train_featured.season.map({1:'spring',2:'summer',3:'fall',4:'winter'})),
df_test_featured.assign(season = df_train_featured.season.map({1:'spring',2:'summer',3:'fall',4:'winter'}))
)| model | score_val | eval_metric | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | WeightedEnsemble_L2 | -59.036404 | root_mean_squared_error | 0.180270 | 166.629132 | 0.000298 | 0.231156 | 2 | True | 12 |
| 1 | LightGBMXT | -61.072683 | root_mean_squared_error | 0.137849 | 16.966092 | 0.137849 | 16.966092 | 1 | True | 3 |
| 2 | LightGBMLarge | -61.188052 | root_mean_squared_error | 0.014302 | 5.454212 | 0.014302 | 5.454212 | 1 | True | 11 |
| 3 | CatBoost | -62.040378 | root_mean_squared_error | 0.010296 | 99.871253 | 0.010296 | 99.871253 | 1 | True | 6 |
| 4 | LightGBM | -62.161719 | root_mean_squared_error | 0.056212 | 4.405833 | 0.056212 | 4.405833 | 1 | True | 4 |
| 5 | XGBoost | -62.183089 | root_mean_squared_error | 0.008397 | 1.486745 | 0.008397 | 1.486745 | 1 | True | 9 |
| 6 | RandomForestMSE | -68.346914 | root_mean_squared_error | 0.079247 | 0.665509 | 0.079247 | 0.665509 | 1 | True | 5 |
| 7 | NeuralNetTorch | -68.374797 | root_mean_squared_error | 0.009130 | 42.619673 | 0.009130 | 42.619673 | 1 | True | 10 |
| 8 | ExtraTreesMSE | -68.569688 | root_mean_squared_error | 0.076242 | 0.539613 | 0.076242 | 0.539613 | 1 | True | 7 |
| 9 | NeuralNetFastAI | -72.510574 | root_mean_squared_error | 0.014984 | 7.550716 | 0.014984 | 7.550716 | 1 | True | 8 |
| 10 | KNeighborsDist | -113.647125 | root_mean_squared_error | 0.053068 | 0.010152 | 0.053068 | 0.010152 | 1 | True | 2 |
| 11 | KNeighborsUnif | -116.110797 | root_mean_squared_error | 0.060565 | 0.010118 | 0.060565 | 0.010118 | 1 | True | 1 |
Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /root/.kaggle/kaggle.json'
100%|█████████████████████████████████████████| 240k/240k [00:02<00:00, 118kB/s]
Successfully submitted to Bike Sharing Demand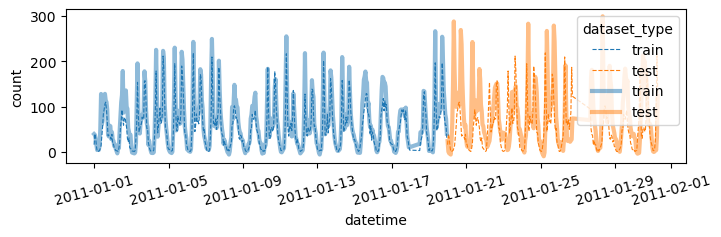
- 이건 적용하지 말자.
- 어차피 트리계열은 명목형변수를 순서형변수로 잘못 적용해도 크게 상관없음.
D. Step4 – \(y\)의 분포
- 지금까지한 피처엔지니어링
df_train_featured = df_train.copy()
df_test_featured = df_test.copy()
#----#
df_train_featured = df_train_featured.drop(['casual','registered'],axis=1)
#--#
df_train_featured['hour'] = df_train_featured['datetime'].apply(pd.to_datetime).dt.hour
df_test_featured['hour'] = df_test_featured['datetime'].apply(pd.to_datetime).dt.hour
df_train_featured['weekday'] = df_train_featured['datetime'].apply(pd.to_datetime).dt.weekday
df_test_featured['weekday'] = df_test_featured['datetime'].apply(pd.to_datetime).dt.weekday
#--#
df_train_featured = df_train_featured.drop(['datetime'],axis=1)
df_test_featured = df_test_featured.drop(['datetime'],axis=1)
#--#
df_train_featured = df_train_featured.drop(['atemp'],axis=1)
df_test_featured = df_test_featured.drop(['atemp'],axis=1)df_train_featured['count'].hist() # 정규분포가 아니네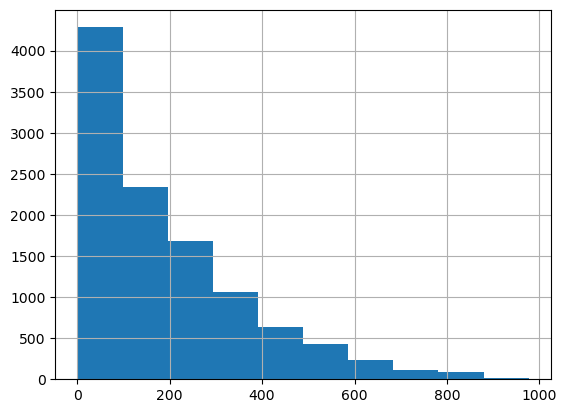
transfomr = sklearn.preprocessing.PowerTransformer(method='box-cox')count2 = transfomr.fit_transform(df_train_featured[['count']]).reshape(-1)
plt.hist(count2);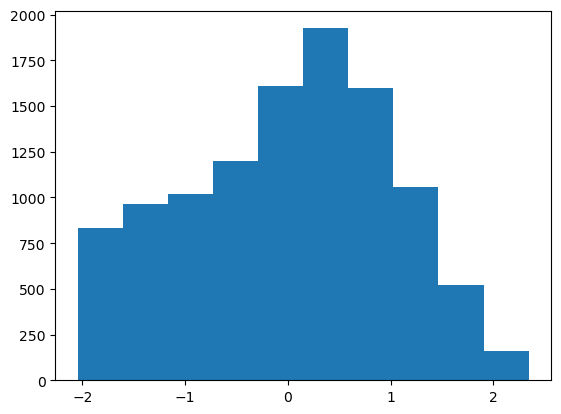
df_train_featured.assign(count = count2)| season | holiday | workingday | weather | temp | humidity | windspeed | count | hour | weekday | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 1 | 9.84 | 81 | 0.0000 | -1.255010 | 0 | 5 |
| 1 | 1 | 0 | 0 | 1 | 9.02 | 80 | 0.0000 | -0.801417 | 1 | 5 |
| 2 | 1 | 0 | 0 | 1 | 9.02 | 80 | 0.0000 | -0.924248 | 2 | 5 |
| 3 | 1 | 0 | 0 | 1 | 9.84 | 75 | 0.0000 | -1.340805 | 3 | 5 |
| 4 | 1 | 0 | 0 | 1 | 9.84 | 75 | 0.0000 | -2.043720 | 4 | 5 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 10881 | 4 | 0 | 1 | 1 | 15.58 | 50 | 26.0027 | 0.928271 | 19 | 2 |
| 10882 | 4 | 0 | 1 | 1 | 14.76 | 57 | 15.0013 | 0.576172 | 20 | 2 |
| 10883 | 4 | 0 | 1 | 1 | 13.94 | 61 | 15.0013 | 0.233448 | 21 | 2 |
| 10884 | 4 | 0 | 1 | 1 | 13.94 | 61 | 6.0032 | 0.006178 | 22 | 2 |
| 10885 | 4 | 0 | 1 | 1 | 13.12 | 66 | 8.9981 | -0.291061 | 23 | 2 |
10886 rows × 10 columns
- 적합
# step1 -- pass
# step2
predictr = TabularPredictor(label='count',verbosity=False)
# step3
predictr.fit(df_train_featured.assign(count = count2))
# step4
yhat = predictr.predict(df_train_featured)
yyhat = predictr.predict(df_test_featured)yhat = transfomr.inverse_transform(yhat.to_frame()).reshape(-1)
yyhat = transfomr.inverse_transform(yyhat.to_frame()).reshape(-1)plot(yhat,yyhat)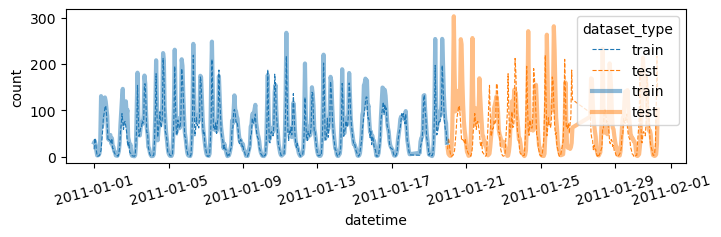
submit(yyhat)Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /root/.kaggle/kaggle.json'
100%|█████████████████████████████████████████| 243k/243k [00:02<00:00, 120kB/s]
Successfully submitted to Bike Sharing Demand
8. HW
box-cox transform이 아닌 log1p변환을 취해서 결과를 구해볼 것
np.log1p(0.1234), np.log(0.1234+1)(0.11635980111619529, 0.11635980111619525)np.expm1(0.11635980111619529)0.1234결과는 아래와 같음