11wk-2: 최대가능도추정 (3)
2025-11-13
“추정을 잘한다”란?
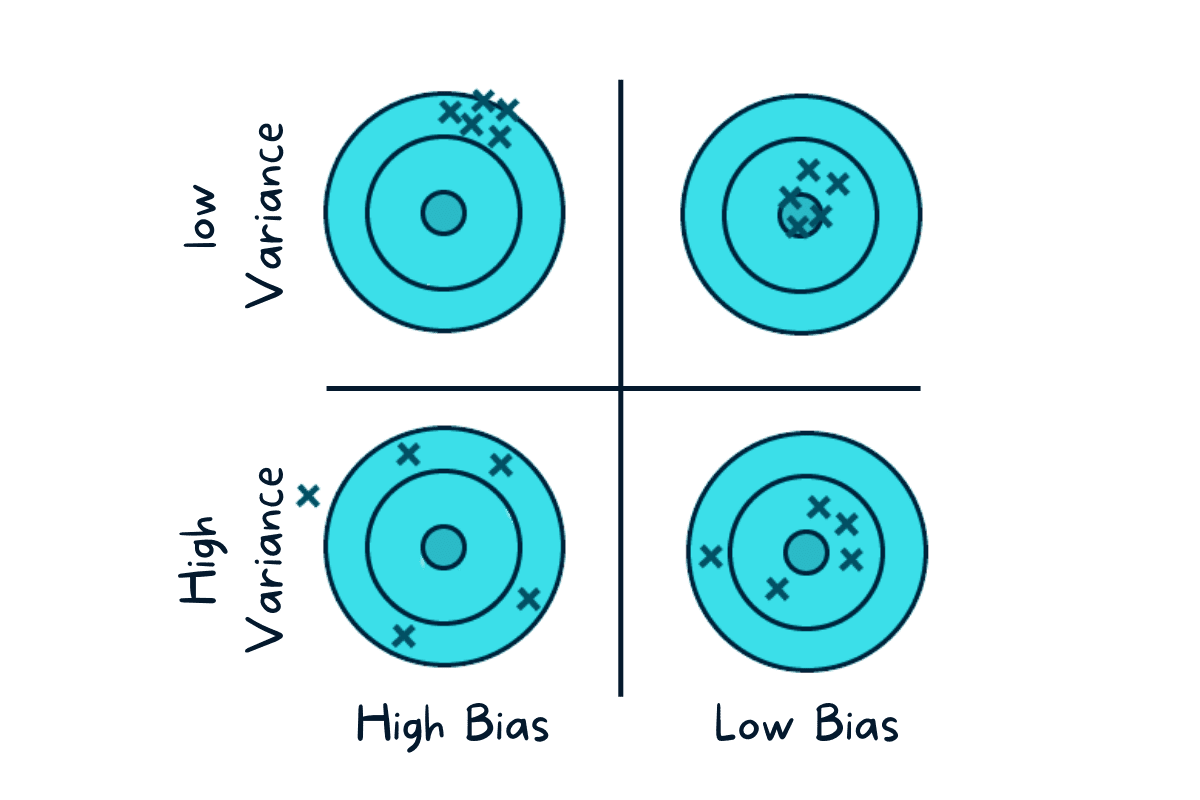
그림1: 솜씨좋은 사격사?
ref: https://www.kdnuggets.com/2022/08/biasvariance-tradeoff.html
# 예제1
아래와 같은 데이터를 관찰하자.
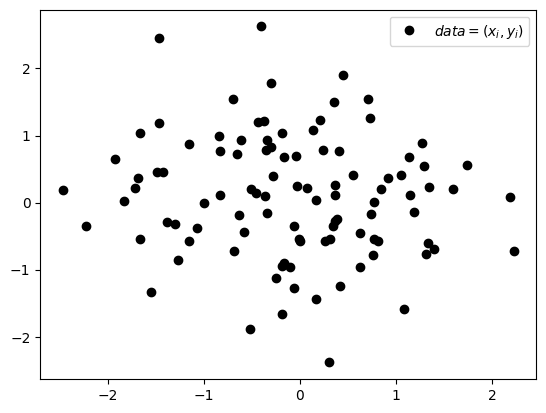
그림2: \(data=(x_i,y_i)\)의 산점도
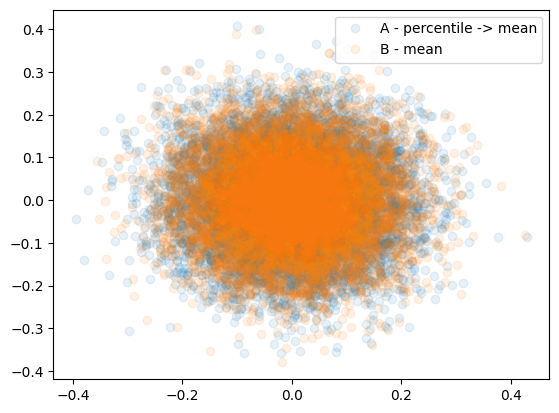
그림3: A방식, B방식으로 추정한 결과 // B가 좀 더 우수해보인다.
#
# 예제2
다시 아래와 같은 데이터를 상상하자.
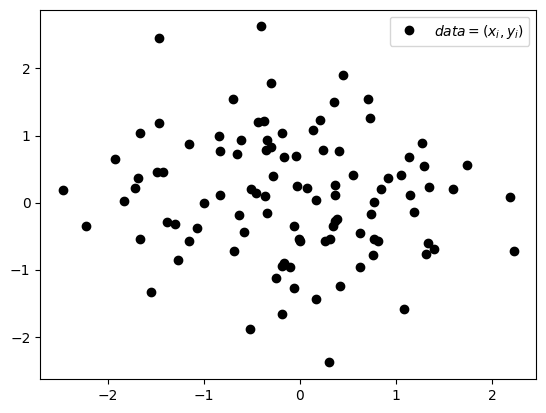
.
중심을 추정하는 문제를 고려하자.
- A: 중앙값 한번 써보는게 어때?
- B: 그냥 평균으로 추정하는게 젤 좋다니까?
누구의 말이 더 합리적일까?
A = []
B = []
for i in range(10000):
x = np.random.normal(size=100)
y = np.random.normal(size=100)
#---#
A.append([np.median(x),np.median(y)])
B.append([np.mean(x),np.mean(y)])
A = np.array(A)
B = np.array(B)
plt.plot(A[:,0],A[:,1],'o',alpha=0.1,label="A - median")
plt.plot(B[:,0],B[:,1],'o',alpha=0.1,label="B - mean")
plt.legend()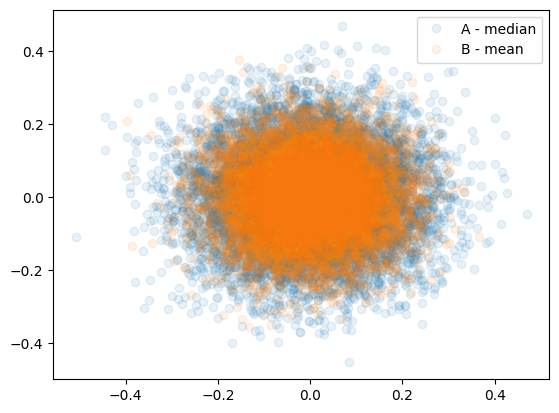
그림4: A방식, B방식으로 추정한 결과 // 역시 평균기법인 B가 더 우수해보인다.
# 예제3
이제 아래와 같은 데이터를 상상하자.
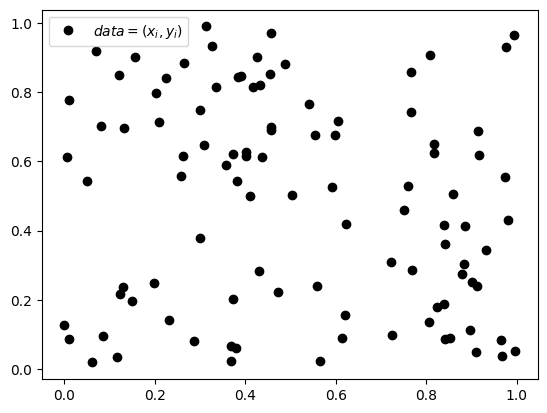
그림5: \(data=(x_i,y_i)\)의 산점도, \(x_i,y_i\) 모두 0~1사이의 숫자를 (같은확률로) 뽑은것이다.
A = []
B = []
for i in range(10000):
x = np.random.uniform(size=100)
y = np.random.uniform(size=100)
#---#
A.append([np.mean(x),np.mean(y)])
B.append([(min(x)+max(x))/2,(min(y)+max(y))/2])
A = np.array(A)
B = np.array(B)
plt.plot(A[:,0],A[:,1],'o',alpha=0.1,label="A - $(\\bar{x},\\bar{y})$")
plt.plot(B[:,0],B[:,1],'o',alpha=0.1,label="B - $\\left(\\frac{min(x)+max(x)}{2},\\frac{min(y)+max(y)}{2}\\right)$")
plt.legend()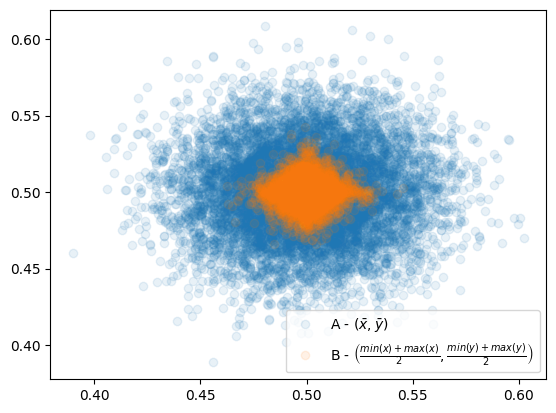
그림4: A방식, B방식으로 추정한 결과