Quiz-16 (2026.04.29) // 범위: ~08wk
1. MNIST 예제
손글씨 숫자 이미지 (\(28 \times 28\)) 중 3 과 7 만 골라낸 데이터로 binary classification 을 한다. 입력은 \((n, 784)\) 로 평탄화하고, 출력은 \(y_i \in \{0, 1\}\) (3 → 0, 7 → 1) 이다.
(1) 다음 수식 표현으로 정의되는 네트워크와 손실함수를 구현하려고 한다.
네트워크:
\[\underset{(n,784)}{\bf X} \overset{l_1}{\to} \underset{(n,32)}{\bf U^{(1)}} \overset{relu}{\to} \underset{(n,32)}{\bf V^{(1)}} \overset{l_2}{\to} \underset{(n,1)}{\bf U^{(2)}} \overset{sig}{\to} \underset{(n,1)}{\bf V^{(2)}} = \hat{\bf Y}\]
여기서 \(l_1, l_2\) 는 선형 변환 (Linear), \(\text{relu}, \text{sig}\) 는 각각 ReLU·Sigmoid 활성화 함수이다.
손실함수:
\[loss = -\frac{1}{n}\sum_{i=1}^{n}\big(y_i\log(\hat{y}_i) + (1-y_i)\log(1-\hat{y}_i)\big)\]
다음 코드의 빈칸 ??? 을 채워 위 네트워크와 손실함수를 완성하시오.
net = torch.nn.Sequential(
torch.nn.Linear(in_features=???, out_features=???),
torch.nn.???(),
torch.nn.Linear(in_features=???, out_features=???),
torch.nn.???()
)
loss_fn = torch.nn.???()net = torch.nn.Sequential(
torch.nn.Linear(in_features=784, out_features=32),
torch.nn.ReLU(),
torch.nn.Linear(in_features=32, out_features=1),
torch.nn.Sigmoid()
)
loss_fn = torch.nn.BCELoss()(2) 위 네트워크와 시벤코 정리·George Box 격언의 관계에 대해 옳은 것을 모두 고르시오.
(a) 시벤코의 정리에 따르면 은닉층의 노드 수를 충분히 키우면 손글씨 이미지와 숫자 사이의 참함수를 정확히 몰라도 학습 데이터에 거의 완벽히 맞출 수 있다.
(b) 시벤코의 정리는 우리가 찾고자 하는 참함수의 구체적 형태 까지 알려준다.
(c) George Box 의 “All models are wrong, but some are useful” 의 시각에 따르면, 위 네트워크가 참함수를 식별했는지는 중요하지 않고, 손글씨 이미지에 대해 쓸만한 예측을 주는지가 중요하다.
(d) 7주차의 벤다이어그램 (Drew Conway) 에 따르면, 위와 같은 접근은 도메인 지식·컴퓨터과학·수학/통계 세 영역의 교집합 인 데이터과학 영역에 해당한다.
정답: (a), (c)
(a) 시벤코의 정리는 표현력을 보장. 참함수의 구체적 형태를 몰라도 그것을 근사하는 네트워크가 존재함.
(b) 시벤코는 “근사 가능하다” 는 존재성만 보장할 뿐, 참함수가 무엇인지는 알려주지 않움.
(c) Box 의 시각에서는 참모델 식별이 아닌 유용성이 더 중요한 평가의 기준임.
(d) — Drew Conway 다이어그램에서 세 영역의 교집합(= 데이터과학)은 도메인 지식까지 포함된 영역이다. 손글씨를 그냥 큰 네트워크에 던져 적합하는 위 접근은 도메인 지식이 빠져 있으므로, 데이터과학이 아니라 머신러닝 (컴퓨터과학 ∩ 수학/통계) 영역에 해당한다.
2. 오버피팅 예제
다음 데이터를 고려하자.
torch.manual_seed(5)
Xall = torch.linspace(0, 1, 100).reshape(100, 1)
Yall = Xall * 0 + torch.randn(100).reshape(100, 1) * 0.01
X, Y = Xall[:80,:], Yall[:80,:] # 학습용
XX, YY = Xall[80:,:], Yall[80:,:] # 평가용이 데이터의 참모델 은 \(f({\bf X}) = {\bf 0}\) 이고, 관측값에는 \(N(0, 0.01^2)\) 의 작은 노이즈가 섞여 있다. 이를 다음과 같은 네트워크로 1000 epoch 학습했다.
torch.manual_seed(1)
net = torch.nn.Sequential(
torch.nn.Linear(1, 512),
torch.nn.ReLU(),
torch.nn.Linear(512, 1)
)
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters())
#---#
for epoch in range(1000):
Yhat = net(X)
loss = loss_fn(Yhat, Y)
loss.backward()
optimizer.step()
optimizer.zero_grad()학습 후 적합 결과는 다음과 같다 (파란선: 학습구간 \([0, 0.8]\) 의 예측, 주황선: 평가구간 \((0.8, 1]\) 의 예측).
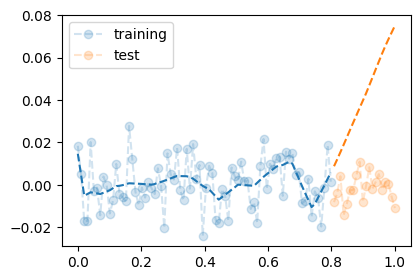
(1) 학습 후 다음 두 손실값을 비교했을 때 옳은 부등호 를 고르시오.
A = loss_fn(net(X), Y) # 학습된 네트워크의 예측 vs 학습 데이터
B = loss_fn(net(X) * 0, Y) # 0 으로 예측 vs 학습 데이터(a) \(A < B\)
(b) \(A > B\)
(c) \(A \approx B\)
정답: (a) \(A < B\).
학습 데이터 80개에 대해 네트워크는 노이즈까지 거의 외웠기 때문에 \(A\)가 \(B\)보다 더 손실이 낮다.
(2) 평가용 데이터 \(({\bf XX}, {\bf YY})\) 에 대해 다음 두 손실값을 비교했을 때 옳은 부등호 를 고르시오.
C = loss_fn(net(XX), YY) # 학습된 네트워크의 예측 vs 평가 데이터
D = loss_fn(net(XX) * 0, YY) # 0 으로 예측 vs 평가 데이터(a) \(C < D\)
(b) \(C > D\)
(c) \(C \approx D\)
정답: (b) \(C > D\).
오버피팅된 네트워크는 학습 구간 \([0, 0.8]\) 에서 노이즈에 맞춰진 꺾인선을 만들고, 평가 구간 \((0.8, 1]\) 에서는 마지막 학습 직선이 그대로 이어져 참값 0 에서 크게 빗나간다. 따라서 그냥 0 으로 예측하는 게 더 낫다.
(3) (1) 과 (2) 의 결과를 종합한다. 비교 대상은 다음 두 네트워크이다.
- 학습된 네트워크: \(\hat{\bf Y} = net({\bf X})\), 1-은닉층 + 노드 수 \(m{=}512\) + ReLU 로 학습된 모형 (위 코드의
net). - 항상 0 만 출력하는 네트워크: \(\hat{\bf Y} = net_0({\bf X}) = {\bf 0}\)
(1)·(2) 의 결과에서 도출되는 결론으로 적절한 것을 모두 고르시오.
(a) \(net\) 은 학습 데이터에서는 \(net_0\) 보다 잘 맞추지만, 평가 데이터에서는 \(net_0\) 보다 못 맞춘다. 이는 오버피팅이 일어난 전형적인 모습이다.
(b) \(net\) 은 학습 데이터와 평가 데이터 모두에서 \(net_0\) 보다 잘 맞춘다. 시벤코의 정리가 unseen data 에 대한 예측까지 보장하기 때문이다.
(c) \(net\) 의 표현력이 부족해서 평가 데이터에서 \(net_0\) 보다 못 맞추는 현상이 발생한다.
(d) \(net\) 의 단점을 보완하려면 드랍아웃 레이어를 추가해야 한다. 그러면 학습 데이터와 평가 데이터 모두에서 \(net\) 의 손실이 \(net_0\) 의 손실보다 작아진다.
정답: (a)
(b) 시벤코정리는 unseen data 에 대한 예측을 보장하지 않는다.
(c) 표현력이 부족해서 생긴 문제가 아니라 표현력이 너무 과해서 오차항까지 적합하여 생긴 문제이다. (오차항을 적합하여 얻은 규칙들이 새로운 오차항에는 전혀 적용되지 않기 때문) (d) 드랍아웃레이어를 추가하면 \(net\)의 단점을 보완하는건 맞으나 그렇다고 해서 평가자료에서 \(net_0\)의 손실보다 작아짐을 보장할 순 없다. (본래의 \(net\)보다는 좋아질 수 있음)
(4) 위 오버피팅의 근본적 원인 으로 가장 적절한 것을 고르시오.
(a) 노드 수 \(m{=}512\) 가 너무 적어서 네트워크의 표현력이 부족했기 때문
(b) 노드 수 \(m{=}512\) 가 너무 많아서 네트워크의 표현력이 과하게 좋았기 때문 (노이즈까지 적합 가능)
(c) Optimizer (Adam) 선택이 잘못되었기 때문
(d) 학습 epoch 수가 너무 부족했기 때문
정답: (b)
3. 드랍아웃
(1) 다음 코드를 고려하자.
torch.manual_seed(0)
u = torch.ones(10) # tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
d = torch.nn.Dropout(0.8)
d(u)d(u) 의 결과로 가장 적절한 설명은?
(a) 모든 원소가 약 \(0.2\) 가 된다.
(b) 임의로 80% 의 원소가 \(0\) 이 되고, 살아남은 20% 의 원소는 그대로 \(1\) 이다.
(c) 임의로 80% 의 원소가 \(0\) 이 되고, 살아남은 20% 의 원소는 \(5\) 가 된다.
(d) 임의로 20% 의 원소가 \(0\) 이 되고, 나머지 80% 는 \(1.25\) 가 된다.
정답: (c)
(2) 다음 4개의 네트워크는 모두 1-은닉층 (은닉노드 512, Sigmoid) 구조에 Dropout 을 끼워 넣은 형태이다. 드랍아웃의 레이어르을 올바르게 이해하고 적용한 네트워크를 고르시오. (계산효율은 고려X)
# (a)
net_a = torch.nn.Sequential(
torch.nn.Linear(1, 512),
torch.nn.Sigmoid(),
torch.nn.Dropout(0.5),
torch.nn.Linear(512, 1)
)
# (b)
net_b = torch.nn.Sequential(
torch.nn.Linear(1, 512),
torch.nn.Dropout(0.5),
torch.nn.Sigmoid(),
torch.nn.Linear(512, 1)
)
# (c)
net_c = torch.nn.Sequential(
torch.nn.Linear(1, 512),
torch.nn.ReLU(),
torch.nn.Dropout(0.5),
torch.nn.Linear(512, 1)
)
# (d)
net_d = torch.nn.Sequential(
torch.nn.Linear(1, 512),
torch.nn.Dropout(0.5),
torch.nn.ReLU(),
torch.nn.Linear(512, 1)
)정답: (a), (c), (d) // (c)와 (d)는 같은효과를 가지는 네트워크지면 효율까지고려하면 (d)가 (c)보다 좀 더 좋다.
(3) 드랍아웃 레이어에 대한 설명으로 옳은 것을 모두 고르시오.
(a) 드랍아웃을 쓰면 오버피팅이 줄어드는 효과가 있다.
(b) 학습 시에는 net.train() 으로 드랍아웃을 켜고, 평가 시에는 net.eval() 로 드랍아웃을 꺼야 한다.
(c) 드랍아웃을 쓰면 네트워크의 표현력이 좋아진다.
(d) 드랍아웃을 쓰면 학습 속도가 항상 빨라진다.
정답: (a), (b)