import torch
import matplotlib.pyplot as plt
import numpy as np
import plotly.graph_objects as go05wk: 로지스틱
![]()
1. 강의영상
2. Imports
plt.rcParams['figure.figsize'] = (4.5,3.0)3. 시그모이드 함수
- 아래와 같은 함수를 시그모이드 함수라고 함.
\[\text{sig}(x)=f(x)=\frac{e^x}{e^x+1}=\frac{1}{e^{-x}+1}\]
- 그래프는 아래와 같이 생겼음.
x = torch.linspace(-10,10,1000)
def f(x):
return torch.exp(x)/ (torch.exp(x)+1)
plt.plot(x,f(x),'--')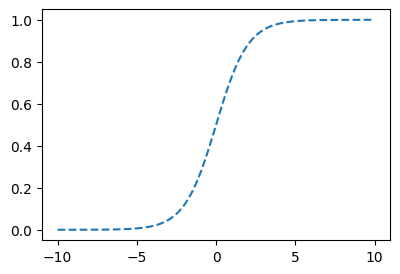
- x대신에 다른걸 넣으면?
plt.plot(x,f(x),'--')
plt.plot(x,f(x+5),'--')
plt.plot(x,f(-x),'--')
plt.plot(x,f(5*x),'--')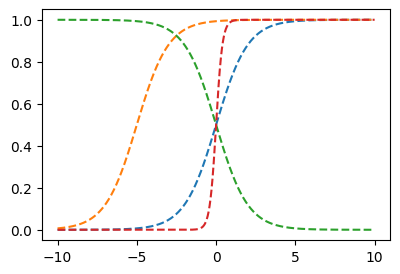
4. 로지스틱
A. 스펙과 취업률
- 박혜원씨는 스펙과 취업이 어떠한 관계를 가지는지 알기 위해서 아래와 같은 자료를 수집하였다.
!wget https://raw.githubusercontent.com/guebin/DL2026/master/posts/05wk-employed.pt
!wget https://raw.githubusercontent.com/guebin/DL2026/master/posts/05wk-spec.pt--2026-04-12 10:07:22-- https://raw.githubusercontent.com/guebin/DL2026/master/posts/05wk-employed.pt
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.111.133, 185.199.109.133, 185.199.108.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.111.133|:443... failed: Connection timed out.
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.109.133|:443... failed: Connection timed out.
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 9619 (9.4K) [application/octet-stream]
Saving to: ‘05wk-employed.pt’
05wk-employed.pt 100%[===================>] 9.39K --.-KB/s in 0s
2026-04-12 10:11:43 (45.4 MB/s) - ‘05wk-employed.pt’ saved [9619/9619]
--2026-04-12 10:11:43-- https://raw.githubusercontent.com/guebin/DL2026/master/posts/05wk-spec.pt
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.111.133, 185.199.109.133, 185.199.108.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.111.133|:443... failed: Connection timed out.
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.109.133|:443... failed: Connection timed out.
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 9591 (9.4K) [application/octet-stream]
Saving to: ‘05wk-spec.pt’
05wk-spec.pt 100%[===================>] 9.37K --.-KB/s in 0s
2026-04-12 10:16:05 (51.2 MB/s) - ‘05wk-spec.pt’ saved [9591/9591]
spec = torch.load("05wk-spec.pt")
employed = torch.load("05wk-employed.pt")plt.plot(spec,employed,'o',alpha=0.05)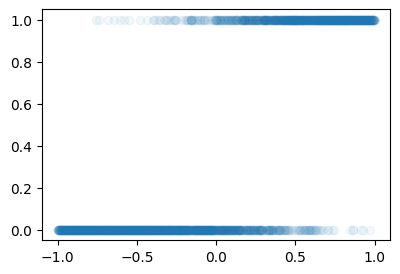
B. A의 자료를 만든 방법 (박혜원씨는 이걸 모름)
- 아래의 수식에서 \(x_i=\text{spec}_i\), \(y_i=\text{employed}_i\) 라고 생각하고 만들었음.
\[y_i \sim Bernoulli(\pi_i^\ast),\quad \pi_i^\ast = \frac{\exp(w_0^\ast + w_1^\ast x_i)}{1+\exp(w_0^\ast + w_1^\ast x_i)}\]
torch.manual_seed(43052)
x = torch.linspace(-1,1,2000)
w0ast = -1
w1ast = 5
def sig(x):
return torch.exp(x)/(torch.exp(x)+1)
piast = sig(w0ast+w1ast*x)
y = torch.bernoulli(piast)plt.plot(x,y,'o',alpha=0.05)
#plt.plot(x,piast,'--r')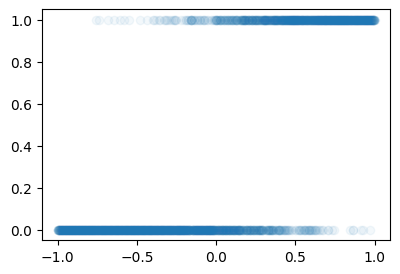
C. 다시 박혜원씨의 세상으로
- 데이터를 다시 관찰하자.
plt.plot(spec,employed,'o',alpha=0.05)
- 박혜원씨의 의심: 이 세상도 혹시 시뮬레이션 아니야??
- 가능한 방식1
_employed = (1.2*spec + torch.randn(2000)*0.3 > 0).float()
plt.plot(spec,_employed,'o',alpha=0.05)
- 가능한 방식2
u = spec*8
v = sig(u)
_employed = torch.bernoulli(v)
plt.plot(spec,_employed,'o',alpha=0.05)
- 방식2를 채택하기로 하자. (왜??)
- 사실 방식1도 충분히 그럴듯해 보이지만..
- 많은 학자들이 방식2가 더 유리하다고 결론 내림!!
- 박혜원씨의 생각: (spec, employed) 자료의 경우 아래와 같은 방식으로 얻어진 시뮬레이션 자료인 것 같다.
\[\pi_i^\ast = \frac{\exp(w_0^\ast + w_1^\ast x_i)}{1+\exp(w_0^\ast + w_1^\ast x_i)}=\text{sig}(\text{linr}(x_i))\]
\[y_i \sim Bernoulli(\pi_i^\ast)\]
이러한 방식이면 이전에 우리가 배웠던 회귀모형은 아래와 같이 쓸 수 있음. \[\mu_i = w_0^\ast + w_1^\ast x_i = \text{linr}(x_i)\] \[y_i \sim N(\mu_i, ??)\]
- 앞으로 이 세상은 시뮬레이션이라고 가정하자.
- 본질적으로 스펙,취업의 관계는 S-shaped 곡선이 되어야한다.
- 그런데 왜 실제 데이터는 S-shaped 곡선이 아니냐? 누군가가 S-shape곡선을 보고 장난쳐서 동전던지기 게임을 해 합격 불합격을 결정했기 때문임.
- 우리는 장난질에 현혹되지 말고 본질을 꿰뚫어야 함. 즉 0,1에 현혹되지 말고 0,1을 만들어내는 근본적인 구조인 S-shaped의 곡선을 그럴듯하게 추정해야함.
- 박혜원씨의 전략: 아무곡선이나 그려본다. \(\to\) 점점 더 적당한 곡선으로 update
X1 = x.reshape(-1,1)
Y = y.reshape(-1,1)
linr = torch.nn.Linear(in_features=1,out_features=1)
# linr.weight.data = torch.tensor([[5.0]])
# linr.bias.data = torch.tensor([-1.5])
sig(linr(X1))
plt.plot(X1,Y,'o',alpha=0.05)
plt.plot(X1,sig(linr(X1)).data,'--')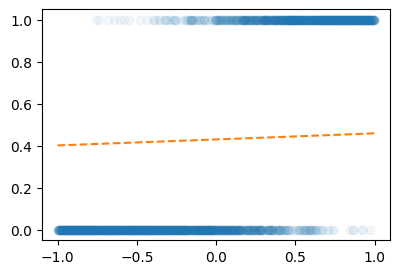
- 적합
X1 = x.reshape(-1,1)
Y = y.reshape(-1,1)
linr = torch.nn.Linear(in_features=1,out_features=1)
linr.weight.data = torch.tensor([[-0.3]])
linr.bias.data = torch.tensor([-0.8])
sig(linr(X1))
plt.plot(X1,Y,'o',alpha=0.05)
plt.plot(X1,sig(linr(X1)).data,'--')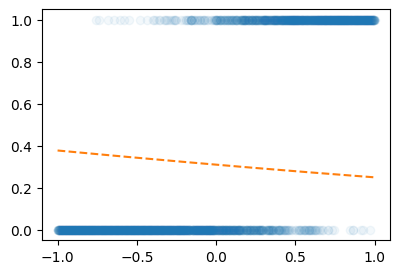
for epoch in range(100):
prob = sig(linr(X1))
loss = torch.mean((prob-Y)**2)
loss.backward()
linr.weight.data = linr.weight.data - 0.25* linr.weight.grad
linr.bias.data = linr.bias.data - 0.25* linr.bias.grad
linr.weight.grad = None
linr.bias.grad = Noneplt.plot(X1,Y,'o',alpha=0.05)
plt.plot(X1,sig(linr(X1)).data,'--')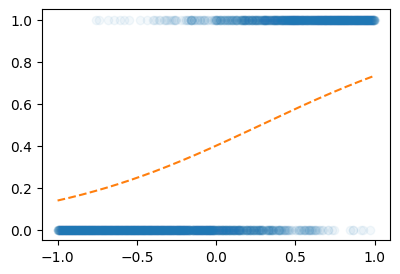
for epoch in range(4900):
prob = sig(linr(X1))
loss = torch.mean((prob-Y)**2)
loss.backward()
linr.weight.data = linr.weight.data - 0.25* linr.weight.grad
linr.bias.data = linr.bias.data - 0.25* linr.bias.grad
linr.weight.grad = None
linr.bias.grad = Noneplt.plot(X1,Y,'o',alpha=0.05)
plt.plot(X1,sig(linr(X1)).data,'--')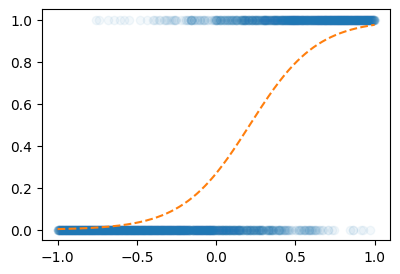
- 성공했나??
linr.weight, linr.bias(Parameter containing:
tensor([[4.7087]], requires_grad=True),
Parameter containing:
tensor([-1.0030], requires_grad=True))w0ast,w1ast(-1, 5)5. 동일한코드
A. 원래코드
X1 = x.reshape(-1,1)
Y = y.reshape(-1,1)
linr = torch.nn.Linear(in_features=1,out_features=1)
linr.weight.data = torch.tensor([[-0.3]])
linr.bias.data = torch.tensor([-0.8])
def sig(x):
return torch.exp(x)/(torch.exp(x)+1)
for epoch in range(5000):
prob = sig(linr(X1))
loss = torch.mean((prob-Y)**2)
loss.backward()
linr.weight.data = linr.weight.data - 0.25* linr.weight.grad
linr.bias.data = linr.bias.data - 0.25* linr.bias.grad
linr.weight.grad = None
linr.bias.grad = Nonelinr.weight, linr.bias(Parameter containing:
tensor([[4.7087]], requires_grad=True),
Parameter containing:
tensor([-1.0030], requires_grad=True))노테이션 변경: X1을 그냥 X로 생각하자. (실제로는 linr에서 bias=False옵션을 쓰는 경우가 거의 없으므로 회귀분석처럼 1만 포함된 열벡터가 첫번째로 있는 X는 딥러닝에서는 거의 사용하지 않음)
X = x.reshape(-1,1)
Y = y.reshape(-1,1)
linr = torch.nn.Linear(in_features=1,out_features=1)
linr.weight.data = torch.tensor([[-0.3]])
linr.bias.data = torch.tensor([-0.8])
def sig(x):
return torch.exp(x)/(torch.exp(x)+1)
for epoch in range(5000):
prob = sig(linr(X))
loss = torch.mean((prob-Y)**2)
loss.backward()
linr.weight.data = linr.weight.data - 0.25* linr.weight.grad
linr.bias.data = linr.bias.data - 0.25* linr.bias.grad
linr.weight.grad = None
linr.bias.grad = Nonelinr.weight, linr.bias(Parameter containing:
tensor([[4.7087]], requires_grad=True),
Parameter containing:
tensor([-1.0030], requires_grad=True))B. sig
X = x.reshape(-1,1)
Y = y.reshape(-1,1)
linr = torch.nn.Linear(in_features=1,out_features=1)
linr.weight.data = torch.tensor([[-0.3]])
linr.bias.data = torch.tensor([-0.8])
# def sig(x):
# return torch.exp(x)/(torch.exp(x)+1)
sig = torch.nn.Sigmoid()
for epoch in range(5000):
prob = sig(linr(X))
loss = torch.mean((prob-Y)**2)
loss.backward()
linr.weight.data = linr.weight.data - 0.25* linr.weight.grad
linr.bias.data = linr.bias.data - 0.25* linr.bias.grad
linr.weight.grad = None
linr.bias.grad = Nonelinr.weight, linr.bias(Parameter containing:
tensor([[4.7087]], requires_grad=True),
Parameter containing:
tensor([-1.0030], requires_grad=True))C. Yhat, loss_fn, optimizer
X = x.reshape(-1,1)
Y = y.reshape(-1,1)
linr = torch.nn.Linear(in_features=1,out_features=1)
linr.weight.data = torch.tensor([[-0.3]])
linr.bias.data = torch.tensor([-0.8])
sig = torch.nn.Sigmoid()
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(linr.parameters(),lr=0.25)
for epoch in range(5000):
Yhat = sig(linr(X))
loss = loss_fn(Yhat,Y)
loss.backward()
optimizer.step()
optimizer.zero_grad()linr.weight, linr.bias(Parameter containing:
tensor([[4.7087]], requires_grad=True),
Parameter containing:
tensor([-1.0030], requires_grad=True))D. net
- 궁극적으로 코드를 아래와 같이 바꾸고 싶다.
for epoch in range(5000):
Yhat = net(X) # 이런식으로 바꾸는게 목표
loss = loss_fn(Yhat,Y)
loss.backward()
optimizer.step()
optimizer.zero_grad()- 관찰: 지금은 아래와 같은 구조이다.
\[\text{sig}(\text{linr}(x_i))=\hat{\pi}_i=\hat{y}_i\]
- 소망: 함수 \(\text{linr}\),\(\text{sig}\)의 합성을 하나로 묶어서
\[(\text{sig}\circ \text{linr})(x_i)=net(x_i)=\hat{y}_i\]
이러한 기능을 하는 하나의 함수 \(net\)을 만들 수 없을까?
linr = torch.nn.Linear(1,1)
linr.weight.data = torch.tensor([[-0.3]])
linr.bias.data = torch.tensor([-0.8])
sig = torch.nn.Sigmoid()net = torch.nn.Sequential(linr,sig) # linr를 취하고 그다음 sig를 취하는 함수 net을 선언net(X), sig(linr(X))(tensor([[0.3775],
[0.3775],
[0.3774],
...,
[0.2499],
[0.2498],
[0.2497]], grad_fn=<SigmoidBackward0>),
tensor([[0.3775],
[0.3775],
[0.3774],
...,
[0.2499],
[0.2498],
[0.2497]], grad_fn=<SigmoidBackward0>))# net 구조 잠깐 살펴보기
netSequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): Sigmoid()
)net[0]Linear(in_features=1, out_features=1, bias=True)net[1]Sigmoid()net[0] is linrTruenet[1] is sigTruenet(X), sig(linr(X)), net[1](net[0](X))(tensor([[0.3775],
[0.3775],
[0.3774],
...,
[0.2499],
[0.2498],
[0.2497]], grad_fn=<SigmoidBackward0>),
tensor([[0.3775],
[0.3775],
[0.3774],
...,
[0.2499],
[0.2498],
[0.2497]], grad_fn=<SigmoidBackward0>),
tensor([[0.3775],
[0.3775],
[0.3774],
...,
[0.2499],
[0.2498],
[0.2497]], grad_fn=<SigmoidBackward0>))#
- 아래의 두 코드는 같은 효과를 가진다.
linr = torch.nn.Linear(1,1)
sig = torch.nn.Sigmoid()
net = torch.nn.Sequential(linr,sig)
linr.weight.data = torch.tensor([[-0.3]])
linr.bias.data = torch.tensor([-0.8])net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].weight.data = torch.tensor([[-0.3]])
net[0].bias.data = torch.tensor([-0.8])- 결국 위에서 살펴본 A,B,C코드는 아래와 같다.
X = x.reshape(-1,1)
Y = y.reshape(-1,1)
net = torch.nn.Sequential(
torch.nn.Linear(in_features=1,out_features=1),
torch.nn.Sigmoid()
)
net[0].weight.data = torch.tensor([[-0.3]])
net[0].bias.data = torch.tensor([-0.8])
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
for epoch in range(5000):
Yhat = net(X)
loss = loss_fn(Yhat,Y)
loss.backward()
optimizer.step()
optimizer.zero_grad()net[0].weight, net[0].bias(Parameter containing:
tensor([[4.7087]], requires_grad=True),
Parameter containing:
tensor([-1.0030], requires_grad=True))- 파이토치에서 코드를 짜는 패턴은 대체로 아래와 비슷함.
for epoch in range(5000):
## step1: Yhat을 구하는 과정
Yhat = net(X)
## step2: loss을 구하는 과정
loss = loss_fn(Yhat,Y)
## step3: 미분(역전파)
loss.backward()
## step4: 업데이트
optimizer.step()
optimizer.zero_grad()6. 학습과정 시각화 및 문제인식
A. 손실함수의 모양
Code
def plot_surface_3d(f, z_min=-500, z_max=500, x_range=None, y_range=None, n_points=800):
# 최솟값/최대값 존재 여부 판단
has_min, has_max = False, False
# 최소 탐색
p_min = torch.zeros(2, requires_grad=True)
opt_min = torch.optim.Adam([p_min], lr=0.1)
for _ in range(1000):
opt_min.zero_grad()
f(p_min[0], p_min[1]).backward()
opt_min.step()
# 수렴했으면 최솟값 존재 (발산 = 큰 좌표)
if abs(p_min[0].item()) < 1e4 and abs(p_min[1].item()) < 1e4:
has_min = True
# 최대 탐색
p_max = torch.zeros(2, requires_grad=True)
opt_max = torch.optim.Adam([p_max], lr=0.1)
for _ in range(1000):
opt_max.zero_grad()
(-f(p_max[0], p_max[1])).backward()
opt_max.step()
if abs(p_max[0].item()) < 1e4 and abs(p_max[1].item()) < 1e4:
has_max = True
if has_min or has_max:
# 최소 또는 최대가 있으면 → 기존 적응적 탐색
if has_min:
cx, cy = p_min[0].item(), p_min[1].item()
else:
cx, cy = p_max[0].item(), p_max[1].item()
n_search = 100
half = 1.0
max_half = 50.0
for _ in range(20):
if half > max_half:
break
x_s = torch.linspace(cx - half, cx + half, n_search)
y_s = torch.linspace(cy - half, cy + half, n_search)
Xs, Ys = torch.meshgrid(x_s, y_s, indexing='ij')
Zs = torch.zeros(n_search, n_search)
for i in range(n_search):
for j in range(n_search):
Zs[i,j] = f(Xs[i,j], Ys[i,j])
mask = (Zs > z_min) & (Zs < z_max)
if not mask.any():
half *= 2
continue
edge = mask[0,:].any() | mask[-1,:].any() | mask[:,0].any() | mask[:,-1].any()
if not edge:
break
half *= 2
x_in = Xs[mask]
y_in = Ys[mask]
margin_x = (x_in.max() - x_in.min()) * 0.1
margin_y = (y_in.max() - y_in.min()) * 0.1
x_lo, x_hi = x_in.min().item() - margin_x, x_in.max().item() + margin_x
y_lo, y_hi = y_in.min().item() - margin_y, y_in.max().item() + margin_y
# 주기성 감지
def detect_period_1d(f_1d, t):
d = f_1d[1:-1]
minima = ((d < f_1d[:-2]) & (d < f_1d[2:])).nonzero().squeeze()
if minima.dim() == 0 or minima.numel() < 2:
return None
dt = (t[1] - t[0]).item()
diffs = (minima[1:] - minima[:-1]).float() * dt
return diffs.median().item()
n_period = 500
scan_r = 20.0
tx = torch.linspace(cx - scan_r, cx + scan_r, n_period)
ty = torch.linspace(cy - scan_r, cy + scan_r, n_period)
fx_slice = torch.tensor([f(tx[i], torch.tensor(cy)).item() for i in range(n_period)])
fy_slice = torch.tensor([f(torch.tensor(cx), ty[i]).item() for i in range(n_period)])
px = detect_period_1d(fx_slice, tx)
py = detect_period_1d(fy_slice, ty)
if px is not None:
x_lo, x_hi = cx - px * 2, cx + px * 2
if py is not None:
y_lo, y_hi = cy - py * 2, cy + py * 2
else:
# 최소도 최대도 없으면 → 고정 범위
x_lo, x_hi = -10, 10
y_lo, y_hi = -10, 10
# 수동 범위 지정 시 덮어쓰기
if x_range is not None:
x_lo, x_hi = x_range
if y_range is not None:
y_lo, y_hi = y_range
# D 위에서 f 재계산
x_vals = torch.linspace(x_lo, x_hi, n_points)
y_vals = torch.linspace(y_lo, y_hi, n_points)
X, Y = torch.meshgrid(x_vals, y_vals, indexing='ij')
Z = torch.zeros(n_points, n_points)
for i in range(n_points):
for j in range(n_points):
Z[i,j] = f(X[i,j], Y[i,j])
# D 영역의 실제 z 범위로 재설정
z_valid = Z[(Z >= z_min) & (Z <= z_max)]
if z_valid.numel() > 0:
z_min = z_valid.min().item()
z_max = z_valid.max().item()
# D 밖은 NaN → 안 그림
Z_plot = Z.clone().float()
Z_plot[(Z < z_min) | (Z > z_max)] = float('nan')
z_margin = (z_max - z_min) * 0.05
Xn, Yn, Zn = X.numpy(), Y.numpy(), Z_plot.numpy()
fig = go.Figure(data=[go.Surface(
x=Xn, y=Yn, z=Zn,
colorscale='Viridis', opacity=0.9, showscale=False,
contours={'z': {'show': True, 'usecolormap': True,
'project': {'z': True}}}
)])
fig.update_layout(
scene=dict(
xaxis=dict(title='x', backgroundcolor='rgba(230,230,230,1)',
gridcolor='rgba(80,80,80,0.2)', showbackground=True),
yaxis=dict(title='y', backgroundcolor='rgba(230,230,230,1)',
gridcolor='rgba(80,80,80,0.2)', showbackground=True),
zaxis=dict(title='z', backgroundcolor='rgba(230,230,230,1)',
gridcolor='rgba(80,80,80,0.2)', showbackground=True,
range=[z_min - z_margin, z_max + z_margin]),
camera=dict(eye=dict(x=1.5, y=1.5, z=0.8)),
),
width=750, height=750,
margin=dict(l=0, r=0, t=0, b=0),
paper_bgcolor='rgba(0,0,0,0)',
)
fig.show()def mse_loss(w0,w1):
X = x.reshape(-1,1)
Y = y.reshape(-1,1)
Yhat = torch.exp(w0+w1*X)/(torch.exp(w0+w1*X)+1)
return torch.mean((Y-Yhat)**2)# plot_surface_3d(mse_loss,x_range=(w0ast-5,w0ast+5),y_range=(w1ast-5,w1ast+5),n_points=80)
# convex(아래로볼록)는 아니네?B. 애니메이션 시각화를 위한 준비
Code
def _plot_loss(loss_fn, ax=None):
w0,w1 =torch.meshgrid(torch.arange(-10,3,0.1),torch.arange(-1,10,0.1),indexing='ij')
w0 = w0.reshape(-1)
w1 = w1.reshape(-1)
def l(w0,w1):
yhat = torch.exp(w0+w1*x)/(1+torch.exp(w0+w1*x))
return loss_fn(yhat,y)
loss = list(map(l,w0,w1))
#---#
if ax is None:
fig = plt.figure()
ax = fig.add_subplot(1,1,1,projection='3d')
ax.scatter(w0,w1,loss,s=0.001)
ax.scatter(w0[::20],w1[::20],loss[::20],s=0.1,color='C0')
ax.scatter(-1,5,l(w0ast,w1ast),s=200,marker='*',color='red',label=r"$w_0^\ast=-1,w_1^\ast=5$")
#---#
ax.elev = 15
ax.dist = -20
ax.azim = 75
ax.legend()
ax.set_xlabel(r'$w_0$') # x축 레이블 설정
ax.set_ylabel(r'$w_1$') # y축 레이블 설정
ax.set_xticks([-10,-5,0]) # x축 틱 간격 설정
ax.set_yticks([-10,0,10]) # y축 틱 간격 설정
def _learn_and_record(net, loss_fn, optimizr):
Yhat_history = []
loss_history = []
What_history = []
Whatgrad_history = []
What_history.append([net[0].bias.data.item(), net[0].weight.data.item()])
for epoc in range(100):
## step1
Yhat = net(X)
## step2
loss = loss_fn(Yhat,Y)
## step3
loss.backward()
## step4
optimizr.step()
## record
if epoc % 5 ==0:
Yhat_history.append(Yhat.reshape(-1).detach().numpy().tolist())
loss_history.append(loss.item())
What_history.append([net[0].bias.data.item(), net[0].weight.data.item()])
Whatgrad_history.append([net[0].bias.grad.item(), net[0].weight.grad.item()])
optimizr.zero_grad()
return Yhat_history, loss_history, What_history, Whatgrad_history
def show_animation(net, loss_fn, optimizr):
Yhat_history,loss_history,What_history,Whatgrad_history = _learn_and_record(net,loss_fn,optimizr)
fig = plt.figure(figsize=(7.5,3.5))
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2, projection='3d')
## ax1: 왼쪽그림
ax1.scatter(X.detach().numpy(),Y.detach().numpy(),alpha=0.01)
ax1.scatter(X[0].detach().numpy(),Y[0].detach().numpy(),color='C0')
ax1.plot(X.detach().numpy(),piast.detach().numpy(),'--')
line, = ax1.plot(X.detach().numpy(),Yhat_history[0],'--')
## ax2: 오른쪽그림
_plot_loss(loss_fn,ax2)
ax2.scatter(np.array(What_history)[0,0],np.array(What_history)[0,1],loss_history[0],color='blue',s=200,marker='*')
def animate(epoc):
line.set_ydata(Yhat_history[epoc])
w0hat = np.array(What_history)[epoc,0]
w1hat = np.array(What_history)[epoc,1]
w0hatgrad = np.array(Whatgrad_history)[epoc,0]
w1hatgrad = np.array(Whatgrad_history)[epoc,1]
ax2.scatter(w0hat,w1hat,loss_history[epoc],color='grey')
ax2.set_title(f"What.grad=[{w0hatgrad:.4f},{w1hatgrad:.4f}]",y=0.8)
fig.suptitle(f"epoch={epoc*5} // What=[{w0hat:.2f},{w1hat:.2f}] // Loss={loss_fn.__class__.__name__} // Opt={optimizr.__class__.__name__}")
return line
ani = animation.FuncAnimation(fig, animate, frames=20)
plt.close()
return anifrom matplotlib import animation
plt.rcParams["animation.html"] = "jshtml"- 함수사용법
torch.manual_seed(42)
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
show_animation(net,loss_fn,optimizer)C. 좋은 초기값
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-0.8])
net[0].weight.data = torch.tensor([[-0.3]])
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
show_animation(net,loss_fn,optimizer)D. 조금 안좋지만 가능성 있는 초기값
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-3.0])
net[0].weight.data = torch.tensor([[-1.0]])
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
show_animation(net,loss_fn,optimizer)E. 최악의 초기값
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-10.0])
net[0].weight.data = torch.tensor([[-1.0]])
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
show_animation(net,loss_fn,optimizer)- 해결하는 접근법:
- 컴공스타일: 에폭을 늘려보자. (그런데 한번 반복하는데 걸리는 계산비용이 너무 많다면?? 계산을 빨리할수있는 방법을 연구하면 되지~)
- 산공스타일: 경사하강법자체를 개선해보자. 옵티마이저를 개선해보자.
- 통계스타일: MSEloss를 바꿔볼까??
7. 손실함수의 개선
A. BCELoss를 사용하여 학습
- BCELoss라는게 있음.
- \(loss = -\frac{1}{n}\sum_{i=1}^{n}\big(y_i\log(\hat{y}_i) + (1-y_i)\log(1-\hat{y}_i)\big)\)
- https://en.wikipedia.org/wiki/Cross-entropy
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-10.0])
net[0].weight.data = torch.tensor([[-1.0]])
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
#---#
for epoch in range(100):
## step1
Yhat = net(X)
## step2
#loss = torch.mean((Yhat-Y)**2)
loss = -torch.mean(Y*torch.log(Yhat)+(1-Y)*torch.log(1-Yhat))
## step3
loss.backward()
## step4
optimizer.step()
optimizer.zero_grad()plt.plot(X,Y,'o',alpha=0.05)
plt.plot(X,net(X).data,'--')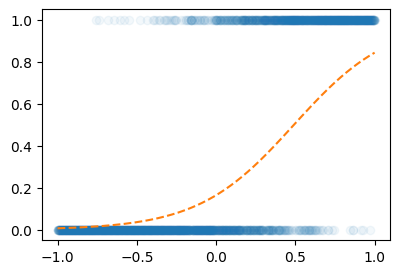
같은 100 epoch인데 훨씬 잘 맞추네??
- loss수식을 외우는게 쉬운일은 아니네?? –> 걱정X, torch에서 지원하는 함수가 있음.
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-10.0])
net[0].weight.data = torch.tensor([[-1.0]])
loss_fn = torch.nn.BCELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
#---#
for epoch in range(100):
## step1
Yhat = net(X)
## step2
loss = loss_fn(Yhat,Y)
## step3
loss.backward()
## step4
optimizer.step()
optimizer.zero_grad()plt.plot(X,Y,'o',alpha=0.05)
plt.plot(X,net(X).data,'--')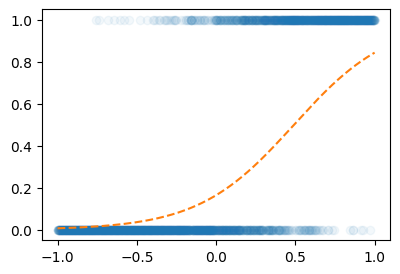
B. Loss Function 시각화
- 손실함수시각화
def bce_loss(w0,w1):
X = x.reshape(-1,1)
Y = y.reshape(-1,1)
Yhat = torch.exp(w0+w1*X)/(torch.exp(w0+w1*X)+1)
return -torch.mean(Y*torch.log(Yhat)+(1-Y)*torch.log(1-Yhat))# plot_surface_3d(bce_loss, x_range=(w0ast-5,w0ast+5), y_range=(w1ast-5,w1ast+5), n_points=80)- 비교해보자.
# plot_surface_3d(mse_loss, x_range=(w0ast-5,w0ast+5), y_range=(w1ast-5,w1ast+5), n_points=80)C. 좋은 초기값
- MSELoss
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-0.8])
net[0].weight.data = torch.tensor([[-0.3]])
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
#---#
show_animation(net,loss_fn,optimizer)- BCELoss
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-0.8])
net[0].weight.data = torch.tensor([[-0.3]])
loss_fn = torch.nn.BCELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
#---#
show_animation(net,loss_fn,optimizer)D. 조금 안좋지만 가능성 있는 초기값
- MSELoss
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-3.0])
net[0].weight.data = torch.tensor([[-1.0]])
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
#---#
show_animation(net,loss_fn,optimizer)- BCELoss
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-3.0])
net[0].weight.data = torch.tensor([[-1.0]])
loss_fn = torch.nn.BCELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
#---#
show_animation(net,loss_fn,optimizer)E. 최악의 초기값
- MSELoss
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-10.0])
net[0].weight.data = torch.tensor([[-1.0]])
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
#---#
show_animation(net,loss_fn,optimizer)- BCELoss
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-10.0])
net[0].weight.data = torch.tensor([[-1.0]])
loss_fn = torch.nn.BCELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
#---#
show_animation(net,loss_fn,optimizer)8. 옵티마이저의 개선
A. 좋은 초기값
- MSELoss + SGD
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-0.8])
net[0].weight.data = torch.tensor([[-0.3]])
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
#---#
show_animation(net,loss_fn,optimizer)- MSELoss + Adam
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-0.8])
net[0].weight.data = torch.tensor([[-0.3]])
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters(),lr=0.25)
#---#
show_animation(net,loss_fn,optimizer)B. 조금 안 좋지만 가능성 있는 초기값
- MSELoss + SGD
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-3.0])
net[0].weight.data = torch.tensor([[-1.0]])
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
#---#
show_animation(net,loss_fn,optimizer)- MSELoss + Adam
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-3.0])
net[0].weight.data = torch.tensor([[-1.0]])
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters(),lr=0.25)
#---#
show_animation(net,loss_fn,optimizer)C. 최악의 초기값
- MSELoss + SGD
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-10.0])
net[0].weight.data = torch.tensor([[-1.0]])
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.25)
#---#
show_animation(net,loss_fn,optimizer)- MSELoss + Adam
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-10.0])
net[0].weight.data = torch.tensor([[-1.0]])
loss_fn = torch.nn.MSELoss()
optimizr = torch.optim.Adam(net.parameters(),lr=0.25)
#---#
show_animation(net,loss_fn,optimizr)D. 참고자료
https://www.youtube.com/watch?v=MD2fYip6QsQ
- 11:50 – Momentum
- 12:30 – RMSprop
- 15:55 – Adam
9. Summary
- 회귀분석과 로지스틱
| 구분 | 회귀 | 로지스틱 |
|---|---|---|
| 모수 (\(\leftarrow\) 신) | \(w_0^\ast, w_1^\ast\) | \(w_0^\ast, w_1^\ast\) |
| 추정값 \((\leftarrow\) 데이터) | \(\hat{w}_0, \hat{w}_1\) | \(\hat{w}_0, \hat{w}_1\) |
| \(x_i \to \hat{y}_i\) | \(\hat{y}_i=\text{linr}(x_i)\) | \(\hat{y}_i=\text{sig}(\text{linr}(x_i))\) |
| \(\hat{y}_i\)의 범위 | \((-\infty,\infty)\) | \((0,1)\) |
| \(y_i\)의 범위 | \((-\infty,\infty)\) | \(\{0,1\}\) |
| \(x_i\)의 범위 | \((-\infty,\infty)\) | \((-\infty,\infty)\) |
| \(y_i \sim ??\) | \(N(w_0^\ast+w_1^\ast x_i, \sigma^2)\) | \(Ber(\frac{\exp(w_0^\ast +w_1^\ast x_i)}{1+\exp(w_0^\ast +w_1^\ast x_i)})\) |
| 본질 | 직선 | 곡선 |
| 장난질의 수법 | 직선값에 노이즈를 더함 | 곡선값을 확률로 해석하고 동전던지기 |
| 손실함수 | MSE | BCE |
| 손실함수의 성질 | convex | convex |
| 추정값을 구하는 방법 | 손으로,컴퓨터로 반복계산 | 컴퓨터로 반복계산 |
- 통계학자는 “이 세상이 혹시 시뮬레이션 아니야?” 라고 의심하며 구체적으로 아래와 같은 것을 상상한다.
- 본질: 정보, structure
- 장난질: 잡음, error
이러한 과정을 통계학에서는 모델링이라고 한다.
참고: 통계학은 항상 데이터를 정보와 잡음이 함께 섞여있는 형태로 본다. 따라서 통계학에서의 모델링은 오차항에 대한 모델링을 포함한다. 머신러닝/딥러닝에서의 모델링은 오차항에 대한 모델링을 생략하는 경우도 많다.
- 통계학자는 진짜 세상이 시뮬레이션이라 믿는걸까?
- 사실 통계학자는 일론머스크처럼 정말로 이 세상이 시뮬레이션이라 믿는건 아니다.
- 그런데 그렇게 생각하면 현실을 해석하기에 편리해서 사용하는 것일 뿐.
- 실제 세상이 어떻게 돌아가는지는 알 필요 X
- 로지스틱에서 방법2가 더 좋은 이유는 무엇인가?
- 시그모이드+BCEloss 조합으로 가야 학습하기 좋음.
- 의미도 있음. 오즈.. \(\log\frac{\pi^\ast}{1-\pi^\ast} = w_0^\ast + w_1^\ast x_i\)
- 회귀분석에서 왜 y만 랜덤이라고 배우고 X는 랜덤이라고 배우지 않을까?
- 의미를 가지고 구분하면 안된다.
- X는 랜덤이든 아니든 관심없음. 중요한건 X가 이미 주어진 상황이라는 점. (신이 장난질을 하여 X를 만든것은 박혜원씨는 아무 타격이 없음. 박혜원씨가 분노하는건 X에 장난질하여 y를 만들었다는 것임)