import torch
import numpy as np
import matplotlib.pyplot as plt
#--# 문제1
import pandas as pd
import sklearn.model_selection
#--# 문제4
import gymnasium as gym
import IPython
from matplotlib.animation import FuncAnimation
import collections
import random15wk-2: 기말고사
![]()
1~5번은 모든 부분문항을 고려하여 0점 혹은 10점으로 채점함. 6번은 개별문항당 5점으로 채점함
1. ml-20m – 10점
!wget http://files.grouplens.org/datasets/movielens/ml-20m.zip
!unzip ml-20m.zipMovieLens 20M 데이터셋은 GroupLens Research에서 제공하는 영화 평점 데이터셋으로, 영화 추천 시스템 연구에 널리 사용된다. 이 데이터셋은 약 2천만 개의 영화 평점과 메타데이터를 포함하고 있다. 주요 파일과 그 내용은 다음과 같다:
1. ratings.csv:
- userId: 사용자의 고유 ID
- movieId: 영화의 고유 ID
- rating: 사용자가 부여한 평점 (0.0에서 1.0 사이의 값)
- timestamp: 평점이 부여된 시간 (유닉스 타임스탬프 형식)
2. movies.csv:
- movieId: 영화의 고유 ID
- title: 영화 제목
- genres: 영화 장르 (여러 개의 장르가 ’|’로 구분됨)
3. tags.csv:
- userId: 사용자의 고유 ID
- movieId: 영화의 고유 ID
- tag: 사용자가 부여한 태그
- timestamp: 태그가 부여된 시간 (유닉스 타임스탬프 형식)
4. genome-scores.csv:
- movieId: 영화의 고유 ID
- tagId: 태그의 고유 ID
- relevance: 해당 태그가 영화에 얼마나 관련 있는지 나타내는 점수 (0.0에서 1.0 사이의 값)
5. genome-tags.csv:
- tagId: 태그의 고유 ID
- tag: 태그의 이름
6. links.csv:
- movieId: 영화의 고유 ID
- imdbId: IMDB에서의 영화 ID
- tmdbId: TMDB에서의 영화 ID
이중에서 1,2의 데이터만 사용하여 추천시스템을 설계하기로 하자.
np.random.seed(43052)
df_ratings = pd.read_csv("ml-20m/ratings.csv")
df_movies = pd.read_csv("ml-20m/movies.csv")
df_train_all = pd.merge(df_ratings,df_movies)
userId_sampled = np.random.choice(df_train_all.userId.unique(),5000,replace=False); userId_sampled[0] = 46889
df_train = df_train_all.query("userId in @userId_sampled").reset_index(drop=True)
df_train["userId"] = df_train.userId.map({user:i for i,user in enumerate(set(df_train.userId))})
df_train["movieId"] = df_train.movieId.map({movie:i for i,movie in enumerate(set(df_train.movieId))}) 평점정보와 영화정보를 결합하여 df_train을 만들었으며, 위의 코드를 간단히 설명하면 아래와 같다.
1. df_ratings와 df_movies CSV 파일을 읽어 데이터프레임으로 만든다.
df_ratings = pd.read_csv("ml-20m/ratings.csv")
df_movies = pd.read_csv("ml-20m/movies.csv")2. 평점 데이터와 영화 데이터를 합쳐 하나의 데이터프레임 df_train_all을 만든다.
df_train_all = pd.merge(df_ratings, df_movies)3. 데이터가 너무 많아 5000명의 유저만 랜덤으로 샘플링한다. (이때 유저 46889는 반드시 포함)
userId_sampled = np.random.choice(df_train_all.userId.unique(), 5000, replace=False); userId_sampled[0] = 468894. 샘플링된 5000명의 유저 데이터만 포함하는 새로운 데이터프레임 df_train을 만든다.
df_train = df_train_all.query("userId in @userId_sampled").reset_index(drop=True)5. 유저 ID를 0부터 시작하는 인덱스로 재조정한다.
df_train["userId"] = df_train.userId.map({user: i for i, user in enumerate(set(df_train.userId))})6. 영화 ID도 0부터 시작하는 인덱스로 재조정한다.
df_train["movieId"] = df_train.movieId.map({movie: i for i, movie in enumerate(set(df_train.movieId))})df_train| userId | movieId | rating | timestamp | title | genres | |
|---|---|---|---|---|---|---|
| 0 | 32 | 1 | 3.5 | 1162148886 | Jumanji (1995) | Adventure|Children|Fantasy |
| 1 | 97 | 1 | 1.5 | 1270074943 | Jumanji (1995) | Adventure|Children|Fantasy |
| 2 | 104 | 1 | 4.0 | 832087680 | Jumanji (1995) | Adventure|Children|Fantasy |
| 3 | 143 | 1 | 5.0 | 1169362252 | Jumanji (1995) | Adventure|Children|Fantasy |
| 4 | 154 | 1 | 3.0 | 837155475 | Jumanji (1995) | Adventure|Children|Fantasy |
| ... | ... | ... | ... | ... | ... | ... |
| 721479 | 160 | 10694 | 3.0 | 1301694248 | Sube y Baja (1959) | Comedy |
| 721480 | 160 | 10945 | 2.0 | 1306489841 | Mosquito Net, The (La mosquitera) (2010) | Drama |
| 721481 | 160 | 10999 | 3.0 | 1307711243 | Bicycle, Spoon, Apple (Bicicleta, cullera, poma) | Documentary |
| 721482 | 160 | 11139 | 3.0 | 1310106628 | Welcome Farewell-Gutmann (Bienvenido a Farewel... | Comedy|Drama |
| 721483 | 160 | 11188 | 3.5 | 1311319470 | Concursante (2007) | Comedy|Drama |
721484 rows × 6 columns
(1) df_train을 아래와 같이 X_train, X_val, y_train, y_val로 나누고 NN-based 추천시스템을 설계하고 학습하라. 학습결과를 validation loss로 검증하라.
X1 = torch.tensor(df_train.userId)
X2 = torch.tensor(df_train.movieId)
X = torch.stack([X1,X2],axis=1)
y = torch.tensor(df_train.rating).float().reshape(-1,1)X_train,X_val,y_train,y_val = sklearn.model_selection.train_test_split(X,y,test_size=0.1,random_state=42)힌트: 아래의 코드를 이용하세요..
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
#--#
????
def forward(self,X):
???
return yhat
#---#
net = Net()
loss_fn = torch.nn.MSELoss()
optimizr = torch.optim.Adam(net.parameters())
ds = torch.utils.data.TensorDataset(X_train,y_train)
dl = torch.utils.data.DataLoader(ds,batch_size=8,shuffle=True)
#--#
for epoc in range(5):
net.to("cuda:0")
for xi,yi in dl:
xi = xi.to("cuda:0")
yi = yi.to("cuda:0")
# 1
yi_hat = net(xi)
# 2
loss = loss_fn(yi_hat,yi)
# 3
loss.backward()
# 4
optimizr.step()
optimizr.zero_grad()
net.to("cpu")
print(f"epoch: {epoc+1}\t val_loss: {loss_fn(net(X_val).data,y_val):.4f}")# 학습결과epoch: 1 val_loss: 0.7995
epoch: 2 val_loss: 0.7595
epoch: 3 val_loss: 0.7444
epoch: 4 val_loss: 0.7383
epoch: 5 val_loss: 0.7334# 시각화
plt.plot(y_val,net(X_val).data,'.',alpha=0.002)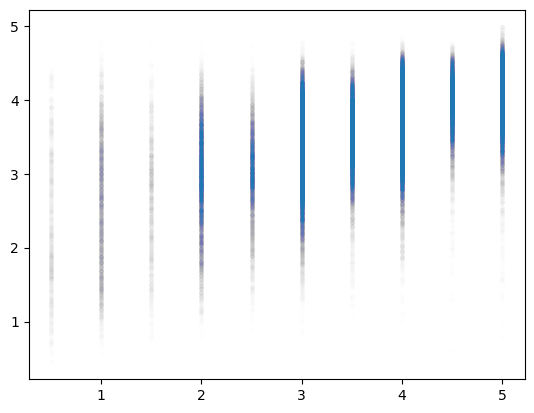
- 전체적으로 우상향 \(\to\) 그럭저럭 잘맞춤
(2) 아래는 유저 2303번에 대한 정보이다.
df_train.query("userId == 2303")| userId | movieId | rating | timestamp | title | genres | |
|---|---|---|---|---|---|---|
| 6142 | 2303 | 111 | 4.0 | 868103611 | Rumble in the Bronx (Hont faan kui) (1995) | Action|Adventure|Comedy|Crime |
| 12399 | 2303 | 295 | 5.0 | 868103784 | Pulp Fiction (1994) | Comedy|Crime|Drama|Thriller |
| 121626 | 2303 | 854 | 5.0 | 868103861 | Godfather, The (1972) | Crime|Drama |
| 166612 | 2303 | 5 | 5.0 | 868103615 | Heat (1995) | Action|Crime|Thriller |
| 177956 | 2303 | 430 | 5.0 | 868103965 | Carlito's Way (1993) | Crime|Drama |
| 182689 | 2303 | 730 | 3.0 | 868103615 | Rock, The (1996) | Action|Adventure|Thriller |
| 200985 | 2303 | 607 | 4.0 | 868103615 | Fargo (1996) | Comedy|Crime|Drama|Thriller |
| 229027 | 2303 | 1383 | 4.0 | 868104228 | Mars Attacks! (1996) | Action|Comedy|Sci-Fi |
| 230673 | 2303 | 1458 | 5.0 | 868103861 | Donnie Brasco (1997) | Crime|Drama |
| 232189 | 2303 | 1561 | 4.0 | 868103699 | Face/Off (1997) | Action|Crime|Drama|Thriller |
| 298169 | 2303 | 1266 | 5.0 | 868103818 | Akira (1988) | Action|Adventure|Animation|Sci-Fi |
| 351345 | 2303 | 94 | 3.0 | 868103425 | Broken Arrow (1996) | Action|Adventure|Thriller |
| 406288 | 2303 | 774 | 5.0 | 868103861 | Trainspotting (1996) | Comedy|Crime|Drama |
| 420897 | 2303 | 1540 | 4.0 | 868104432 | Con Air (1997) | Action|Adventure|Thriller |
| 430816 | 2303 | 1055 | 5.0 | 868103985 | William Shakespeare's Romeo + Juliet (1996) | Drama|Romance |
| 435186 | 2303 | 17 | 4.0 | 868104228 | Four Rooms (1995) | Comedy |
| 439509 | 2303 | 1057 | 4.0 | 868104200 | Sleepers (1996) | Thriller |
| 441292 | 2303 | 1399 | 4.0 | 868103699 | Scream (1996) | Comedy|Horror|Mystery|Thriller |
| 539383 | 2303 | 795 | 4.0 | 868103888 | Frighteners, The (1996) | Comedy|Horror|Thriller |
| 576643 | 2303 | 1421 | 4.0 | 868103699 | First Strike (Police Story 4: First Strike) (G... | Action|Adventure|Comedy|Thriller |
유저 2303는 스릴러를 좋아하는 것 같다. 영화 {49: Usual Suspects, The (1995)} 는 스리럴중에서도 인기가 있는 영화인데, 유저 2303는 아직 이 영화를 시청하지 않은듯 보인다.
df_train.query("'Usual Suspects, The (1995)' in title")| userId | movieId | rating | timestamp | title | genres | |
|---|---|---|---|---|---|---|
| 4281 | 2 | 49 | 3.0 | 840207617 | Usual Suspects, The (1995) | Crime|Mystery|Thriller |
| 4282 | 5 | 49 | 5.0 | 994071051 | Usual Suspects, The (1995) | Crime|Mystery|Thriller |
| 4283 | 7 | 49 | 5.0 | 938947646 | Usual Suspects, The (1995) | Crime|Mystery|Thriller |
| 4284 | 20 | 49 | 5.0 | 1101142801 | Usual Suspects, The (1995) | Crime|Mystery|Thriller |
| 4285 | 32 | 49 | 5.0 | 1162149613 | Usual Suspects, The (1995) | Crime|Mystery|Thriller |
| ... | ... | ... | ... | ... | ... | ... |
| 6007 | 1306 | 49 | 5.0 | 835963893 | Usual Suspects, The (1995) | Crime|Mystery|Thriller |
| 6008 | 1318 | 49 | 5.0 | 840631188 | Usual Suspects, The (1995) | Crime|Mystery|Thriller |
| 6009 | 1320 | 49 | 3.5 | 1352723562 | Usual Suspects, The (1995) | Crime|Mystery|Thriller |
| 6010 | 1321 | 49 | 5.0 | 839429098 | Usual Suspects, The (1995) | Crime|Mystery|Thriller |
| 6011 | 1330 | 49 | 5.0 | 834683823 | Usual Suspects, The (1995) | Crime|Mystery|Thriller |
1731 rows × 6 columns
유저 2303에게 이 영화를 추천하면 어떠한 평점을 줄까? (1)에서 학습한 네트워크로 예측하여 보라.
2. hello – 10점
아래와 같이 hello가 반복되는 자료가 있다고 하자.
txt = list('hello')*100
txt[:10]['h', 'e', 'l', 'l', 'o', 'h', 'e', 'l', 'l', 'o'](1) torch.nn.RNN()을 이용하여 다음문자를 예측하는 신경망을 설계하고 학습하라.
(2) torch.nn.RNNCell()을 이용하여 다음문자를 예측하는 신경망을 설계하고 학습하라.
(3) (2)의 결과와 동일한 적합값을 출력하는 신경망을 직접설계한뒤 학습시켜라. (초기값을 적절하게 설정할 것)
class rNNCell(torch.nn.Module):
def __init__(self):
super().__init__()
self.i2h = ????
self.h2h = ????
self.tanh = ????
def forward(self,??,??):
ht = ????
return ht위의 클래스의 ????를 체워 (2)의 결과와 동일한 적합값이 나오도록 하라.
- class를 이용하지 않으면 점수없음.
torch.nn.RNN(),torch.nn.RNNCell()을 이용한 네트워크를 학습시킬시 점수 없음. (초기값을 셋팅하는 용도로는 torch.nn.RNN(), torch.nn.RNNCell()을 코드에 포함시키는 것이 가능)
3. Human_Numbers – 10점
HUMAN_NUMBERS_train.txt 사람이 읽을 수 있는 형식으로 숫자가 나열된 텍스트 파일이다. 이 텍스트 파일을 이용하여 “현재 단어가 주어졌을 때 다음 단어를 예측하는” 신경망을 설계하고 학습시킬 것이다. 아래는 해당 파일을 불러와 단어 단위로 나눈 결과를 확인하는 코드이다.
!wget https://raw.githubusercontent.com/guebin/DL2025/main/posts/HUMAN_NUMBERS_train.txt
with open('HUMAN_NUMBERS_train.txt') as f:
words = f.read().split()--2025-06-16 22:46:40-- https://raw.githubusercontent.com/guebin/DL2025/main/posts/HUMAN_NUMBERS_train.txt
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.111.133, 185.199.109.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 280599 (274K) [text/plain]
Saving to: ‘HUMAN_NUMBERS_train.txt’
HUMAN_NUMBERS_train 100%[===================>] 274.02K --.-KB/s in 0.01s
2025-06-16 22:46:40 (18.8 MB/s) - ‘HUMAN_NUMBERS_train.txt’ saved [280599/280599]
print(words[-12:])['seven', 'thousand', 'nine', 'hundred', 'ninety', 'eight', 'seven', 'thousand', 'nine', 'hundred', 'ninety', 'nine']이 텍스트 파일에는 예를 들어 “… seven, thousand, nine, hundred, ninety, eight, …” 등과 같은 사람이 읽는 숫자 표현이 단어 단위로 나열된 시퀀스 형태로 저장되어 있다.
이러한 데이터에서 “현재 단어가 주어졌을 때 다음 단어를 예측하는” 자연어 처리 모델을 학습하라. 즉 아래와 같은 맵핑을 학습하라. (꼭 다맞출 필요는 없습니다)
- … seven, thousand, nine, hundred, ninety, eight \(\to\) seven
- … seven, thousand, nine, hundred, ninety, eight, seven \(\to\) thousand
- … seven, thousand, nine, hundred, ninety, eight, seven, thousand \(\to\) nine
제약사항
- one-hot 전처리 코드를 포함할 것
torch.nn.RNN,torch.nn.RNNCell,torch.nn.LSTM중 하나를 이용할 것- 처음 12개의 단어와 마지막 12개의 단어에 대한 적합값(fitted value)을 제시할 것
hint: 아래의 코드를 이용하여 전처리하면 편리하다.
df_train = pd.DataFrame({'x': words[:-1], 'y': words[1:]})
df_train| x | y | |
|---|---|---|
| 0 | one | two |
| 1 | two | three |
| 2 | three | four |
| 3 | four | five |
| 4 | five | six |
| ... | ... | ... |
| 42074 | seven | thousand |
| 42075 | thousand | nine |
| 42076 | nine | hundred |
| 42077 | hundred | ninety |
| 42078 | ninety | nine |
42079 rows × 2 columns
# 전체 vocab 기준으로 맵핑
vocab = sorted(set(words))
dct= {w: i for i, w in enumerate(vocab)}
# train 데이터셋
x = torch.tensor(df_train.x.map(dct))
y = torch.tensor(df_train.y.map(dct))4. FrozenLake – 10점
ref: https://gymnasium.farama.org/environments/toy_text/frozen_lake/
아래는 OpenAI Gym 라이브러리에서 제공하는 환경 Frozen Lake를 구체화하여 변수 env에 저장하는 코드이다.
env = gym.make('FrozenLake-v1', desc=None, map_name="4x4", is_slippery=False, render_mode='rgb_array')Frozen Lake 환경은 강화학습(RL) 실험을 위한 간단한 시뮬레이션 환경으로 에이전트가 얼어붙은 호수 위를 안전하게 건너 목표 지점에 도달하는 것이 목표이다. 주요 특징은 다음과 같다.
1. 환경 구성:
- 격자형(grid) 환경으로 이루어져 있으며, 각 격자는 4x4 또는 8x8의 형태를 가질 수 있다. (문제에서는 4x4)
- 격자는 시작 지점(Start), 목표 지점(Goal), 얼음(Ice), 그리고 구멍(Hole)으로 구성된다.
- 에이전트는 시작 지점에서 목표 지점까지 이동해야 한다.
2. 에이전트의 동작:
- 에이전트는 상, 하, 좌, 우로 이동할 수 있다.
- 얼음 위에서는 자유롭게 이동할 수 있지만, 구멍에 빠지면 에피소드가 종료된다.
3. 보상 체계:
- 에이전트가 목표 지점에 도달하면 +1의 보상을 받는다.
- 그 외에는 보상이 없다(0 보상).
- 구멍에 빠지거나 목표 지점에 도달하지 못하면 보상은 없다.
4. 목표:
- 에이전트는 강화학습 알고리즘을 사용하여 최적의 경로를 학습하고, 가능한 한 구멍에 빠지지 않고 목표 지점에 도달하는 것이다.
아래는 show 함수이며, 이는 env의 현재상태를 렌더링해주는 역할을 한다.
def show(imgs):
fig = plt.Figure()
ax = fig.subplots()
def update(i):
ax.imshow(imgs[i])
ani = FuncAnimation(fig,update,frames=len(imgs))
display(IPython.display.HTML(ani.to_jshtml()))show() 함수의 사용방법은 아래와 같다.
imgs = []
env.reset()
while True:
img = env.render()
imgs.append(img)
#---#
player.act()
player.next_state, player.reward, player.terminated, player.truncated, _ = env.step(player.action)
if player.terminated or player.truncated:
break
else:
player.state = player.next_state
show(imgs) 적당한 위의 환경에 대응하는 Agent를 설계하고 q_net를 이용하여 올바른 행동을 학습하라. (최근 100번의 평균점수가 0.9 이상이면 만점으로 인정)
힌트1: 아래의 에이전트를 설계에 활용하세요
class RandomAgent:
def __init__(self):
#--# define spaces
self.action_space = gym.spaces.Discrete(4)
#--# replay buffer
self.state = None
self.action = None
self.reward = None
self.next_state = None
self.terminated = None
self.truncated = None
#-#
self.states = collections.deque(maxlen=5000)
self.actions = collections.deque(maxlen=5000)
self.rewards = collections.deque(maxlen=5000)
self.next_states = collections.deque(maxlen=5000)
self.terminations = collections.deque(maxlen=5000)
#--# other information
self.n_experiences = 0
self.eps = 1.0
def act(self):
self.action = self.action_space.sample()
def learn(self):
pass
def save_experience(self):
self.states.append(torch.tensor(self.state))
self.actions.append(self.action)
self.rewards.append(self.reward)
self.next_states.append(torch.tensor(self.next_state))
self.terminations.append(self.terminated)
#--#
self.n_experiences = self.n_experiences + 1 힌트2: q_net의 첫 레이어는 torch.nn.Embedding()을 이용하세요
- 상태공간(state space)이 0~15일텐데,
상태1 x 2 = 상태2,상태3 + 상태2 = 상태5와 같은 관계가 성립한다고 보기 어려우므로 상태공간은 범주형변수로 봐야겠죠?
힌트3: 학습이 잘 되지 않는다면 아래를 체크해보세요.
q_net(s)가 올바른 값을 주는지 확인합시다.- 예를들어 q_net(s)의 값은 0~1사이에 있어야 하겠구요,
- 상태14에서는 오른쪽(action=2)으로 가야합니다. (액션값과 상태에 대한 정의값은 공식문서를 참고하세요)
- 네크워크를 엄청 복잡하게 할 필요는 없습니다. (저는 레이어3장썼고요.. 레이어에서 최대 노드수는 32를 넘지 않아요)
- 그외 제가 학습에 사용한 여러 설정을 공유합니다. (아마 꼭 저대로 안해도 될걸요?)
- GPU 사용 X
- 학습시간: 5분쯤?
- 옵티마이저: 아담
- 학습률: 디폴트
- 배치사이즈: 128
- 랜덤액션 확률: 매 에피소드마다 “이전 확률 × 0.995” 방식으로 점차 감소
#에피소드: 100 경험: 818 점수: 0.12 게임시간: 7.18 돌발행동: 0.61
에피소드: 200 경험: 1538 점수: 0.37 게임시간: 6.20 돌발행동: 0.37
에피소드: 300 경험: 2350 점수: 0.72 게임시간: 7.12 돌발행동: 0.22
에피소드: 400 경험: 3013 점수: 0.78 게임시간: 5.63 돌발행동: 0.13
에피소드: 500 경험: 3648 점수: 0.89 게임시간: 5.35 돌발행동: 0.08
--에피소드 542에서 클리어--5. 4x4 GirdWorld – 10점
아래의 제약조건에 맞추어 14wk-2의 Solve를 해결할 것
- Q-테이블 초기화 및 사용 방식: 에이전트는
q_net이 아닌q_table을 사용하여 업데이트하며,q_table은 np.random.randn(4, 4, 4)로 초기화된다. - 액션 선택 전략: 매 스텝마다 일정 확률로 랜덤 액션을 수행하고, 랜덤이 아닐 경우에는 q_table을 참고해 가장 높은 Q값을 갖는 최적의 액션을 선택한다.
- 탐험 확률 감소 (ε-greedy): 랜덤액션을 선택하는 확률은 초기값 100%에서 시작하여, 매 에피소드마다 “이전 확률 × 0.995” 방식으로 점차 감소한다.
- 감가율 (Discount Factor): 미래 보상의 중요도를 반영하기 위한 감가율은 0.95로 설정한다.
- 학습률 (Learning Rate):
q와q_hat의 차이를 얼마나 반영할지를 결정하는 학습률은 0.01로 설정한다. - 경험 메모리 구조: 플레이어(=에이전트)는 최대 5000개의 경험을 저장할 수 있다.
- 학습 조건 및 방식 (learn 함수): 저장된 경험이 64개 이상일 때만 학습이 수행되며, 경험 메모리에서 64개를 무작위로 샘플링하여 q_table을 업데이트한다.
- 종료 조건 (Success Criterion): 최근 10개 에피소드의 평균 score가 90 이상이면 과업을 완료한 것으로 간주하고 학습을 종료한다.
- 플레이타임 계산: 각 에피소드가 끝날 때까지 몇 번의 step이 소요되었는지 기록하며, 이를 기반으로 에피소드별 플레이타임을 저장한다.
- 시각화 출력: 최종학습결과를 13wk-2 주차 강의의
show()함수를 이용하여 시각화한다.
6. 미공개 문제 – 50점
(1) 아래에서 linr(onehot(x).float()) 동일한 효과를 가지는 레이어를 torch.nn.Embedding을 활용하여 설계하라.
x = torch.tensor([0,1,3,2])
onehot = torch.nn.functional.one_hot
linr = torch.nn.Linear(4,6)
linr(onehot(x).float())tensor([[ 0.1480, -0.2304, -0.7442, 0.4778, 0.2485, 0.1443],
[-0.0281, -0.3552, -0.4810, 0.1142, -0.0716, 0.4886],
[ 0.3772, -0.7699, -0.6483, 0.1682, 0.1133, 0.1241],
[ 0.1661, 0.0260, -0.8929, 0.0616, -0.0508, 0.3831]],
grad_fn=<AddmmBackward0>)Note: 아키텍처만 제시하면 만점으로 인정. 출력결과를 동일하게 맞출필요 없음.
(2) 아래는 5개의 클래스를 구분하는 로짓값들이다.
logits = torch.randn(10,5)
logitstensor([[-0.4495, 1.7851, -0.0607, -1.4817, 1.0300],
[ 0.3756, 1.3452, 0.6558, -0.6121, 0.7791],
[-0.2299, 0.3160, 0.6230, -0.2546, 1.2070],
[-1.3148, 0.4172, 1.0608, -1.8717, 0.4098],
[-0.6357, 1.1613, 0.3780, 0.9790, -1.4876],
[ 0.0261, 0.5741, 1.4564, -0.0992, -1.5579],
[-1.9930, 1.5710, 0.6926, 0.6381, -2.3785],
[ 0.0558, -0.0665, 0.4925, 0.9533, 1.0511],
[ 0.5740, -2.4789, 0.9576, 0.6170, -0.3435],
[ 0.0644, -0.4826, -1.1118, 1.4816, 0.2898]])softmax를 이용하여 위의 logits값을 확률로 바꾸는 코드를 구현하라.
(3) 아래와 같은 자료를 가정하자.
x1 = user = torch.tensor([0,0,0,1,1,1,2,2,2,3,3])
x2 = item= torch.tensor([0,1,2,0,1,2,0,1,2,0,1])
y = score = torch.tensor([0.5, 4.0, 3.5, 2.0, 5.0, 4.5, 1.0, 3.0, 4.0, 0.5, 2.5])이 데이터는 사용자(x1)와 아이템(x2)에 대한 평점(y)으로 구성된 자료이다. 위 데이터를 기반으로 MF-based 추천 시스템을 설계하고자한다. ?? 를 채워 빈칸을 완성하라.
ebdd1 = torch.nn.Embedding(??,2)
ebdd2 = torch.nn.Embedding(??,2)
b1 = torch.nn.Embedding(??,1)
b2 = torch.nn.Embedding(??,1)
sig = torch.nn.Sigmoid()
yhat = ???? (4) 아래의 자료를 고려하라.
txt = 'abcdefu'*100
txt[:50]'abcdefuabcdefuabcdefuabcdefuabcdefuabcdefuabcdefua'RNNCell을 이용하여 위의 자료를 분석할 수 있는 에 대응하는 적당한 네트워를 설계하고자 한다.
rnncell = torch.nn.RNNCell(input_size = ??, hidden_size=10)??를 채워 빈칸을 완성하라.
(5) (4)의 출력결과와 동일한 효과를 내는 네트워크를 직접설계하고자 한다. 즉 https://docs.pytorch.org/docs/stable/generated/torch.nn.RNNCell.html 에 제시된 아래의 수식을 직접 구현하고자 한다.
\[h' = \tanh(W_{ih}x + b_{ih} + W_{hh}h + b_{hh})\]
아래의 코드에서 __init__ 에 해당하는 내용을 채우라.
class MyRNNCell(torch.nn.Module):
def __init__():
???
def forward(x,h):
???(6) (5)의 문제에 이어서.. forward 에 해당하는 내용을 채우라.
(7) 4x4 World게임을 풀기위해 아래의 q_table을 만들었다고 가정하자.
torch.manual_seed(43052)
q_table = torch.randn(4,4,4)
q_tabletensor([[[-0.6103, 0.1521, 1.5031, 0.1420],
[ 0.7822, -0.2734, -0.1816, -0.5621],
[ 0.6469, -0.3688, -0.1448, 2.6056],
[ 1.3494, -0.2000, -1.4635, 0.3220]],
[[-1.1092, 0.5443, 0.9804, -0.7421],
[-0.9469, -0.4710, -0.3719, 1.1024],
[-1.9973, 0.6148, -0.5506, -2.3621],
[-0.5830, -1.4509, 0.1568, -1.4435]],
[[-0.4676, -0.8643, 0.7059, 0.6523],
[ 0.1195, 0.7141, -0.7549, 1.5437],
[-0.5058, -0.3874, 2.2444, -0.3159],
[ 1.1532, -1.6239, 2.0832, 0.5579]],
[[ 1.3403, 0.3984, -1.4792, 0.5913],
[ 1.6789, 0.3157, -0.1361, 0.2656],
[ 0.0655, -0.0214, 0.3461, -0.2155],
[ 1.4279, -1.3079, -1.0875, 1.0376]]])q_table[s1,s2,a]는 상태 \((s1,s2)\)에서 행동 \(a\)를 하였을 경우 품질을 의미한다. 현재 플레이가 상태 (1,1)에 있다고 가정하자. 이때 플레이어가 할 수 있는 최선의 행동은 무엇인가? (여기서 최선의 행동이란 해당 상태에서 가장 높은 품질을 갖는 행동을 의미)
답안예시: \(a=0\) 이 최선의 행동이다.
(8) (7)의 상태에서 최선의 행동 \(a\)를 선택한 결과, 플레이어는 다음 상태 (1,2)로 이동하였고 보상으로 -20.0을 받았다고 하자. 미래품질과 즉시보상을 모두 고려한 보상은 얼마인가? (단, 감가율은 0.8로 가정한다)
(9) (8)의 상황에서 q[1,1,a] 의 값을 update하라. 이때 학습률은 0.1로 적용하라.
(10) (9)의 결과로 update된 q_table을 고려하자. 다시 플레이어가 상태 (1,1)에 있다고 가정하자. 이때 플레이어가 할 수 있는 최선의 행동은 무엇인가? (7)에서의 답과 동일한가?