x = torch.tensor([1,2,3,4,5])
xtensor([1, 2, 3, 4, 5])![]()
문제풀이에 필요한 모듈은 스스로
import할 것
# –기본문법$. 벡터와 행렬(1) 아래와 같이 length 5 인 vector를 torch.tensor로 선언하는 코드를 작성하라.
\[{\bf x} = [1,2,3,4,5]\]
(풀이)
x = torch.tensor([1,2,3,4,5])
xtensor([1, 2, 3, 4, 5])(2) 아래와 같은 2x2 matrix 를 torch.tensor로 선언하는 코드를 작성하라.
\[{\bf A} = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix}\]
(3) 아래와 같은 matrix 를 torch.tensor로 선언하는 코드를 작성하라.
\[{\bf W} = \begin{bmatrix} 2.5 \\ 4 \end{bmatrix}\]
(4) 아래와 같은 matrix 를 torch.tensor로 선언하는 코드를 작성하라.
\[{\bf x} = \begin{bmatrix} 2.5 & 4 \end{bmatrix}\]
$. concat, stacka,b가 아래와 같이 주어졌다고 하자.
a = torch.tensor([1]*10)
b = torch.tensor([2]*10)아래를 잘 읽고 물음에 답하라.
(1) 주어진 a,b와 torch.concat를 이용하여 아래와 같은 배열을 만들어라.
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])torch.concat([a.reshape(-1,1), b.reshape(-1,1)])tensor([[1],
[1],
[1],
[1],
[1],
[1],
[1],
[1],
[1],
[1],
[2],
[2],
[2],
[2],
[2],
[2],
[2],
[2],
[2],
[2]])(2) 주어진 a,b 와 torch.concat,.reshape를 이용하여 아래와 같은 배열을 만들어라.
tensor([[1],
[1],
[1],
[1],
[1],
[1],
[1],
[1],
[1],
[1],
[2],
[2],
[2],
[2],
[2],
[2],
[2],
[2],
[2],
[2]])(3) 주어진 a,b 와 torch.concat,.reshape를 이용하여 아래와 같은 배열을 만들어라.
tensor([[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2]])(4) 주어진 a,b와 torch.stack 을 이용하여 아래와 같은 배열을 만들어라.
tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2]](5) 주어진 a,b와 torch.stack을 이용하여 아래와 같은 배열을 만들어라.
tensor([[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2],
[1, 2]])$. 행렬곱(1) 아래와 같은 텐서를 고려하자.
a = torch.tensor([1,2,3,4,5]).reshape(-1,1)
b = torch.tensor([3,2,1,1,2]).reshape(-1,1)@ 연산자를 이용하여 \(\sum_{i=1}^{5}a_ib_i\)를 계산하라.
(풀이)
a.T @ btensor([[24]])(2) 아래와 같은 텐서를 고려하자.
torch.manual_seed(0)
x = torch.randn(100).reshape(-1,1)@연산자를 이용하여 \(\sum_{i=1}^{100}x_i^2\)을 계산하라.
$. 인덱싱아래와 같은 배열을 선언하라.
torch.manual_seed(1)
x = torch.randn(12).reshape(3,4)
xtensor([[ 0.6614, 0.2669, 0.0617, 0.6213],
[-0.4519, -0.1661, -1.5228, 0.3817],
[-1.0276, -0.5631, -0.8923, -0.0583]])(1) 1열을 추출하는 코드를 작성하라. 즉 결과가 아래와 같이 나오도록 하라.
tensor([[ 0.6614],
[-0.4519],
[-1.0276]])(2) 2-3열을 추출하는 코드를 작성하라. 즉 결과가 아래와 같이 나오도록 하라.
tensor([[ 0.2669, 0.0617],
[-0.1661, -1.5228],
[-0.5631, -0.8923]])(3) 2-3행을 추출하는 코드를 작성하라. 즉 결과가 아래와 같이 나오도록 하라.
tensor([[-0.4519, -0.1661, -1.5228, 0.3817],
[-1.0276, -0.5631, -0.8923, -0.0583]])
$. torch.einsum(1) 아래에 코드중 X.t()에 대응하는 코드를 torch.einsum으로 구현하라.
X = torch.randn(5,2)
X.t()tensor([[ 0.2055, 0.0693, 0.2733, -0.0948, -0.9798],
[ 0.6524, -0.0180, 0.1093, -2.3999, 0.5101]])(2) 아래에 코드중 X@b에 대응하는 코드를 torch.einsum으로 구현하라.
X = torch.randn(5,2)
b = torch.randn(2,1)
X@btensor([[-0.2886],
[-0.1229],
[ 0.9096],
[ 0.2358],
[-0.2577]])(3) 아래에 코드중 linr(X)에 대응하는 코드를 torch.einsum으로 구현하라.
X = torch.randn(5,2)
linr = torch.nn.Linear(2,1,bias=False)
linr(X)tensor([[ 0.1934],
[-0.2889],
[ 0.5970],
[ 0.1249],
[ 1.1178]], grad_fn=<MmBackward0>)# – 최적화$. 경사하강법(1) 아래의 함수를 최소화하는 \(x\)를 경사하강법기반의 알고리즘을 활용하여 추정하라. (꼭 SGD를 쓸 필요는 없음)
\[f(x)=(x-1)^2\]
초기값은 \(x=3\) 으로 설정하라.
(2) 아래의 함수를 최대화하는 \(x\)를 경사하강법기반의 알고리즘을 활용하여 추정하라. (꼭 SGD를 쓸 필요는 없음)
\[f(x)=-x^2 +6x-9 \]
초기값은 \(x=0\) 으로 설정하라.
hint: \(f(x)\)을 최대화하는 \(x\)는 \(-f(x)\)를 최소화한다.
$. 정규분포 MLE아래는 \(X_i \sim N(3, 2^2)\) 를 생성하는 코드이다.
torch.manual_seed(43052)
x = torch.randn((10000,1)) * 2 + 3함수 \(l(\mu, \sigma)\)를 최대화하는 \((\mu, \sigma)\)를 경사하강법기반의 알고리즘을 활용하여 추정하라. (꼭 SGD를 쓸 필요는 없음)
\[l(\mu, \sigma) = \sum_{i=1}^{n} \log f(x_i), \quad f(x_i) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left(-\frac{(x_i - \mu)^2}{2\sigma^2}\right)\]
$. 베르누이 MLE아래는 \(X_i \overset{iid}{\sim} Ber(0.8)\)을 생성하는 코드이다.
torch.manual_seed(43052)
x = torch.bernoulli(torch.tensor([0.8]*10000)).reshape(-1,1)함수 \(l(p)\)를 최대화하는 \(p\)를 경사하강법기반을 알고리즘을 활용하여 추정하라. (꼭 SGD를 쓸 필요는 없음)
\[l(p) = \sum_{i=1}^{n} \log f(x_i), \quad f(x_i) = p^{x_i} (1-p)^{1-x_i}\]
$. 회귀모형의 MLE아래의 모형을 생각하자.
아래는 위의 모형에서 얻은 샘플이다.
x = torch.linspace(0,1,10000).reshape(10000,1)
y = 0.5+2*x + torch.randn(10000,1)함수 \(l(\beta_0, \beta_1)\)를 최대화하는 \((\beta_0, \beta_1)\)를 경사하강법기반의 알고리즘을 활용하여 추정하라. (꼭 SGD를 쓸 필요는 없음)
\[ l(\beta_0, \beta_1) = \sum_{i=1}^{n} \log f(y_i), \quad f(y_i) = \frac{1}{\sqrt{2\pi}} e^{-\frac{1}{2}(y_i - \mu_i)^2}, \quad \mu_i = \beta_0 + \beta_1 x_i \]
$. 로지스틱모형의 MLE아래의 모형을 생각하자.
아래는 위의 모형에서 얻은 샘플이다.
x = torch.linspace(-1,1,10000).reshape(10000,1)
pi = torch.exp(-1 + 0.5* x) / (1 + torch.exp(-1 + 0.5 * x))
y = torch.bernoulli(pi)함수 \(l(w_0, w_1)\)을 최대화하는 파라미터 \((w_0, w_1)\)를 경사하강법기반을 알고리즘을 활용하여 추정하라. (꼭 SGD를 쓸 필요는 없음)
\[ l(w_0, w_1) = \sum_{i=1}^{n} \log f(y_i), \quad f(x_i) = \pi_i^{y_i}(1 - \pi_i)^{1 - y_i}, \quad \pi_i = \dfrac{\exp(w_0 + w_1 x_i)}{1 + \exp(w_0 + w_1 x_i)} \]
(풀이1)
X = torch.concat([torch.ones((10000,1)),x],axis=1)
What = torch.tensor([[-0.1], [-0.1]],requires_grad=True)for i in range(1,501):
pi_hat = torch.exp(X@What)/(torch.exp(X@What)+1)
pdf = pi_hat**y * (1-pi_hat)**(1-y)
l = - torch.sum(torch.log(pdf))
l.backward()
What.data = What.data - 0.00001 * What.grad
What.grad = None
if i %50 ==0:
print(f"# of iterations = {i}\tlog_L = {l.item():.4f} \t What= {What.data.reshape(-1).numpy()}")# of iterations = 50 log_L = 5980.3896 What= [-0.673138 0.06826053]
# of iterations = 100 log_L = 5877.2261 What= [-0.855518 0.18514545]
# of iterations = 150 log_L = 5853.4365 What= [-0.91999674 0.26959354]
# of iterations = 200 log_L = 5844.4150 What= [-0.94476056 0.33098808]
# of iterations = 250 log_L = 5840.1309 What= [-0.95529944 0.375552 ]
# of iterations = 300 log_L = 5837.9512 What= [-0.9604368 0.40783867]
# of iterations = 350 log_L = 5836.8213 What= [-0.9633348 0.43120864]
# of iterations = 400 log_L = 5836.2314 What= [-0.96517617 0.44812122]
# of iterations = 450 log_L = 5835.9229 What= [-0.9664379 0.4603632]
# of iterations = 500 log_L = 5835.7617 What= [-0.96733695 0.46922773](풀이2) – 약간의 통계지식을 요하는 풀이
로그가능도함수 \(l(w_0, w_1)\)을 최대화하는 \(w_0, w_1\)은 아래를 최소화하는 \(w_0, w_1\)과 같다.
\[ -l(w_0, w_1) = - \sum_{i=1}^{n} \big( y_i \log(\pi_i) + (1 - y_i) \log(1 - \pi_i) \big) \]
\(w_0, w_1\)의 추정값을 \(\hat{w}_0, \hat{w}_1\) 이라고 하고 점차 업데이트 한다고 하자. 그러면 \(l(w_0, w_1)\)을 점차 크게 만드는 일은 아래를 점차 작게 만드는 일과 같다.
\[- l(\hat{w}_0,\hat{w}_1) = - \sum_{i=1}^{n} \big( y_i \log(\hat{\pi}_i) + (1 - y_i) \log(1 - \hat{\pi}_i) \big)\]
여기에서 \(\hat{\pi}_i = \frac{\exp(\hat{w}_0 + \hat{w}_1 x_i)}{1 + \exp(\hat{w}_0 + \hat{w}_1 x_i)} = \hat{y}_i\) 이다. 따라서 위의 식은 우리에게 친숙한 \(n \times \text{BCELoss}\)의 형태임을 쉽게 알 수 있다. 결국 \(l(w_0, w_1)\)을 최대화 하는 일은 BCELoss를 최소화하는 일과 같게 된다. 따라서 아래와 같이 풀면된다.
net = torch.nn.Sequential(
torch.nn.Linear(1,1),
torch.nn.Sigmoid()
)
net[0].bias.data = torch.tensor([-0.1])
loss_fn = torch.nn.BCELoss()
optimizr = torch.optim.SGD(net.parameters(),lr=0.1)
#---#
for epoc in range(1,501):
#1
yhat = net(x)
#2
loss = loss_fn(yhat,y)
#3
loss.backward()
#4
optimizr.step()
optimizr.zero_grad()list(net.parameters())[Parameter containing:
tensor([[0.4851]], requires_grad=True),
Parameter containing:
tensor([-0.9689], requires_grad=True)]# – 회귀$. DL2024-MID-3이 문제의 경우 풀이가 https://guebin.github.io/DL2024/posts/09wk-2.html#%EB%8B%A8%EC%88%9C%ED%9A%8C%EA%B7%80%EB%AC%B8%EC%A0%9C-10%EC%A0%90 에 있습니다.
주어진 자료가 아래와 같다고 하자.
torch.manual_seed(43052)
x,_ = torch.randn(100).sort()
x = x.reshape(-1,1)
ϵ = torch.randn(100).reshape(-1,1)*0.5
y = 2.5+ 4*x + ϵplt.plot(x,y,'o')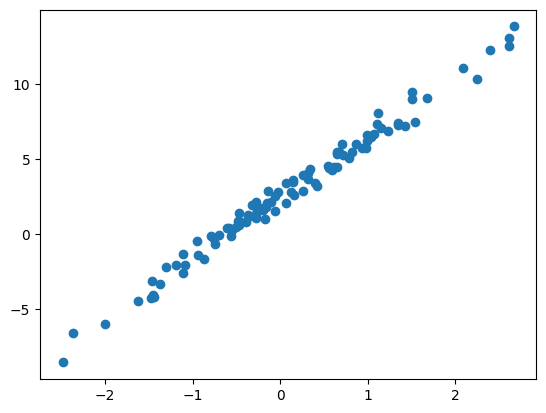
(1) torch.nn.Linear를 이용하여 아래와 같은 최초의 직선을 생성하는 네트워크를 설계하라.
\[\hat{y}_i = -5.0 + 10.0 x_i \]
(2) 아래의 수식에 대응하는 loss를 계산하라. 여기에서 \(\hat{y}_i\)은 (1)의 결과로 얻은 값을 사용하라.
\[loss = \frac{1}{n}\sum_{i=1}^{n}(y_i-\hat{y}_i)^2\]
(3) 적당한 matrix \({\bf X}_{n\times 2}\) 와 \(\hat{\bf W}_{2\times 1}\)을 정의하여 아래와 같이 \(\hat{y}_i\)을 구하라.
\[\hat{y}_i = -5.0 + 5.0 x_i \]
(4) 아래의 수식에 대응하는 loss를 계산하라. 여기에서 \(\hat{y}_i\)은 (3)의 결과로 얻은 값을 사용하라.
\[loss = \frac{1}{n}\sum_{i=1}^{n}(y_i-\hat{y}_i)^2\]
(5) (2)에서 얻은 \(\hat{y}_i\) (4)에서 얻은 \(\hat{y}_i\) 중 무엇이 더 적절하다고 생각하는가? 이유는 무엇인가? 손실(=loss)에 근거하여 설명하라.
(6) .backward() 를 이용하여 (2)와 (4)에 해당하는 미분값을 계산하라. 학습률이 0.01인 경사하강법을 이용하여 (1),(3) 에 대응하는 가중치를 update 하라.
$. 5obs아래와 같은 5개의 자료를 관측하였다고 가정하자.
| x | y | |
|---|---|---|
| 0 | 11 | 17.7 |
| 1 | 12 | 18.5 |
| 2 | 13 | 21.2 |
| 3 | 14 | 23.6 |
| 4 | 15 | 24.2 |
\(x\)에서 \(y\)로 향하는 규칙을 찾기 위해 아래와 같은 모형을 고려하였다. (\(\beta_0, \beta_1\) 대신에 \(w_0, w_1\) 이라 생각해도 무방)
\[y_i = \beta_0 + \beta_1 x_i + \epsilon_i, \quad i =1,2,\dots, n\]
(1) \(\hat{\beta}_0=3, \hat{\beta}_1=3\) 일 경우의 loss를 계산하라. 단, 손실함수는 MSELoss로 설정한다.
(2) \(\hat{\beta}_0=3, \hat{\beta}_1=3\) 에서 손실함수의 미분계수를 계산하라.
(3) 아래의 제약사항을 준수하여 추정값 \(\hat{\beta}_0=3, \hat{\beta}_1=3\) 의 값을 1회 update하라.
제약사항
yhat = X@Bhat 을 만족하는 적당한 X, Bhat을 선언하여 문제를 풀 것. (즉 torch.nn.Linear() 를 사용하지 말 것)torch.nn.MSELoss()를 사용하지 말고 직접 손실을 구할 것torch.optim.SGD()를 사용하지 말 것.(4) 아래의 제약사항을 준수하여 추정값 \(\hat{\beta}_0=3, \hat{\beta}_1=3\) 의 값을 다시 1회 update하라. 결과를 (3)과 비교하라 (동일결과가 나와야함)
제약사항
yhat = net(X) 을 만족하는 적당한 X, net을 선언하여 문제를 풀 것. 이때 net는 torch.nn.Linear(??,??,bias=False) 를 사용하여 선언할 것.torch.nn.MSELoss()를 사용하지 말고 직접 손실을 구할 것torch.optim.SGD()를 사용하지 말 것.(5) 아래의 제약사항을 준수하여 추정값 \(\hat{\beta}_0=3, \hat{\beta}_1=3\) 의 값을 다시 1회 update하라. 결과를 (3)-(4)와 비교하라 (모두 동일결과가 나와야함)
제약사항
yhat = net(X) 을 만족하는 적당한 X, net을 선언하여 문제를 풀 것. 이때 net는 torch.nn.Linear(??,??,bias=False) 를 사용하여 선언할 것.torch.nn.MSELoss()를 사용하지 말고 직접 손실을 구할 것torch.optim.SGD()를 이용하여 update할 것(6) 아래의 제약사항을 준수하여 추정값 \(\hat{\beta}_0=3, \hat{\beta}_1=3\) 의 값을 다시 1회 update하라. 결과를 (3)-(5)와 비교하라 (모두 동일결과가 나와야함)
제약사항
yhat = net(x) 을 만족하는 적당한 x, net을 선언하여 문제를 풀 것. 이때 net는 torch.nn.Linear(??,??,bias=True) 를 사용하여 선언할 것.torch.nn.MSELoss()를 사용하지 말고 직접 손실을 구할 것torch.optim.SGD()를 사용하지 말 것.$. 2d아래의 데이터를 고려하자.
df = pd.read_csv("https://raw.githubusercontent.com/guebin/DL2025/main/posts/regression_2d.csv")
x1 = torch.tensor(df.x1).float().reshape(-1,1)
x2 = torch.tensor(df.x2).float().reshape(-1,1)
y = torch.tensor(df.y).float().reshape(-1,1)\(x_1, x_2\) 에서 \(y\)로 향하는 규칙을 찾기 위해 아래와 같은 모형을 고려하였다. (\(\beta_0,\beta_1,\beta_2\) 대신에 \(w_0, w_1, w_2\) 라고 생각해도 무방)
\[y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \epsilon_i \quad i = 1, 2, \ldots, n\]
(1) 아래의 제약사항에 맞추어서 \(\beta_0,\beta_1,\beta_2\)의 값을 추정하라.
제약사항
yhat = X@Bhat 을 만족하는 적당한 X, Bhat을 선언하여 문제를 풀 것. (즉 torch.nn.Linear() 를 사용하지 말 것)torch.nn.MSELoss()를 사용하지 말고 직접 손실을 구할 것torch.optim.SGD()를 사용하지 말 것.hint: 참값은 \(\beta_0=2.5, \beta_1=4 , \beta_2= -2\) 임
(2) (1)에서 구한 X에 대하여 아래의 수식을 이용하여 추정값을 구하여라.
\[\hat{\boldsymbol \beta}^{LSE} = \begin{bmatrix} \hat{\beta}_0^{LSE} \\ \hat{\beta}_1^{LSE} \\ \hat{\beta}_2^{LSE}\end{bmatrix} = ({\bf X}^\top {\bf X})^{-1}{\bf X}^\top {\bf y}\]
(1)에서 추정한 값과 비교하라. 비슷한가?
hint: (1)과 (2)의 추정값은 거의 같아야합니다..
(3) 이 문제에서 모수의 참값은 \(\beta_0=2.5, \beta_1=4 , \beta_2= -2\) 이다. epoch을 증가할수록 (1)에서 추정된 값은 참값에 근접해갈까? (epoch을 무한대로 하면 결국 참값에 수렴할까?)
(4) 아래의 제약사항에 맞추어서 \(\beta_0,\beta_1,\beta_2\)의 값을 다시 추정하라.
제약사항
yhat = net(X) 을 만족하는 적당한 X, net을 선언하여 문제를 풀 것. 이때 net는 torch.nn.Linear(??,??,bias=False) 를 사용하여 선언할 것.torch.nn.MSELoss()를 이용하여 손실을 구할 것torch.optim.SGD()를 이용하여 update할 것(5) 아래의 제약사항에 맞추어서 \(\beta_0,\beta_1,\beta_2\)의 값을 다시 추정하라.
제약사항
yhat = net(X) 을 만족하는 적당한 X, net을 선언하여 문제를 풀 것. 이때 net는 torch.nn.Linear(??,??,bias=True) 를 사용하여 선언할 것.torch.nn.MSELoss()를 이용하여 손실을 구할 것torch.optim.SGD()를 이용하여 update할 것$. DL2022-MID-2이 문제의 경우 풀이가 https://guebin.github.io/DL2022/posts/2022-10-28-9wk-1-midsol.html 에 있습니다.
주어진 자료가 아래와 같다고 하자.
torch.manual_seed(7676)
x = torch.randn(100).sort().values
ϵ = torch.randn(100)*0.5
y = 2.5+ 4*x + ϵplt.plot(x,y,'o')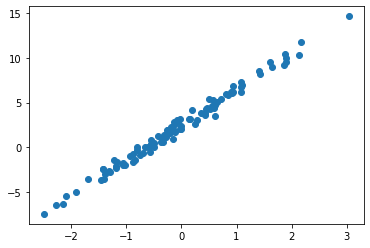
아래와 같은 모형을 가정하고 물음에 답하라.
\[y_i = w_0+w_1 x_i +\epsilon_i, \quad \epsilon_i \overset{iid}{\sim} N(0,\sigma^2)\]
(1) ??를 적당하게 채워 아래와 같은 네트워크를 설정하고 최초의 예측값이 \(\hat{y}_i=-5+10x_i\)가 출력되도록 net의 가중치를 조정하라.
net = torch.nn.Linear(in_features=2,out_features=??,bias=??)(2) 학습률은 0.1로 설정하고 torch.optim.Adam을 이용하여 optimizer를 선언하라. \((\hat{w}_0,\hat{w}_1)=(-5,10)\)에서 MSELoss의 미분계수 \(\frac{\partial}{\partial {\bf W}}loss(w_0,w_1) ~\Big|_{~\hat{w}_0,\hat{w}_1}\)를 구하고 이를 바탕으로 \((\hat{w}_0,\hat{w}_1)\)의 값을 1회 갱신하라. 계산된 미분계수값과 갱신된 \((\hat{w}_0,\hat{w}_1)\)의 값을 출력하라.
(3) (2)에서 설정한 optimizer를 이용하여 \((\hat{w}_0, \hat{w}_1)\)의 값을 5회 갱신한 값을 구하여라. - 문제(2)에 갱신한 1회를 포함하여 5회임.
(4) 학습률을 0.2로 설정하고 torch.optim.SGD를 이용하여 새로운 optimizr를 선언하라. (3)의 결과로 총 5회 갱신된 값에 이어서 10회 추가로 학습하라. 학습된 값은 얼마인가?
(5) (4)의 수렴값이 학습이 잘 되었다고 생각하는가? 잘 되었다고 생각하면 그 근거는 무엇인가? (단, \((w_0,w_1)\)의 참값은 모른다고 가정한다)
$. 과잉매개변수 (DL2022-ASS-2)이 내용은 overparameterized model에 대한 내용을 다루고 있습니다. 이 문제의 경우는 풀이가 https://guebin.github.io/DL2022/posts/II.%20DNN/2022-10-26-Assignment2.html 에 제공되어있습니다.
Overparameterized model은 03wk-1, 3-B 의 내용과도 관련 있습니다.
아래와 같은 자료가 있다고 가정하자.
x = torch.rand([1000,1])*2-1
y = 3.14 + 6.28*x + torch.randn([1000,1]) plt.plot(x,y,'o',alpha=0.1)
(1) 아래의 모형을 가정하고 \(\beta_0,\beta_1\)을 파이토치를 이용하여 추정하라.
(2) 아래의 모형을 가정하고 \(\beta_0\)를 파이토치를 이용하여 추정하라.
(3) 아래의 모형을 가정하고 \(\beta_1\)을 파이토치를 이용하여 추정하라.
(4) 아래의 모형을 가정하고 \(\alpha_0,\beta_0,\beta_1\)을 파이토치를 이용하여 추정하라.
\(\hat{\alpha}_0+\hat{\beta}_0\)은 얼마인가? 이 값과 문제 (1)에서 추정된 \(\hat{\beta_0}\)의 값과 비교하여 보라.
(5) 아래의 모형을 가정하고 \(\alpha_0,\alpha_1,\beta_0,\beta_1\)을 파이토치를 이용하여 추정하라.
\(\hat{\alpha}_0+\hat{\beta}_0\), \(\hat{\alpha}_1 + \hat{\beta}_1\)의 값은 각각 얼마인가? 이 값들을 (1) 에서 추정된 \(\hat{\beta}_0\), \(\hat{\beta}_1\) 값들과 비교하라.
(6) 다음은 위의 모형에 대하여 학생들이 discussion한 결과이다. 올바르게 해석한 학생을 모두 골라라.
민정: \((x_i,y_i)\)의 산점도는 직선모양이고 직선의 절펴과 기울기 모두 유의미해 보이므로 \(y_i = \beta_0 + \beta_1 x_i\) 꼴을 적합하는게 좋겠다.
슬기: 나도 그렇게 생각해. 그래서 (2)-(3)과 같이 기울기를 제외하고 적합하거나 절편을 제외하고 적합하면 underfitting의 상황에 빠질 수 있어.
성재: (2)의 경우 사실상 \(\bar{y}=\frac{1}{n}\sum_{i=1}^{n}y_i\)를 추정하는 것과 같아지게 되지.
세민: (4)의 경우 \({\bf X}=\begin{bmatrix} 1 & x_1 \\ 1 & x_2 \\ \dots & \dots \\ 1 & x_n \end{bmatrix}\) 와 같이 설정하고 네트워크를 아래와 같이 설정할 경우 얻어지는 모형이야.
net = torch.nn.Linear(in_features=2,out_features=1,bias=True)구환: 모델 (4)-(5)는 표현력은 (1)과 동일하지만 추정할 파라메터는 (1)보다 많으므로 효율적인 모델이라고 볼 수 없어.
# – 분류$. iris아래의 자료를 고려하자.
df = pd.read_csv("https://raw.githubusercontent.com/guebin/DL2025/main/posts/iris.csv")
df| SepalLength | SepalWidth | PetalLength | PetalWidth | Species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0.0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0.0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0.0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0.0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0.0 |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | 2.0 |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | 2.0 |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | 2.0 |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | 2.0 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | 2.0 |
150 rows × 5 columns
위의 자료는 아이리스 데이터셋으로 머신러닝에서 자주 사용되는 분류(classification) 예제 데이터이다. 데이터는 다음과 같은 특징을 가지고 있다:
샘플 수: 150개
특징 수: 4개
클래스 수: 3개 (각 50개 샘플)
(1) 주어진 데이터를 8:2 비율로 학습용(df_train)과 테스트용(df_test)으로 나누고, SepalLength, SepalWidth, PetalLength, PetalWidth를 입력으로 하여 Species를 예측할 수 있도록 데이터를 텐서 형태로 변환하라.
hint: 아래의 코드를 활용할 것
df_train = df.sample(frac=0.8, random_state=42)
df_test = df.drop(df_train.index)
#---#
X = torch.tensor(df_train.iloc[:,:4].values).float()
y = ???
XX = ???
yy = ???(2) 아래의 제약사항에 맞추어 Species를 예측할 수 있는 적당한 네트워크를 학습하라.
제약사항
(3) 아래의 제약사항에 맞추어 Species를 예측할 수 있는 적당한 네트워크를 학습하라.
제약사항
batch_size = 10 으로 설정할 것(4) 아래의 제약사항에 맞추어 Species를 예측할 수 있는 적당한 네트워크를 학습하라.
제약사항
batch_size = 50 으로, test에서는 batch_size=30을 설정할것(5) 아래의 제약사항에 맞추어 Species를 예측할 수 있는 적당한 네트워크를 학습하라.
제약사항
batch_size=50 으로, test에서는 batch_size=30을 설정할것# – XAI아래의 문제는 시험에 똑같이 냅니다.
아래의 코드를 이용하여 OxfordIIITPet 자료를 다운로드하고 물음에 답하라.
train_dataset = torchvision.datasets.OxfordIIITPet(
root='./data',
split='trainval',
download=True,
target_types='binary-category'
)
test_dataset = torchvision.datasets.OxfordIIITPet(
root='./data',
split='test',
download=True,
target_types='binary-category'
)(1) 이 데이터를 사용하여 ResNet18을 기반으로 한 이진 분류 모델을 학습 및 평가하는 전체 파이프라인 코드를 작성하시오. 다음 제약사항을 만족해야 한다:
제약사항
(2) 아래의 이미지에 대한 로짓값과 그에 대응하는 확률값을 계산하고 인공지능이 이 이미지를 개라고 생각하는지 고양이라고 생각하는지 답하라.
url = 'https://github.com/guebin/DL2025/blob/main/imgs/hani2.jpeg?raw=true'
hani_pil = PIL.Image.open(
io.BytesIO(requests.get(url).content)
)
hani_pil
(3) (2)의 이미지에 대한 인공지능의 판단근거를 Class Activation Map (CAM) (Zhou et al. 2016)을 이용하여 시각화하라.
# – GAN아래의 문제는 시험에 똑같이 냅니다.
아래의 코드를 이용하여 MNIST 자료를 다운로드하라.
dataset = torchvision.datasets.MNIST(
root = './data',
download=True
)
to_tensor = torchvision.transforms.ToTensor()
X_real = torch.stack([to_tensor(Xi) for Xi, yi in dataset if yi==8])이안굿펠로우의 generative adversarial networks (GAN) (Goodfellow et al. 2014) 을 활용하여 (n,6) shape의 노이즈를 입력으로 하고 (n,1,28,28) shape 의 가짜이미지를 생성하는 네트워크를 훈련하고 결과를 시각화하라. 시각화 예시는 아래와 같다.

# – parameter count(1) 아래의 네트워크에서 학습가능한 파라메터수를 count하라.
net = torch.nn.Sequential(
torch.nn.Linear(10,2,bias=False),
torch.nn.Sigmoid(),
torch.nn.Linear(2,1,bias=False)
)(풀이1)
10*2 + 2*122(풀이2)
para_list = list(net.parameters())len(para_list)2para_list[0].shapetorch.Size([2, 10])para_list[1].shapetorch.Size([1, 2])따라서 2*10+1*2 = 22
(풀이3)
total = 0
for para in net.parameters():
total = total + torch.prod(torch.tensor(para.shape))
totaltensor(22)(2) 아래의 네트워크에서 학습가능한 파라메터수를 count하라.
net = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=3, out_channels=5, kernel_size=(5,5),bias=False)
)(풀이1)
3*5*25375(풀이2)
total = 0
for para in net.parameters():
total = total + torch.prod(torch.tensor(para.shape))
totaltensor(375)