import torch
import pandas as pd
import matplotlib.pyplot as plt11wk-2: (순환신경망) – abc, abcd, 임베딩 공간의 이해, AbAcAd, 겹장(덧장)
![]()
1. 강의영상
2. Imports
3. 예비학습
A. tanh
x = torch.linspace(-5,5,1001)
tanh = torch.nn.Tanh()
plt.plot(x,tanh(x).data)
B. softmax
logits = torch.randn((10,5))
logitstensor([[ 0.6408, -0.2422, 1.3521, 1.1399, -0.3036],
[-0.5242, -0.3710, -0.3861, -0.5475, 3.1393],
[ 0.5174, -1.3213, 3.1802, -0.6713, 0.5917],
[ 0.0931, 1.0697, 0.6469, -1.1904, -0.1057],
[-1.3722, 0.4665, -0.7705, -0.6630, -1.1054],
[ 1.2289, 1.4994, -0.9319, 0.8154, -0.2033],
[-0.3431, 0.3966, -0.9672, -1.6696, 0.7154],
[ 0.4969, -0.6918, 1.1579, -2.4760, 0.1766],
[ 0.8880, -0.0768, 1.5095, -0.2842, 0.4944],
[ 0.2732, -2.0850, -0.5531, 0.1073, -0.1218]])probs = torch.nn.functional.softmax(logits,dim=1)
probstensor([[0.1823, 0.0754, 0.3712, 0.3002, 0.0709],
[0.0231, 0.0269, 0.0265, 0.0226, 0.9009],
[0.0593, 0.0094, 0.8494, 0.0181, 0.0638],
[0.1540, 0.4090, 0.2680, 0.0427, 0.1263],
[0.0803, 0.5050, 0.1466, 0.1632, 0.1049],
[0.3007, 0.3941, 0.0346, 0.1988, 0.0718],
[0.1475, 0.3091, 0.0790, 0.0392, 0.4252],
[0.2489, 0.0758, 0.4820, 0.0127, 0.1807],
[0.2366, 0.0901, 0.4404, 0.0733, 0.1596],
[0.3275, 0.0310, 0.1434, 0.2775, 0.2206]])4. abc
A. Data
txt = list('abc'*100)
txt[:10]['a', 'b', 'c', 'a', 'b', 'c', 'a', 'b', 'c', 'a']df_train = pd.DataFrame({'x': txt[:-1], 'y': txt[1:]})
df_train[:5]| x | y | |
|---|---|---|
| 0 | a | b |
| 1 | b | c |
| 2 | c | a |
| 3 | a | b |
| 4 | b | c |
x = torch.tensor(df_train.x.map({'a':0,'b':1,'c':2}))
y = torch.tensor(df_train.y.map({'a':0,'b':1,'c':2}))# x,y
# --- 원래는 이 형식이 틀림
# 그런데 y는 onehot 안해도 알아서 토치에서 해주므로 length-n 벡터형태로 정리해도 무방
# 그리고 x는 onehot+linr를 쓰지않고 임베딩을 쓰려고 마음먹었으면 length-n 벡터형태로 정리해도 무방B. MLP – 하나의 은닉노드
- 적합
torch.manual_seed(43052)
net = torch.nn.Sequential(
torch.nn.Embedding(num_embeddings=3, embedding_dim=1),
torch.nn.Tanh(),
torch.nn.Linear(1,3)
)
loss_fn = torch.nn.CrossEntropyLoss()
optimizr = torch.optim.Adam(net.parameters(),lr=0.1)
#---#
for epoc in range(50):
#1
netout = net(x)
#2
loss = loss_fn(netout,y)
#3
loss.backward()
#4
optimizr.step()
optimizr.zero_grad()netout.argmax(axis=1)[:5], y[:5](tensor([1, 2, 0, 1, 2]), tensor([1, 2, 0, 1, 2]))- 결과시각화
ebdd,tanh,linr = netX = torch.nn.functional.one_hot(x)
h = tanh(ebdd(x))
netout = logits = linr(h)
yhat = torch.nn.functional.softmax(netout,dim=1)
mat = torch.concat([X,h,netout/netout.max(),yhat],axis=1).data
plt.matshow(mat[:6], vmin=-1, vmax=1, cmap="bwr")
plt.colorbar()
plt.axvline(2.5,color="lime")
plt.axvline(3.5,color="lime")
plt.axvline(6.5,color="lime")
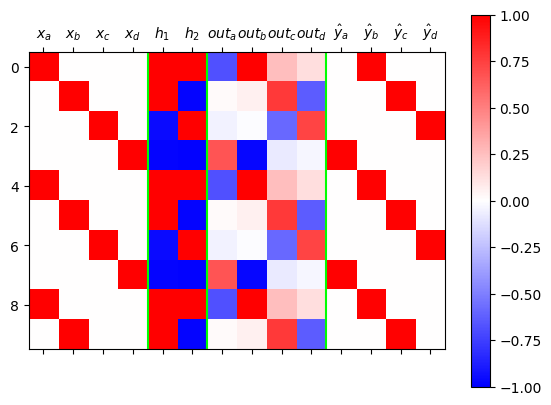
plt.xticks(ticks=[0,1,2,3,4,5,6,7,8,9],labels=[r"$x_a$",r"$x_b$",r"$x_c$",r"$h$",r"$out_a$",r"$out_b$",r"$out_c$",r"$\hat{y}_a$",r"$\hat{y}_b$",r"$\hat{y}_c$"]);
plt.tight_layout()/tmp/ipykernel_906200/1114894007.py:12: UserWarning: This figure includes Axes that are not compatible with tight_layout, so results might be incorrect.
plt.tight_layout()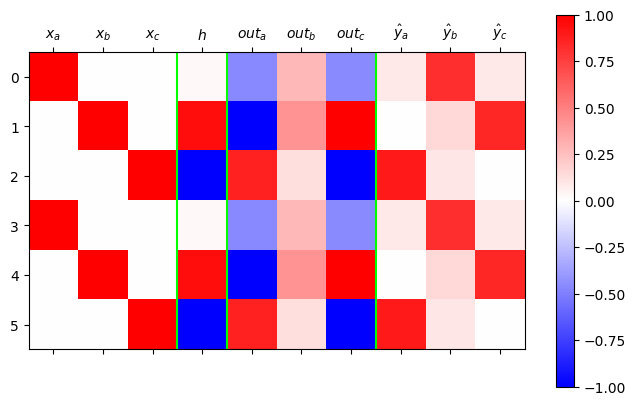
- 시각화결과해석: 학습이 잘 된것 같지만 깔끔하지 않음.
- netout 을 보는 요령: 가장 빨간부분이 예측값이 된다.
- 문제1: \(out_b\)의 경우 애매한 색깔만 있음. 네트워크가 정답을 잘 모른다는 의미.
- 문제1의 원인: \(out_b\)의 경우에 대응하는 \({\boldsymbol h}\)를 살펴보니 흰색임. 이것은 값이 0이라는 의미인데 이때는 \({\boldsymbol h}\) 에 걸리는 선형변환 \(linr\) 의 weight 가 의미없고 bias만 의미있기 때문에 특징을 잡기에 불리하다.
- 문제2: \({\boldsymbol h}\)가 흰색이면(=0이 나오면) 불리하며, 확실한 색을 가지고 있는것이 유리함. 그렇지만 확실한 색인 빨강 파랑은 이미 차지된 상태라서 어쩔수 없이 흰색으로 선택된 것.
- 문제2를 해결하는 방법: \(a,b,c\)라는 세문자를 표현하기에 \((-1,1)\)사이의 숫자는 너무 불리함..
C. MLP – 두개의 은닉노드
- 적합
torch.manual_seed(43052)
net = torch.nn.Sequential(
torch.nn.Embedding(num_embeddings=3, embedding_dim=2),
torch.nn.Tanh(),
torch.nn.Linear(2,3)
)
loss_fn = torch.nn.CrossEntropyLoss()
optimizr = torch.optim.Adam(net.parameters(),lr=0.1)
#---#
for epoc in range(50):
#1
netout = net(x)
#2
loss = loss_fn(netout,y)
#3
loss.backward()
#4
optimizr.step()
optimizr.zero_grad()netout.argmax(axis=1)[:5], y[:5](tensor([1, 2, 0, 1, 2]), tensor([1, 2, 0, 1, 2]))- 결과시각화
ebdd, tanh, linr = net
X = torch.nn.functional.one_hot(x)
h = tanh(ebdd(x))
netout = logits = linr(h)
yhat = torch.nn.functional.softmax(netout,dim=1)
mat = torch.concat([X,h,netout/netout.max(),yhat],axis=1).data
plt.matshow(mat[:6], vmin=-1, vmax=1, cmap="bwr")
plt.colorbar()
plt.axvline(2.5,color="lime")
plt.axvline(4.5,color="lime")
plt.axvline(7.5,color="lime")
plt.xticks(ticks=[0,1,2,3,4,5,6,7,8,9,10],labels=[r"$x_a$", r"$x_b$", r"$x_c$",r"$h_1$",r"$h_2$",r"$out_a$",r"$out_b$",r"$out_c$",r"$\hat{y_a}$",r"$\hat{y_b}$",r"$\hat{y_c}$"]);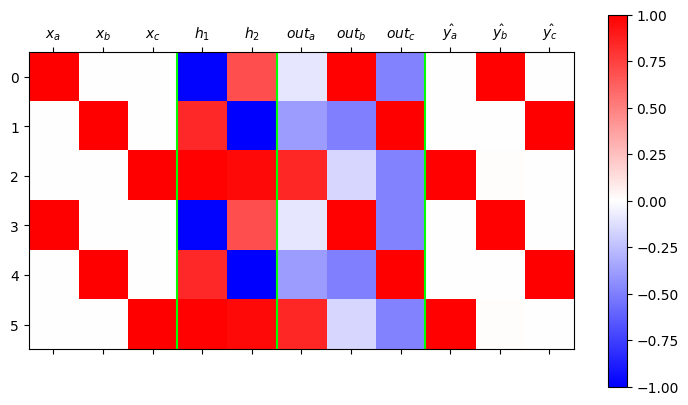
- 시각화결과해석: 깔끔함. netout의 가장 빨간부분도 너무 명확함. \({\boldsymbol h}\)가 0이 아닌 값으로 학습되어있음
- x=a \(\Rightarrow\) h=(파,빨) \(\Rightarrow\) y=b
- x=b \(\Rightarrow\) h=(빨,파) \(\Rightarrow\) y=c
- x=c \(\Rightarrow\) h=(빨,빨) \(\Rightarrow\) y=a
- h = (파,파) 는 사용하지 않음. –> 문자열 d를 하나 더 쓸수 있는 공간이 \(h\)에 있다고 해석할 수 있음..
5. abcd
A. Data
txt = list('abcd'*100)
txt[:10]['a', 'b', 'c', 'd', 'a', 'b', 'c', 'd', 'a', 'b']df_train = pd.DataFrame({'x':txt[:-1], 'y':txt[1:]})
df_train[:5]| x | y | |
|---|---|---|
| 0 | a | b |
| 1 | b | c |
| 2 | c | d |
| 3 | d | a |
| 4 | a | b |
x = torch.tensor(df_train.x.map({'a':0, 'b':1, 'c':2, 'd':3}))
y = torch.tensor(df_train.y.map({'a':0, 'b':1, 'c':2, 'd':3}))B. MLP – 하나의 은닉노드
- 적합
torch.manual_seed(43052)
net = torch.nn.Sequential(
torch.nn.Embedding(num_embeddings=4, embedding_dim=1),
torch.nn.Tanh(),
torch.nn.Linear(1,4)
)
ebdd,tanh,linr = net
ebdd.weight.data = torch.tensor([[-0.3333],[-2.5000],[5.0000],[0.3333]])
linr.weight.data = torch.tensor([[1.5000],[-6.0000],[-2.0000],[6.0000]])
linr.bias.data = torch.tensor([0.1500, -2.0000, 0.1500, -2.000])
loss_fn = torch.nn.CrossEntropyLoss()
optimizr = torch.optim.Adam(net.parameters(),lr=0.1)
#---#
for epoc in range(50):
#1
netout = net(x)
#2
loss = loss_fn(netout,y)
#3
loss.backward()
#4
optimizr.step()
optimizr.zero_grad()- 결과시각화
ebdd,tanh,linr = net
X = torch.nn.functional.one_hot(x)
h = tanh(ebdd(x)).data
netout = linr(tanh(ebdd(x))).data
yhat = torch.nn.functional.softmax(net(x),dim=1).data
mat = torch.concat([X,h,netout/netout.max(),yhat],axis=1)
#---#
plt.matshow(mat[:10, :],cmap="bwr",vmin=-1,vmax=1)
plt.colorbar()
plt.axvline(3.5,color="lime")
plt.axvline(4.5,color="lime")
plt.axvline(8.5,color="lime")
plt.xticks(
ticks=[0,1,2,3,4,5,6,7,8,9,10,11,12],
labels=[
r"$x_a$",r"$x_b$",r"$x_c$",r"$x_d$",
r"$h$",
r"$out_a$",r"$out_b$",r"$out_c$",r"$out_d$",
r"$\hat{y}_a$",r"$\hat{y}_b$",r"$\hat{y}_c$",r"$\hat{y}_d$"]
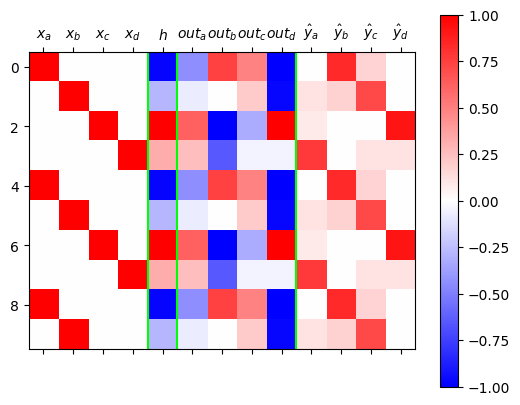
);
C. MLP – 두개의 은닉노드
- 적합
#torch.manual_seed(43052)
net = torch.nn.Sequential(
torch.nn.Embedding(num_embeddings=4, embedding_dim=2),
torch.nn.Tanh(),
torch.nn.Linear(2,4)
)
loss_fn = torch.nn.CrossEntropyLoss()
optimizr = torch.optim.Adam(net.parameters(),lr=0.1)
#---#
for epoc in range(50):
#1
netout = net(x)
#2
loss = loss_fn(netout,y)
#3
loss.backward()
#4
optimizr.step()
optimizr.zero_grad()- 결과시각화
ebdd,tanh,linr = net
X = torch.nn.functional.one_hot(x)
h = tanh(ebdd(x)).data
netout = linr(tanh(ebdd(x))).data
yhat = torch.nn.functional.softmax(net(x),dim=1).data
mat = torch.concat([X,h,netout/netout.max(),yhat],axis=1)
#---#
plt.matshow(mat[:10, :],cmap="bwr",vmin=-1,vmax=1)
plt.colorbar()
plt.axvline(3.5,color="lime")
plt.axvline(5.5,color="lime")
plt.axvline(9.5,color="lime")
plt.xticks(
ticks=[0,1,2,3,4,5,6,7,8,9,10,11,12,13],
labels=[
r"$x_a$",r"$x_b$",r"$x_c$",r"$x_d$",
r"$h_1$",r"$h_2$",
r"$out_a$",r"$out_b$",r"$out_c$",r"$out_d$",
r"$\hat{y}_a$",r"$\hat{y}_b$",r"$\hat{y}_c$",r"$\hat{y}_d$"]
);
D. 비교실험
class Net1(torch.nn.Module):
def __init__(self):
super().__init__()
## 우리가 yhat을 구할때 사용할 레이어를 정의
self.ebdd = torch.nn.Embedding(4,1)
self.tanh = torch.nn.Tanh()
self.linr = torch.nn.Linear(1,4)
## 정의 끝
def forward(self,X):
## yhat을 어떻게 구할것인지 정의
ebdd_x = self.ebdd(x)
h = self.tanh(ebdd_x)
netout = self.linr(h)
## 정의 끝
return netoutclass Net2(torch.nn.Module):
def __init__(self):
super().__init__()
## 우리가 yhat을 구할때 사용할 레이어를 정의
self.ebdd = torch.nn.Embedding(4,2)
self.tanh = torch.nn.Tanh()
self.linr = torch.nn.Linear(2,4)
## 정의 끝
def forward(self,X):
## yhat을 어떻게 구할것인지 정의
ebdd_x = self.ebdd(x)
h = self.tanh(ebdd_x)
netout = self.linr(h)
## 정의 끝
return netoutfig, ax = plt.subplots(5,5,figsize=(10,10))
for i in range(5):
for j in range(5):
net = Net1()
optimizr = torch.optim.Adam(net.parameters(),lr=0.1)
loss_fn = torch.nn.CrossEntropyLoss()
for epoc in range(50):
## 1
netout = net(x)
## 2
loss = loss_fn(netout,y)
## 3
loss.backward()
## 4
optimizr.step()
optimizr.zero_grad()
h = net.tanh(net.ebdd(x)).data
yhat = torch.nn.functional.softmax(net(x),dim=1).data
mat = torch.concat([h,yhat],axis=1)
ax[i][j].matshow(mat[:6, :],cmap='bwr',vmin=-1,vmax=1)
ax[i][j].axvline(0.5,color='lime')
ax[i][j].set_xticks(ticks=[0,1,2,3,4],labels=[r"$h$",r"$\hat{y}_a$",r"$\hat{y}_b$",r"$\hat{y}_c$",r"$\hat{y}_d$"])
fig.suptitle("# of hidden nodes = 1", size=20)
fig.tight_layout()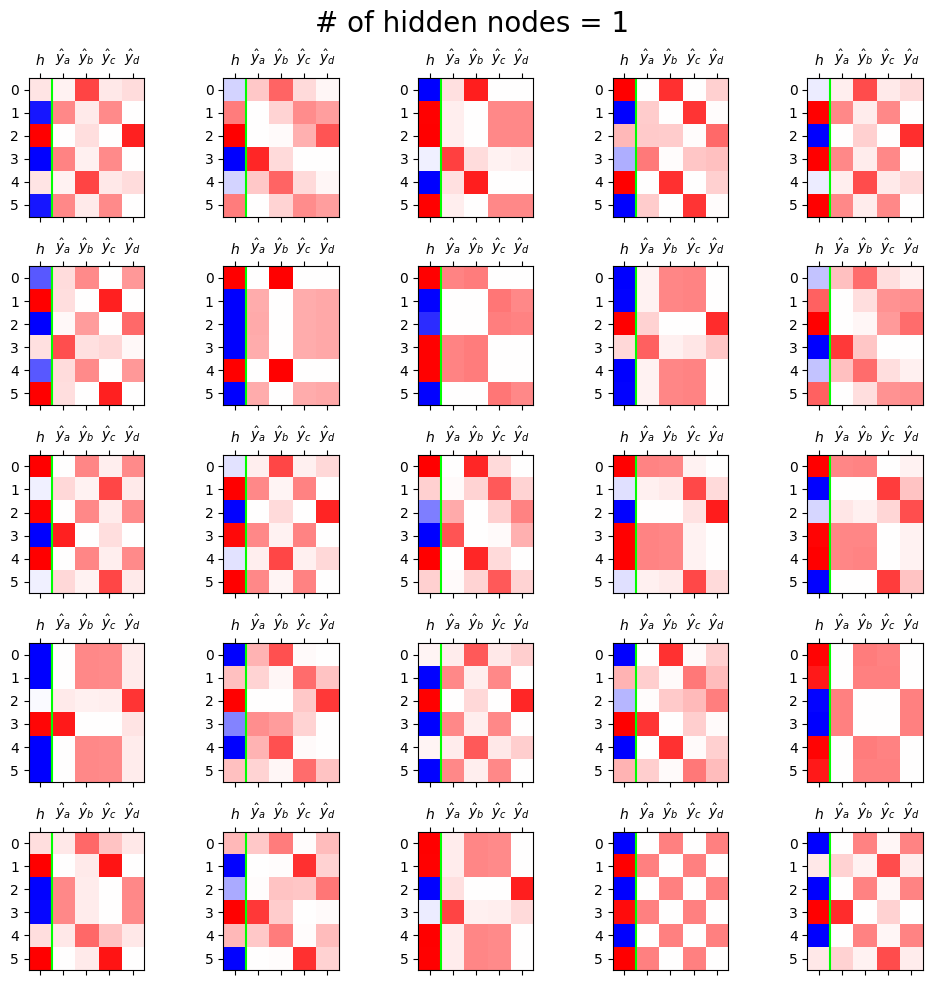
fig, ax = plt.subplots(5,5,figsize=(10,10))
for i in range(5):
for j in range(5):
net = Net2()
optimizr = torch.optim.Adam(net.parameters(),lr=0.1)
loss_fn = torch.nn.CrossEntropyLoss()
for epoc in range(50):
## 1
netout = net(x)
## 2
loss = loss_fn(netout,y)
## 3
loss.backward()
## 4
optimizr.step()
optimizr.zero_grad()
h = net.tanh(net.ebdd(x)).data
yhat = torch.nn.functional.softmax(net(x),dim=1).data
mat = torch.concat([h,yhat],axis=1)
ax[i][j].matshow(mat[:6, :],cmap='bwr',vmin=-1,vmax=1)
ax[i][j].axvline(1.5,color='lime')
ax[i][j].set_xticks(ticks=[0,1,2,3,4,5],labels=[r"$h_1$",r"$h_2$",r"$\hat{y}_a$",r"$\hat{y}_b$",r"$\hat{y}_c$",r"$\hat{y}_d$"])
fig.suptitle("# of hidden nodes = 2", size=20)
fig.tight_layout() 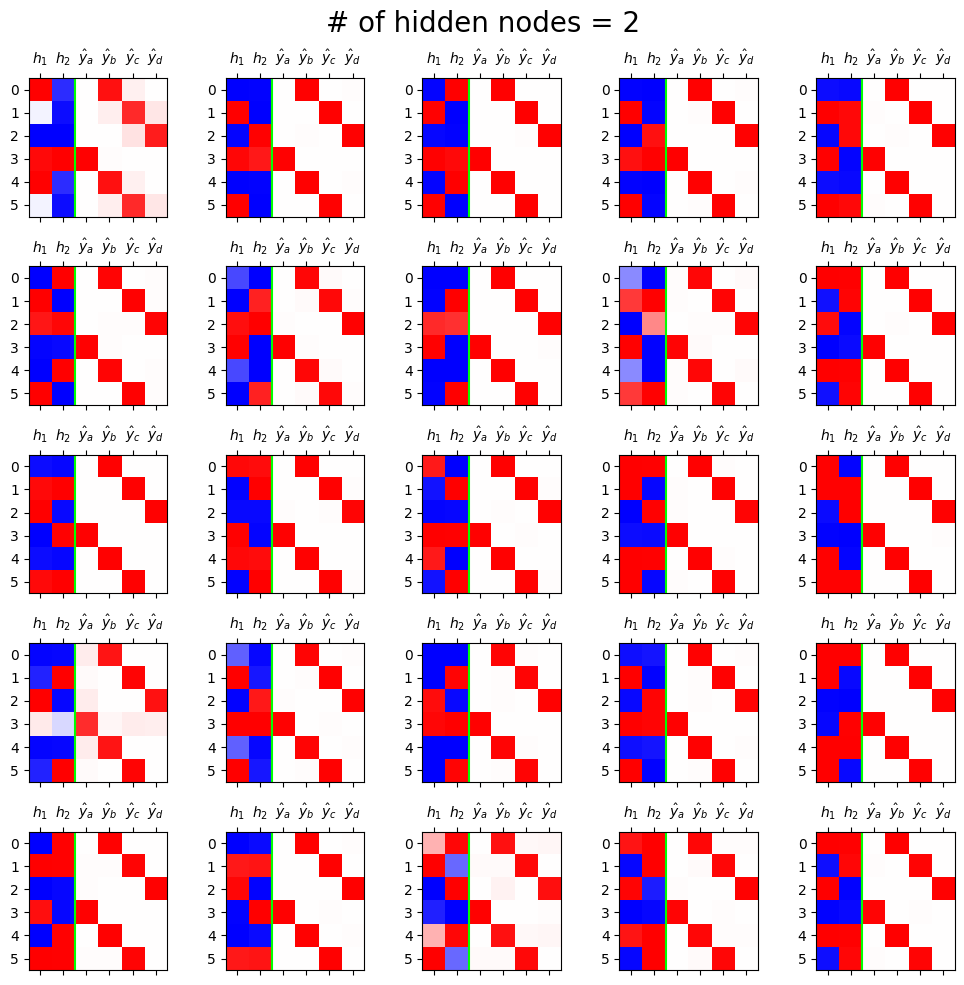
6. \({\boldsymbol h}\) 에 대하여 (\(\star\star\star\))
- \({\boldsymbol h}\)는 사실 문자열 “abcd”들을 숫자로 바꾼 표현이라 해석할 수 있음. 즉 원핫인코딩과 다른 또 다른 형태의 숫자표현이라 해석할 수 있다.
- 사실 \({\boldsymbol h}\)는 원핫인코딩보다 약간 더 (1) 액기스만 남은 느낌 + (2) 숙성된 느낌을 준다
- (why1) \({\boldsymbol h}\)는 \({\boldsymbol x}\) 보다 \({\boldsymbol y}\)를 예측함에 좀 더 직접적인 역할을 한다. 즉 \({\boldsymbol x}\) 숫자보다 \({\boldsymbol h}\) 숫자가 잘 정리되어 있고 (차원이 낮고) 입력의 특징을 잘 정리한 (추천시스템의 MBTI처럼) 의미있는 숫자이다.
- (why2) \({\boldsymbol x}\)는 학습없이 그냥 얻어지는 숫자표현이지만, \({\boldsymbol h}\)는 학습을 통하여 고치고 고치고 고친 숫자표현이다.
7. AbAcAd – 실패
A. Data
txt = list('AbAcAd'*50)
txt[:10]['A', 'b', 'A', 'c', 'A', 'd', 'A', 'b', 'A', 'c']df_train = pd.DataFrame({'x':txt[:-1], 'y':txt[1:]})
df_train[:5]| x | y | |
|---|---|---|
| 0 | A | b |
| 1 | b | A |
| 2 | A | c |
| 3 | c | A |
| 4 | A | d |
x = torch.tensor(df_train.x.map({'A':0,'b':1,'c':2,'d':3}))
y = torch.tensor(df_train.y.map({'A':0,'b':1,'c':2,'d':3}))x[:8],y[:8](tensor([0, 1, 0, 2, 0, 3, 0, 1]), tensor([1, 0, 2, 0, 3, 0, 1, 0]))B. MLP – 두개의 은닉노드 (실패)
- 적합
net = torch.nn.Sequential(
torch.nn.Embedding(4,2),
torch.nn.Tanh(),
torch.nn.Linear(2,4)
)
loss_fn = torch.nn.CrossEntropyLoss()
optimizr = torch.optim.Adam(net.parameters(),lr=0.1)
#---#
for epoc in range(100):
#1
netout = net(x)
#2
loss = loss_fn(netout,y)
#3
loss.backward()
#4
optimizr.step()
optimizr.zero_grad()- 결과시각화
ebdd,tanh,linr = net
X = torch.nn.functional.one_hot(x)
h = tanh(ebdd(x)).data
netout = linr(tanh(ebdd(x))).data
yhat = torch.nn.functional.softmax(net(x),dim=1).data
mat = torch.concat([X,h,netout/netout.max(),yhat],axis=1)
#---#
plt.matshow(mat[:10, :],cmap="bwr",vmin=-1,vmax=1)
plt.colorbar()
plt.axvline(3.5,color="lime")
plt.axvline(5.5,color="lime")
plt.axvline(9.5,color="lime")
plt.xticks(
ticks=[0,1,2,3,4,5,6,7,8,9,10,11,12,13],
labels=[
r"$x_A$",r"$x_b$",r"$x_c$",r"$x_d$",
r"$h_1$",r"$h_2$",
r"$out_A$",r"$out_b$",r"$out_c$",r"$out_d$",
r"$\hat{y}_A$",r"$\hat{y}_b$",r"$\hat{y}_c$",r"$\hat{y}_d$"]
);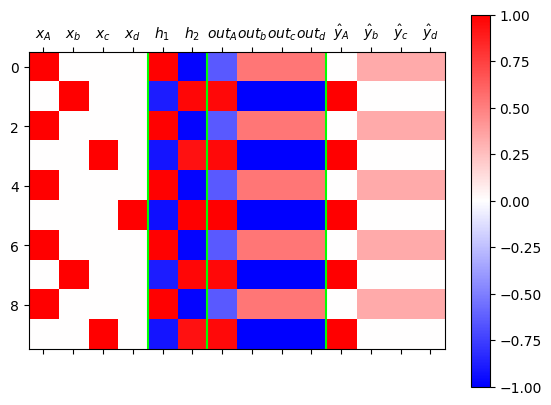
- 100번 시도해봤자 100번 망함
C. Discussions
- 왜 망했을까?
- hello1 문자열을 맞출 수 있을까?
1 2015년 Andrej Karpathy(안드레이 카파시)의 “전설적인” 블로그 https://karpathy.github.io/2015/05/21/rnn-effectiveness/ 에 담긴 예제
- 이전시점을 많이 고려하면 맞출수는 있음.
- 그러나 이러한 방법들(AR, N-grams)은 한계가 뚜렷 \(\to\) 순환신경망의 등장
8. 겹장(덧장)
“1리터에 500만원에 낙찰된 적 있습니다.”
“2kg에 1억원 정도 추산됩니다.”
“20여 종 종자장을 블렌딩해 100ml에 5000만원씩 분양 예정입니다.”
모두 씨간장(종자장) 가격에 관한 실제 일화다.
(중략...)
위스키나 와인처럼 블렌딩을 하기도 한다.
새로 담근 간장에 씨간장을 넣거나, 씨간장독에 햇간장을 넣어 맛을 유지하기도 한다.
이를 겹장(또는 덧장)이라 한다.
몇몇 종갓집에선 씨간장 잇기를 몇백 년째 해오고 있다.
매년 새로 간장을 담가야 이어갈 수 있으니 불씨 꺼트리지 않는 것처럼 굉장히 어려운 일이다.
이렇게 하는 이유는 집집마다 내려오는 고유 장맛을 잃지 않기 위함이다.
씨간장이란 그만큼 소중한 주방의 자산이며 정체성이다.덧장: 새로운간장을 만들때, 옛날간장을 섞어서 만듦