import torch
import pandas as pd
import matplotlib.pyplot as plt12wk-2: 순환신경망 (3) – RNN, LSTM
![]()
1. 강의영상
2. Import
soft = torch.nn.Softmax(dim=1)3. AbAcAd – RNN + GPU
A. Data
- 데이터 정리
txt = list('AbAcAd'*50)
txt[:10]['A', 'b', 'A', 'c', 'A', 'd', 'A', 'b', 'A', 'c']df_train = pd.DataFrame({'x':txt[:-1], 'y':txt[1:]})
df_train[:5]| x | y | |
|---|---|---|
| 0 | A | b |
| 1 | b | A |
| 2 | A | c |
| 3 | c | A |
| 4 | A | d |
B. 구현1 – RNNCell (지난시간)
ref: https://pytorch.org/docs/stable/generated/torch.nn.RNNCell.html
- 데이터정리
x = torch.tensor(df_train.x.map({'A':0,'b':1,'c':2,'d':3}))
y = torch.tensor(df_train.y.map({'A':0,'b':1,'c':2,'d':3}))
X = torch.nn.functional.one_hot(x).float()
y = torch.nn.functional.one_hot(y).float()- Net설계 및 가중치 설정 (구현1과 동일하도록 가중치 초기화)
torch.manual_seed(4) # 이거를 고정해야함
rnncell = torch.nn.RNNCell(4,2)
cook = torch.nn.Linear(2,4)- 손실함수 및 옵티마이저 설정
loss_fn = torch.nn.CrossEntropyLoss()
optimizr = torch.optim.Adam(list(rnncell.parameters())+list(cook.parameters()),lr=0.1)L = len(X)
for epoc in range(200):
## 1~2
loss = 0
ht = torch.zeros(2) # 첫 간장은 맹물
for t in range(L):
Xt,yt = X[t],y[t]
ht = rnncell(Xt,ht)
ot = cook(ht)
loss = loss + loss_fn(ot,yt)
loss = loss/L
## 3
loss.backward()
## 4
optimizr.step()
optimizr.zero_grad()h = torch.zeros(L,2)
water = torch.zeros(2)
h[0] = rnncell(X[0],water)
for t in range(1,L):
h[t] = rnncell(X[t],h[t-1])
yhat = soft(cook(h))
yhattensor([[2.1032e-03, 7.4842e-01, 2.4849e-01, 9.8890e-04],
[9.9601e-01, 6.1446e-05, 3.9266e-03, 2.8410e-09],
[5.0120e-05, 2.2370e-02, 9.7758e-01, 2.4300e-07],
...,
[5.0229e-05, 2.2415e-02, 9.7753e-01, 2.4398e-07],
[9.9858e-01, 9.3154e-05, 1.3903e-08, 1.3301e-03],
[2.2350e-05, 1.9198e-02, 1.1779e-07, 9.8078e-01]],
grad_fn=<SoftmaxBackward0>)mat = torch.concat([h,yhat],axis=1).data[:10]
plt.matshow(mat,cmap='bwr',vmin=-1,vmax=1)
plt.axvline(x=1.5,color='lime')
plt.xticks(range(6),[r'$h_1$',r'$h_2$',r'$P_A$',r'$P_b$',r'$P_c$',r'$P_d$']);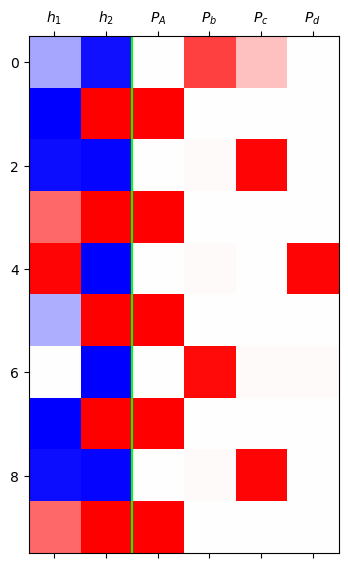
C. 구현2 – RNN
ref: https://pytorch.org/docs/stable/generated/torch.nn.RNN.html
x = torch.tensor(df_train.x.map({'A':0,'b':1,'c':2,'d':3}))
y = torch.tensor(df_train.y.map({'A':0,'b':1,'c':2,'d':3}))
X = torch.nn.functional.one_hot(x).float()
y = torch.nn.functional.one_hot(y).float()torch.manual_seed(4)
rnncell = torch.nn.RNNCell(4,2)
cook = torch.nn.Linear(2,4)rnn = torch.nn.RNN(4,2)
rnn.weight_ih_l0.data = rnncell.weight_ih.data
rnn.bias_ih_l0.data = rnncell.bias_ih.data
rnn.weight_hh_l0.data = rnncell.weight_hh.data
rnn.bias_hh_l0.data = rnncell.bias_hh.dataloss_fn = torch.nn.CrossEntropyLoss()
optimizr = torch.optim.Adam(list(rnn.parameters())+list(cook.parameters()),lr=0.1)Water = torch.zeros(1,2) # 첫 간장은 맹물
for epoc in range(200):
## 1
h,hL = rnn(X,Water)
netout = cook(h)
## 2
loss = loss_fn(netout, y)
## 3
loss.backward()
## 4
optimizr.step()
optimizr.zero_grad()h,_ = rnn(X,Water)
yhat = soft(cook(h))
yhattensor([[2.1032e-03, 7.4842e-01, 2.4849e-01, 9.8888e-04],
[9.9601e-01, 6.1446e-05, 3.9266e-03, 2.8410e-09],
[5.0120e-05, 2.2370e-02, 9.7758e-01, 2.4300e-07],
...,
[5.0229e-05, 2.2415e-02, 9.7753e-01, 2.4399e-07],
[9.9858e-01, 9.3154e-05, 1.3902e-08, 1.3302e-03],
[2.2350e-05, 1.9198e-02, 1.1779e-07, 9.8078e-01]],
grad_fn=<SoftmaxBackward0>)mat = torch.concat([h,yhat],axis=1).data[:10]
plt.matshow(mat,cmap='bwr',vmin=-1,vmax=1)
plt.axvline(x=1.5,color='lime')
plt.xticks(range(6),[r'$h_1$',r'$h_2$',r'$P_A$',r'$P_b$',r'$P_c$',r'$P_d$']);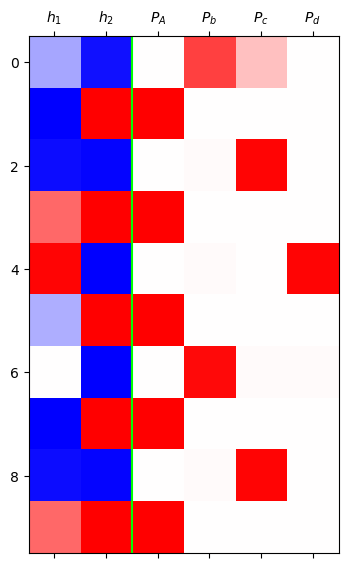
D. 구현3 – RNN + GPU
x = torch.tensor(df_train.x.map({'A':0,'b':1,'c':2,'d':3}))
y = torch.tensor(df_train.y.map({'A':0,'b':1,'c':2,'d':3}))
X = torch.nn.functional.one_hot(x).float()
y = torch.nn.functional.one_hot(y).float()torch.manual_seed(4)
rnncell = torch.nn.RNNCell(4,2)
cook = torch.nn.Linear(2,4)rnn = torch.nn.RNN(4,2)
rnn.weight_ih_l0.data = rnncell.weight_ih.data
rnn.bias_ih_l0.data = rnncell.bias_ih.data
rnn.weight_hh_l0.data = rnncell.weight_hh.data
rnn.bias_hh_l0.data = rnncell.bias_hh.dataloss_fn = torch.nn.CrossEntropyLoss()
optimizr = torch.optim.Adam(list(rnn.parameters())+list(cook.parameters()),lr=0.1)X = X.to("cuda:0")
y = y.to("cuda:0")
rnn.to("cuda:0")
cook.to("cuda:0")
Water = torch.zeros(1,2).to("cuda:0")
for epoc in range(200):
## 1
h,hL = rnn(X,Water)
netout = cook(h)
## 2
loss = loss_fn(netout,y)
## 3
loss.backward()
## 4
optimizr.step()
optimizr.zero_grad()h,hL = rnn(X,Water)
netout = cook(h)
yhat = soft(netout)
yhattensor([[2.1034e-03, 7.4850e-01, 2.4841e-01, 9.8938e-04],
[9.9601e-01, 6.1439e-05, 3.9265e-03, 2.8412e-09],
[5.0124e-05, 2.2368e-02, 9.7758e-01, 2.4295e-07],
...,
[5.0233e-05, 2.2413e-02, 9.7754e-01, 2.4393e-07],
[9.9858e-01, 9.3186e-05, 1.3921e-08, 1.3297e-03],
[2.2340e-05, 1.9198e-02, 1.1779e-07, 9.8078e-01]], device='cuda:0',
grad_fn=<SoftmaxBackward0>)- 살짝결과다름
mat = torch.concat([h,yhat],axis=1).data[:10].to("cpu")
plt.matshow(mat,cmap='bwr',vmin=-1,vmax=1)
plt.axvline(x=1.5,color='lime')
plt.xticks(range(6),[r'$h_1$',r'$h_2$',r'$P_A$',r'$P_b$',r'$P_c$',r'$P_d$']);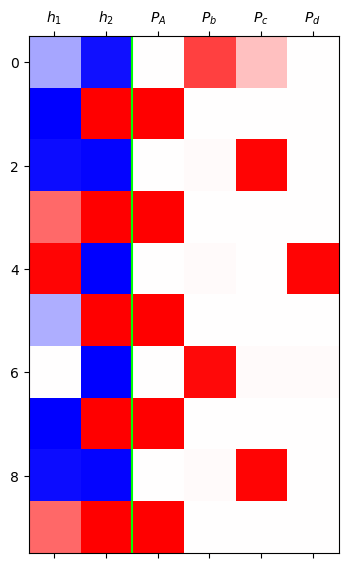
E. 구현4 – RNN + GPU + 맹물X
x = torch.tensor(df_train.x.map({'A':0,'b':1,'c':2,'d':3}))
y = torch.tensor(df_train.y.map({'A':0,'b':1,'c':2,'d':3}))
X = torch.nn.functional.one_hot(x).float()
y = torch.nn.functional.one_hot(y).float()torch.manual_seed(4)
rnncell = torch.nn.RNNCell(4,2)
cook = torch.nn.Linear(2,4)rnn = torch.nn.RNN(4,2)
rnn.weight_ih_l0.data = rnncell.weight_ih.data
rnn.bias_ih_l0.data = rnncell.bias_ih.data
rnn.weight_hh_l0.data = rnncell.weight_hh.data
rnn.bias_hh_l0.data = rnncell.bias_hh.dataloss_fn = torch.nn.CrossEntropyLoss()
optimizr = torch.optim.Adam(list(rnn.parameters())+list(cook.parameters()),lr=0.1)X = X.to("cuda:0")
y = y.to("cuda:0")
rnn.to("cuda:0")
cook.to("cuda:0")
Water = torch.zeros(1,2).to("cuda:0")
for epoc in range(200):
## 1
h,_ = rnn(X)
netout = cook(h)
## 2
loss = loss_fn(netout,y)
## 3
loss.backward()
## 4
optimizr.step()
optimizr.zero_grad()h,_ = rnn(X)
netout = cook(h)
yhat = soft(netout)
yhattensor([[2.1034e-03, 7.4850e-01, 2.4841e-01, 9.8938e-04],
[9.9601e-01, 6.1439e-05, 3.9265e-03, 2.8412e-09],
[5.0124e-05, 2.2368e-02, 9.7758e-01, 2.4295e-07],
...,
[5.0233e-05, 2.2413e-02, 9.7754e-01, 2.4393e-07],
[9.9858e-01, 9.3186e-05, 1.3921e-08, 1.3297e-03],
[2.2340e-05, 1.9198e-02, 1.1779e-07, 9.8078e-01]], device='cuda:0',
grad_fn=<SoftmaxBackward0>)mat = torch.concat([h,yhat],axis=1).data[:10].to("cpu")
plt.matshow(mat,cmap='bwr',vmin=-1,vmax=1)
plt.axvline(x=1.5,color='lime')
plt.xticks(range(6),[r'$h_1$',r'$h_2$',r'$P_A$',r'$P_b$',r'$P_c$',r'$P_d$']);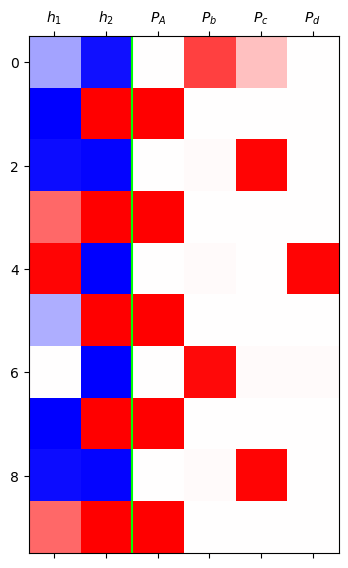
F. 은닉노드 비교실험
x = torch.tensor(df_train.x.map({'A':0,'b':1,'c':2,'d':3}))
y = torch.tensor(df_train.y.map({'A':0,'b':1,'c':2,'d':3}))
X = torch.nn.functional.one_hot(x).float().to("cuda:0")
y = torch.nn.functional.one_hot(y).float().to("cuda:0")
fig,ax = plt.subplots(5,5,figsize=(10,10))
for i in range(5):
for j in range(5):
rnn = torch.nn.RNN(4,2).to("cuda:0")
cook = torch.nn.Linear(2,4).to("cuda:0")
loss_fn = torch.nn.CrossEntropyLoss()
optimizr = torch.optim.Adam(list(rnn.parameters()) + list(cook.parameters()), lr=0.1)
for epoc in range(200):
## 1
h,_ = rnn(X)
netout = cook(h)
## 2
loss = loss_fn(netout,y)
## 3
loss.backward()
## 4
optimizr.step()
optimizr.zero_grad()
h = rnn(X)[0].data.to("cpu")
yhat = soft(cook(rnn(X)[0])).data.to("cpu")
mat = torch.concat([h,yhat],axis=1)[:8]
ax[i][j].matshow(mat,cmap="bwr")
ax[i][j].axvline(x=1.5,color="lime")
ax[i][j].set_xticks(range(6),[r'$h_1$',r'$h_2$',r'$P_A$',r'$P_b$',r'$P_c$',r'$P_d$'])
fig.suptitle("RNN -- # of hidden nodes = 2",size=20)
fig.tight_layout()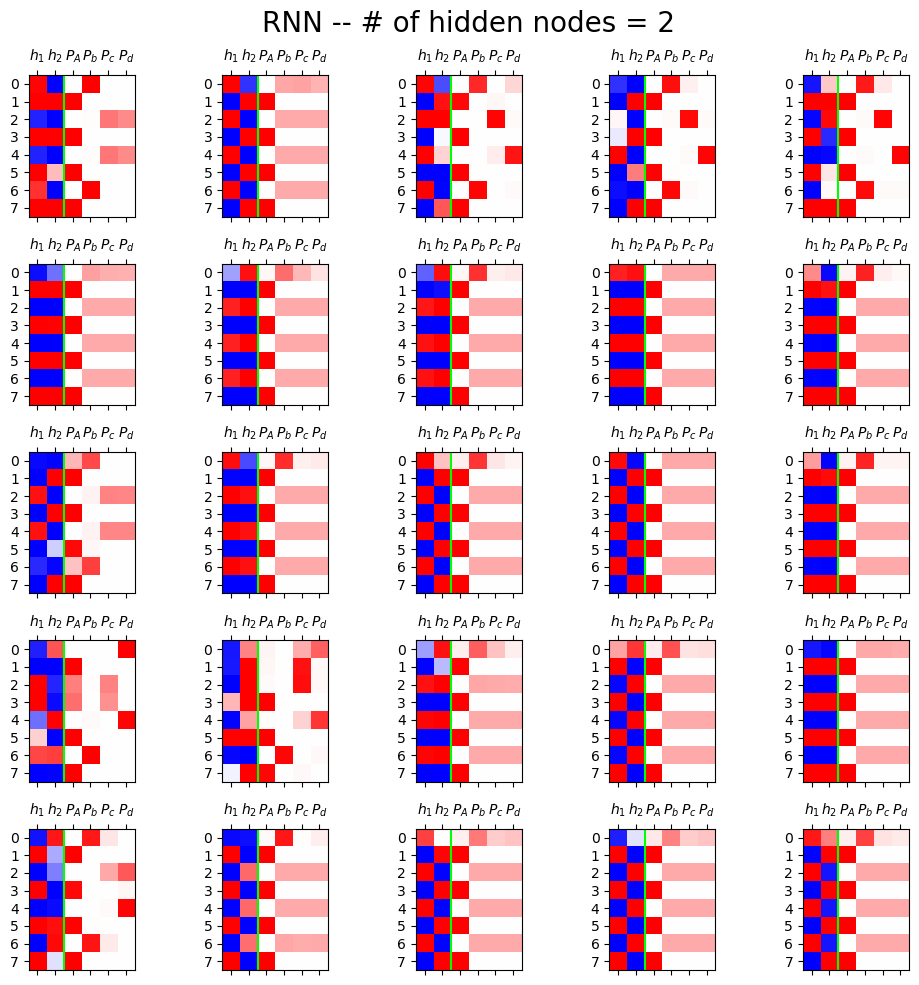
x = torch.tensor(df_train.x.map({'A':0,'b':1,'c':2,'d':3}))
y = torch.tensor(df_train.y.map({'A':0,'b':1,'c':2,'d':3}))
X = torch.nn.functional.one_hot(x).float().to("cuda:0")
y = torch.nn.functional.one_hot(y).float().to("cuda:0")
fig,ax = plt.subplots(5,5,figsize=(10,10))
for i in range(5):
for j in range(5):
rnn = torch.nn.RNN(4,3).to("cuda:0")
cook = torch.nn.Linear(3,4).to("cuda:0")
loss_fn = torch.nn.CrossEntropyLoss()
optimizr = torch.optim.Adam(list(rnn.parameters()) + list(cook.parameters()), lr=0.1)
for epoc in range(200):
## 1
h,_ = rnn(X)
netout = cook(h)
## 2
loss = loss_fn(netout,y)
## 3
loss.backward()
## 4
optimizr.step()
optimizr.zero_grad()
h = rnn(X)[0].data.to("cpu")
yhat = soft(cook(rnn(X)[0])).data.to("cpu")
mat = torch.concat([h,yhat],axis=1)[:8]
ax[i][j].matshow(mat,cmap="bwr")
ax[i][j].axvline(x=2.5,color="lime")
ax[i][j].set_xticks(range(7),[r'$h_1$',r'$h_2$',r'$h_3$',r'$P_A$',r'$P_b$',r'$P_c$',r'$P_d$'])
fig.suptitle("RNN -- # of hidden nodes = 3",size=20)
fig.tight_layout()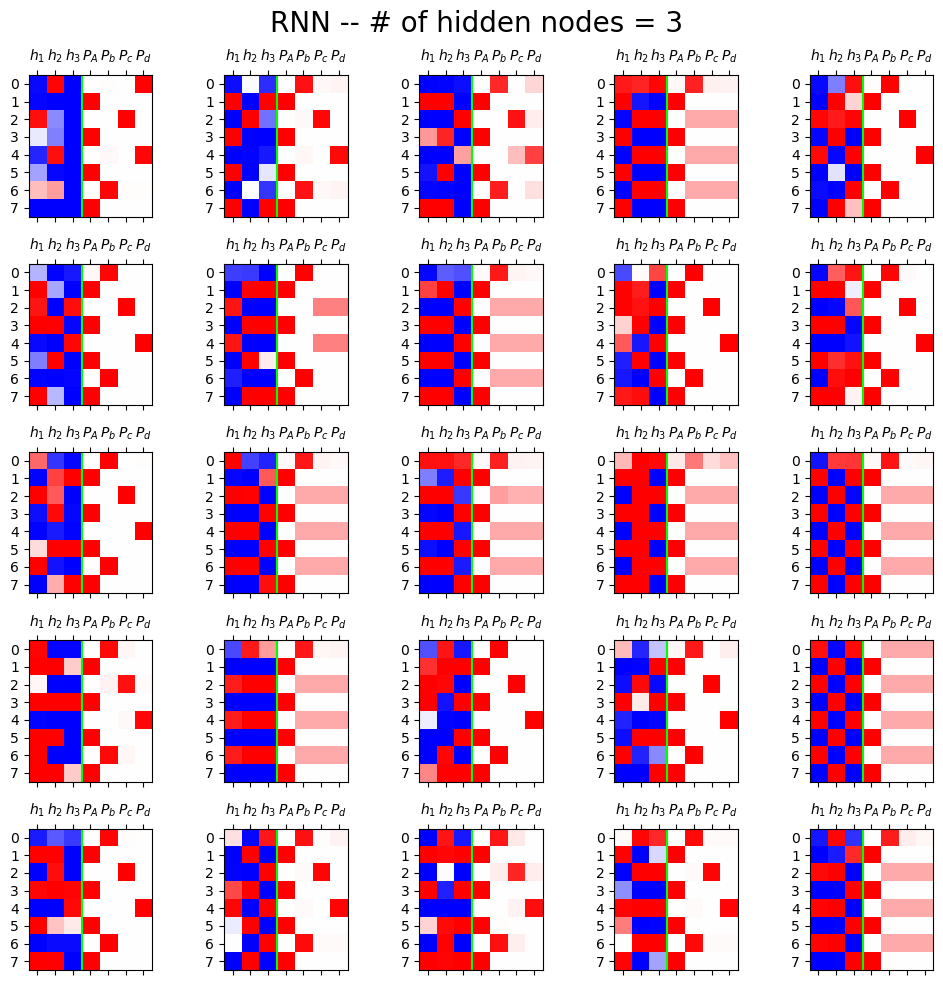
x = torch.tensor(df_train.x.map({'A':0,'b':1,'c':2,'d':3}))
y = torch.tensor(df_train.y.map({'A':0,'b':1,'c':2,'d':3}))
X = torch.nn.functional.one_hot(x).float().to("cuda:0")
y = torch.nn.functional.one_hot(y).float().to("cuda:0")
fig,ax = plt.subplots(5,5,figsize=(10,10))
for i in range(5):
for j in range(5):
rnn = torch.nn.RNN(4,4).to("cuda:0")
cook = torch.nn.Linear(4,4).to("cuda:0")
loss_fn = torch.nn.CrossEntropyLoss()
optimizr = torch.optim.Adam(list(rnn.parameters()) + list(cook.parameters()), lr=0.1)
for epoc in range(200):
## 1
h,_ = rnn(X)
netout = cook(h)
## 2
loss = loss_fn(netout,y)
## 3
loss.backward()
## 4
optimizr.step()
optimizr.zero_grad()
h = rnn(X)[0].data.to("cpu")
yhat = soft(cook(rnn(X)[0])).data.to("cpu")
mat = torch.concat([h,yhat],axis=1)[:8]
ax[i][j].matshow(mat,cmap="bwr")
ax[i][j].axvline(x=3.5,color="lime")
ax[i][j].set_xticks(range(8),[r'$h_1$',r'$h_2$',r'$h_3$',r'$h_4$',r'$P_A$',r'$P_b$',r'$P_c$',r'$P_d$'])
fig.suptitle("RNN -- # of hidden nodes = 4",size=20)
fig.tight_layout()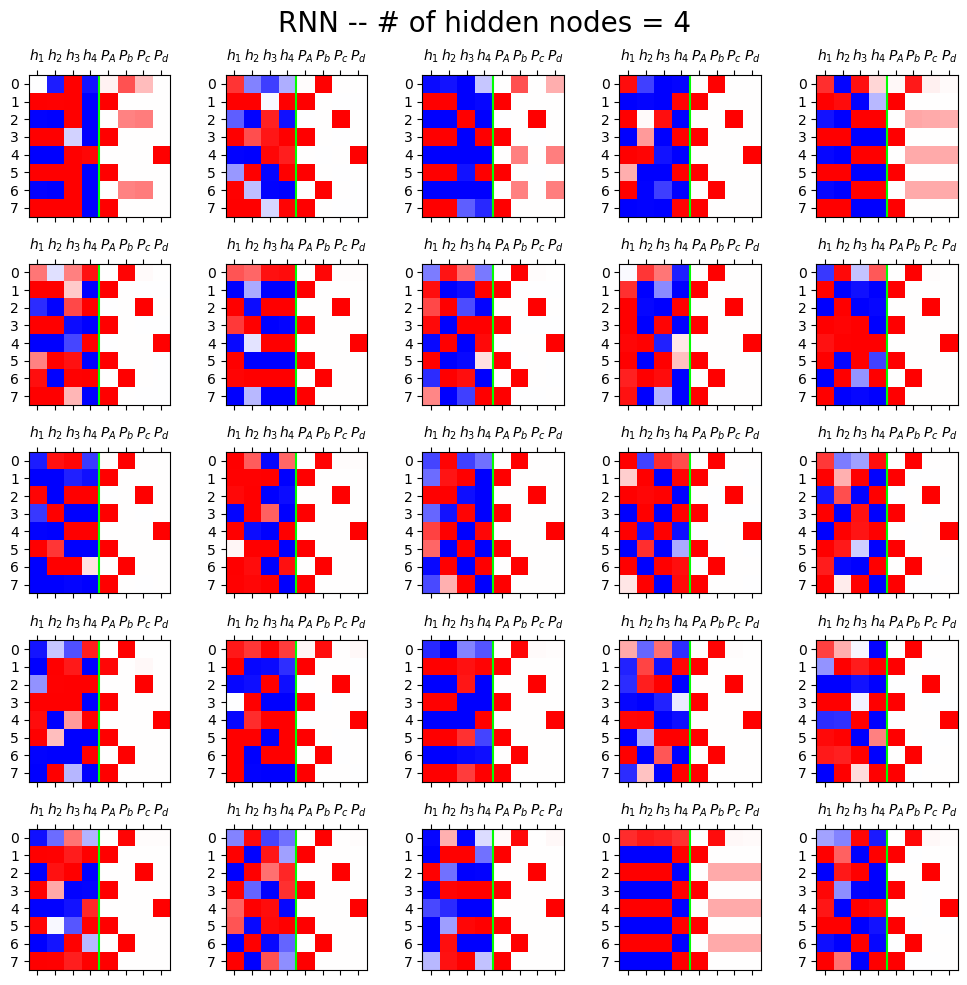
4. abcabC
A. Data
- 데이터 정리
txt = list('abcabC'*50)
txt[:10]['a', 'b', 'c', 'a', 'b', 'C', 'a', 'b', 'c', 'a']df_train = pd.DataFrame({'x':txt[:-1], 'y':txt[1:]})
df_train[:5]| x | y | |
|---|---|---|
| 0 | a | b |
| 1 | b | c |
| 2 | c | a |
| 3 | a | b |
| 4 | b | C |
B. RNN
ref: https://pytorch.org/docs/stable/generated/torch.nn.RNNCell.html
x = torch.tensor(df_train.x.map({'a':0,'b':1,'c':2,'C':3}))
y = torch.tensor(df_train.y.map({'a':0,'b':1,'c':2,'C':3}))
X = torch.nn.functional.one_hot(x).float().to("cuda:0")
y = torch.nn.functional.one_hot(y).float().to("cuda:0")
fig,ax = plt.subplots(5,5,figsize=(10,10))
for i in range(5):
for j in range(5):
rnn = torch.nn.RNN(4,4).to("cuda:0")
cook = torch.nn.Linear(4,4).to("cuda:0")
loss_fn = torch.nn.CrossEntropyLoss()
optimizr = torch.optim.Adam(list(rnn.parameters()) + list(cook.parameters()), lr=0.1)
for epoc in range(500):
## 1
h,_ = rnn(X)
netout = cook(h)
## 2
loss = loss_fn(netout,y)
## 3
loss.backward()
## 4
optimizr.step()
optimizr.zero_grad()
h = rnn(X)[0].data.to("cpu")
yhat = soft(cook(rnn(X)[0])).data.to("cpu")
mat = torch.concat([h,yhat],axis=1)[:8]
ax[i][j].matshow(mat,cmap="bwr")
ax[i][j].axvline(x=3.5,color="lime")
ax[i][j].set_xticks(range(8),[r'$h_1$',r'$h_2$',r'$h_3$',r'$h_4$',r'$P_a$',r'$P_b$',r'$P_c$',r'$P_C$'])
fig.suptitle("RNN -- # of hidden nodes = 4",size=20)
fig.tight_layout()
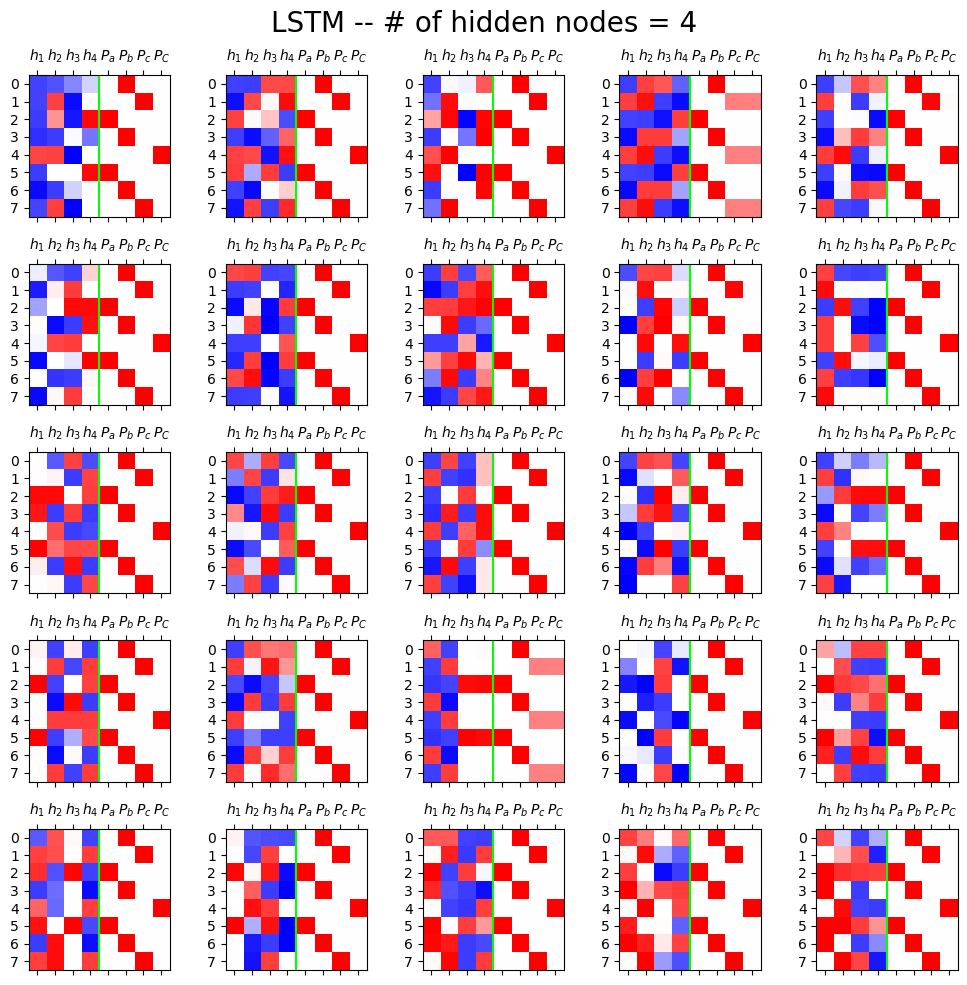
C. LSTM
x = torch.tensor(df_train.x.map({'a':0,'b':1,'c':2,'C':3}))
y = torch.tensor(df_train.y.map({'a':0,'b':1,'c':2,'C':3}))
X = torch.nn.functional.one_hot(x).float().to("cuda:0")
y = torch.nn.functional.one_hot(y).float().to("cuda:0")
fig,ax = plt.subplots(5,5,figsize=(10,10))
for i in range(5):
for j in range(5):
lstm = torch.nn.LSTM(4,4).to("cuda:0")
cook = torch.nn.Linear(4,4).to("cuda:0")
loss_fn = torch.nn.CrossEntropyLoss()
optimizr = torch.optim.Adam(list(lstm.parameters()) + list(cook.parameters()), lr=0.1)
for epoc in range(500):
## 1
h,_ = lstm(X)
netout = cook(h)
## 2
loss = loss_fn(netout,y)
## 3
loss.backward()
## 4
optimizr.step()
optimizr.zero_grad()
h = lstm(X)[0].data.to("cpu")
yhat = soft(cook(lstm(X)[0])).data.to("cpu")
mat = torch.concat([h,yhat],axis=1)[:8]
ax[i][j].matshow(mat,cmap="bwr",vmin=-1,vmax=1)
ax[i][j].axvline(x=3.5,color="lime")
ax[i][j].set_xticks(range(8),[r'$h_1$',r'$h_2$',r'$h_3$',r'$h_4$',r'$P_a$',r'$P_b$',r'$P_c$',r'$P_C$'])
fig.suptitle("LSTM -- # of hidden nodes = 4",size=20)
fig.tight_layout()